
1:Hive 和数据库的区别
- 数据存储位置
- 查询语言
- 索引
- 数据格式
- 执行
- 数据更新
- 延迟
- 可扩展性
- 数据规模
- 硬件要求
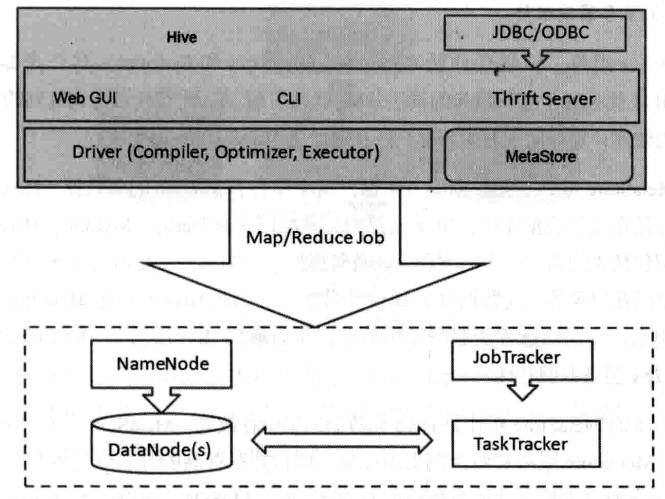
2:Hive 体系的组成
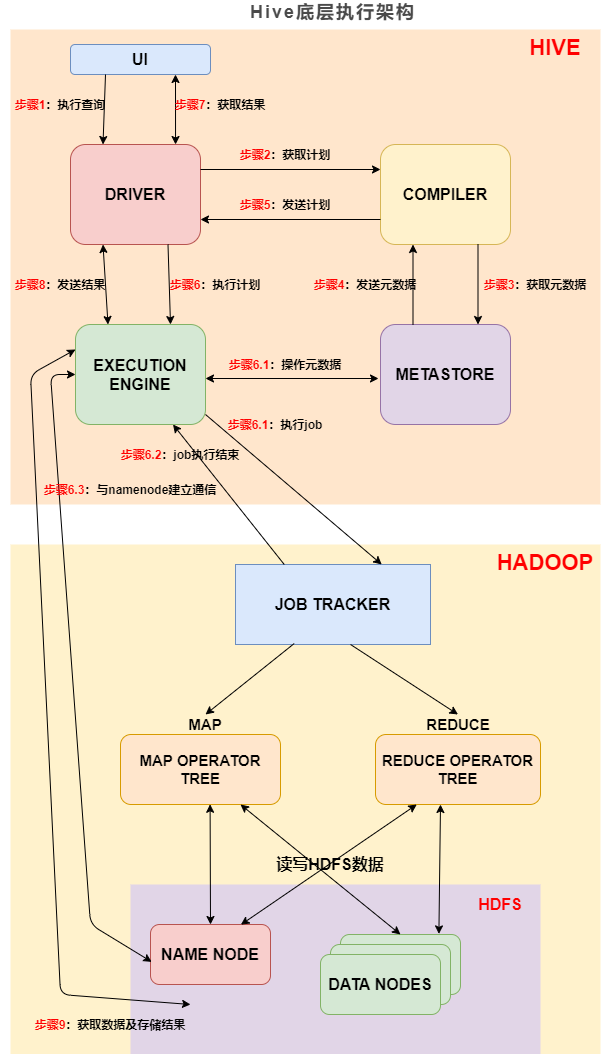
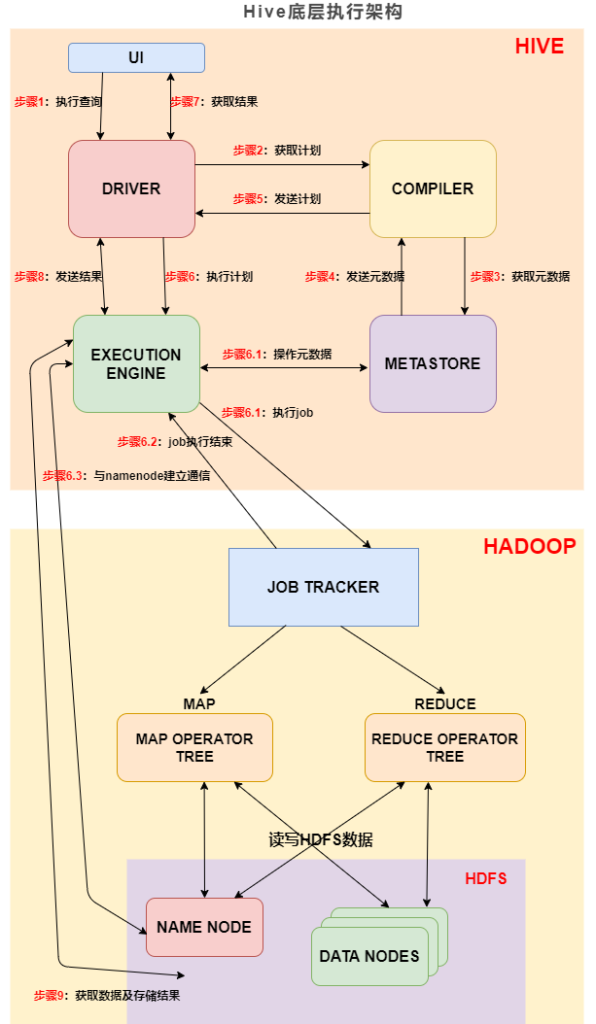
3:Hive底层执行架构
4:基本语法
查看数据库
—-【1】查看数据库列表 show databases;
—-【2】使用 like 关键字模糊匹配,显示包含 db_前缀的数据库名称 show databases like ‘db_*’;
使用数据库
—-【1】切换到指定库 use db 名称;
创建数据库
—-【1】创建数据库 create database dbname;
—-【2】通过 location 指定数据库路径 create database dbname location ‘path 路径’;
—-【3】给数据库添加描述信息 create database dbname comment ‘dbname 描述信息’;
删除数据库
—-【1】删除数据库,这种删除,需要将数据库中的表全部删除,才能删除数据库
drop database dbname; 或者 drop database if exists dbname;
—-【2】强制删除数据库 drop database dbname cascade;
查看数据库的详细描述
—-【1】查看数据库描述 desc database dbname;
数据库键值对信息
数据库可以有一些描述性的键值对信息,在创建时添加
—-【1】创建带键值对的数据库
create database foo with dbproperties (‘own’=’cc’, ‘day’=’20180120’);
—-【2】查看数据库的键值对信息
describe database extended foo;
—-【3】要修改数据库的键值对信息
alter database foo set dbproperties (‘k1’=’v1’, ‘k2’=’v2’);
数据表操作
显示数据库中的表
—-【1】显示表清单 show tables;
—-【2】使用 like 模糊匹配,查询包含 tb_前缀的表 show tables like ‘test*’; 或者 Show tables ‘test*’;
显示表的分区
—-【1】显示表分区 show partitions tb_test;
显示表的详细信息
—-【1】显示表分区
desc tb_name;
describe tb_name;
创建内部表/外部表/分区表/分桶表 —-【1】建表语法
create [external] table [if not exists] table_name (
col_name data_type [comment '字段描述信息']
col_name data_type [comment '字段描述信息'])
[comment '表的描述信息']
[location '指定表的路径']
[partitioned by (col_name data_type,...)]
[clustered by (col_name,col_name,...)]
[sorted by (col_name [asc|desc],...) into num_buckets buckets]
[row format row_format]
[location location_path]–【2】简单的表创建
create table tb_test(name string, age int);
–【3】指定字段分隔符
create table tb_test(name string,age int) row format delimited fields terminated by ‘,’;
–【4】创建外部表
create external table tb_test(name string,age int) row format delimited fields terminated by ‘,’;
–【5】创建分区表
CREATE TABLE test_part (
customer_id string comment '订单数据集的主键。每个订单都有一个唯一的customer_id',
customer_unique_id string comment '客户的唯一标识符',
customer_zip_code_prefix string comment '客户邮政编码的前五位数字',
customer_city string comment '客户城市名称'
) comment '客户及其位置的信息'
PARTITIONED BY (customer_state string)
row format delimited
fields terminated by ','
stored as orc; –【6】创建表,指定 location
create table tb_location(name string,age int)
row format delimited fields terminated by ‘,’ location ‘hdfs://ds-nameservice1/tmp/tb_location’;
–【7】创建带桶的表
CREATE TABLE test_part_bucket (
customer_id string comment '订单数据集的主键。每个订单都有一个唯一的customer_id',
customer_unique_id string comment '客户的唯一标识符',
customer_zip_code_prefix string comment '客户邮政编码的前五位数字',
customer_city string comment '客户城市名称'
) comment '客户及其位置的信息'
PARTITIONED BY (customer_state string)
clustered by (customer_city) sorted by (customer_id asc ) into 4 buckets
row format delimited
fields terminated by ','
stored as orc; 其他建表操作
—-【1】由一个表创建另一个表
create table test1 like olist_customers_dataset;
—-【2】从其他表查询创建表
create table test1 as select user_id, user_name from test_part_student;
删除表
—-【1】删除表操作
drop table tb_name;
drop table if exists tb_name;
修改表分区/列/表名
—-【1】添加分区:按照 sex=’male’,sex=’female’进行分区
alter table student add partition(sex=’male’) partition(sex=’female’);
—-【2】删除分区
alter table student drop partition(sex=’male’);
—-【3】增加列
alter table student add columns (rank string);
或者
alter table student replace columns (height string);
—-【4】修改表的字段顺序
alter table test_table change column c c string after a;
—-【5】修改表的名字
alter table test_table rename to new_test_table;
内部表与外部表的切换
—-【1】内部表转外部表
alter table xm_testA set TBLPROPERTIES (“EXTERNAL”=”TRUE”)
—-【2】外部表转换内部表
alter table xm_testB set TBLPROPTIES (“EXTERNAL”=”FALSE”)
静态分区、动态分区
静态分区是手动指定,而动态分区是 通过数据来进行判断
单级分区、多级分区
(1)单分区建表语句:
create table day_table (id int, content string) partitioned by (dt string);
单分区表,按天分区,在表结构中存在 id,content,dt 三列。
(2)双分区建表语句:
create table day_hour_table (id int, content string) partitioned by (dt string, hour string);
双分区表,按天和小时分区,在表结构中新增加了 dt 和 hour 两列
查看分区: show partitions student_part;
–更改分区文件存储格式
ALTER TABLE table_name PARTITION (dt=’2021-08-09′) SET FILEFORMAT file_format;
–更改分区位置
ALTER TABLE table_name PARTITION (dt=’2021-08-09′) SET LOCATION “new location”;
修复分区
MSCK [REPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];
启用 hive 动态分区
启用 hive 动态分区,只需要在 hive 会话中设置两个参数:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
动态分区不允许主分区采用动态列而副分区采用静态列,这样将导致 所有的主分区都要创建副分区静态列所定义的分区(主副分区都应该是动态的)
分区设置注意事项
当分区过多且数据很大时,可以使用严格模式,避免触发一个大的 mapreduce 任务
hive 如果有过多的分区,由于底层是存储在 HDFS 上,HDFS 上只用于存储大文件而非小文件,因为过多的分区会增加 namenode 的负担
hive 会转化为 mapreduce,mapreduce 会转化为多个 task。过多小文件的话, 每个文件一个 task,每个 task 一个 JVM 实例,JVM 的开启与销毁会降低系统效率。
合理的分区不应该有过多的分区和文件目录,并且每个目录下的文件应该足够大。如果用户不能够找到好的、大小相对合适的分区方式的话,那么可以考虑使用分桶存储
分桶表
数据分桶的原理: 与 MR 中的 HashPartitioner 的原理一模一样,MR 中按照 key 的 hash 值去模除以 reductTask 的个数;Hive 中按照分桶字段的 hash 值去模除以 分桶的个数。
默认规则是:Bucket 编号= hash_function(分桶字段) mod 分桶数量。桶编号相同的数据会 被分到同一个桶。hash_function 取决于分桶字段的类型: 字段是 int 类型,hash_function(int) == int; 字段是其他类型,比如 bigint,string 或者复杂数据类型,hash_function 从该类型 派生的某个数字,比如 hashcode 值来进行分桶。
数据分桶的作用
(1)获得更高的查询效率:全表查询或分区查询转换成桶查询。
(2)大表 join
对两张大表的连接字段分桶,此时的 join 是按照桶来的,一个桶一 个桶 join,这样就完美解决大表join的问题
两个表的分桶数量上必须是倍数关系。确保对于连接条件的一致性
要想在 map 端执行桶 join,必须设置 hive.optimize.bucketmapjoin= true。
抽样查询
传统抽样:select * from emp tablesample(10%);
这种抽样方式不一定适用于所有的文件格式。另外,这种抽样的最小 抽样单元是一个 HDFS 数据块。因此,如果表的数据大小小于普通的块大小 128M 的话,那么将会返回所有行
分桶抽样:select * from emp tablesample(bucket x out of y);
y 必须是 table 总 bucket 数的倍数或者因子。hive 根据 y 的大小,决定抽样 的比例。例如,table 总共分了 4 份(4 个 bucket),当 y=2 时,抽取(4/2=)2 个 bucket 的数据,当 y=8 时,抽取(4/8=)1/2 个 bucket 的数据。
x表示从哪个bucket开始抽取。例如,table总bucket数为4,tablesample(bucket 4 out of 4),表示总共抽取(4/4=)1 个 bucket 的数据,抽取第 4 个 bucket 的 数据。
x 的值必须小于等于 y 的值,否则会报错
创建桶表
CLUSTERED BY (col_name)表示根据哪个字段进行分 INTO N BUCKETS 表示分为几桶
##通用格式
CREATE [EXTERNAL] TABLE [db_name.]table_name
[(col_name data_type, ...)]
CLUSTERED BY (col_name)
INTO N BUCKETS;
##建表实例
CREATE TABLE olist_customers_dataset_bucket (
customer_id string comment '订单数据集的主键。每个订单都有一个唯一的customer_id',
customer_unique_id string comment '客户的唯一标识符',
customer_zip_code_prefix string comment '客户邮政编码的前五位数字',
customer_city string comment '客户城市名称',
customer_state string comment '客户状态'
) comment '客户及其位置的信息'
clustered by (customer_city) sorted by (customer_id asc ) into 4 buckets
row format delimited
fields terminated by ','
stored as orc;
#####这儿和分区表不一样,分区表的分区字段不在建表字段中,而分桶字段在建表字段中。视图
Hive 中的视图(view)是一种虚拟表,只保存定义,不实际存储数据
视图是用来简化操作的,它其实是一张虚表,在视图中不缓冲记录,也没有提高查询性能
视图相关操作
—-【1】创建视图:
create view v_test as select customer_id,customer_city from olist_customers_dataset;
—-【2】查看视图定义:
show create table v_test;
—-【3】删除视图:
drop view v_test;
—-【4】更改视图定义:
alter view v_test as select customer_id,customer_city,customer_state from olist _customers_dataset;
DML 数据操作
基础查询操作
--基础表的表结构
CREATE TABLE student_part_msck (
user_id int comment '用户 id',
user_name string comment '用户姓名',
user_age int comment '用户年龄',
user_city string comment '城市名称',
user_city_person bigint comment '城市人口',
consume_amount decimal(20,2) comment '用户消费金额',
user_birthday date comment '用户出生年月',
user_year string comment '年份'
) comment '用户信息表'
PARTITIONED BY (sex string comment '性别')
row format delimited
fields terminated by '\t'
stored as textfile;
----【1】基础查询: 可设置别名
select user_name as name,user_age as age from student_part_msck
----【2】去重查询:包括单个字段、多个字段去重
select all user_city from student_part_msck; --返回所有值
select distinct user_city from student_part_msck; --返回所有去重后的值
select distinct user_city,user_year from student_part_msck; --多字段去重
----【3】分组统计:统计每个城市中每个年龄层的最高薪水、平均薪水
select t.user_city, t.user_year,max(t.consume_amount) max_val, avg(t.consume_amo
unt) avg_val from student_part_msck t group by t.user_city,t.user_year;
----【4】分组统计后按条件筛选: 统计男性的消费金额超过 3600 的城市,以及对应的消费总额
select user_city,sum(consume_amount) from student_part_msck where sex = 'male'
group by user_city having sum(consume_amount) > 3600;
----【5】统计所有城市、城市人口:
--结果去重
select user_city,user_city_person from student_part_msck where sex='male'
union
select user_city,user_city_person from student_part_msck where sex='female';
--结果不去重
select user_city,user_city_person from student_part_msck where sex='male'
union all
select user_city,user_city_person from student_part_msck where sex='female';
----【6】子查询:
select a.user_city,consume_amount from (select user_city,sum(consume_amount) as
consume_amount from student_part_msck where sex = 'male' group by user_city)
as a;
----【7】公用表表达式查询:
with a as (select user_city,sum(consume_amount) as consume_amount from student_p
art_msck where sex = 'male' group by user_city)
select * from a 四类排序操作
order by,sort by,distribute by,cluster by
1. order by
(1)全局排序;
(2)对输入的数据做排序,故此只有一个 reducer(多个 reducer 无法保证全局有序); 只有一个 reducer,会导致当输入规模较大时,需要较长的计算时间;
2. sort by
(1)非全局排序;
(2)在数据进入 reducer 前完成排序;
(3)当 mapred.reduce.tasks>1 时,只能保证每个 reducer 的输出有序,不保证全局 有序;
3. distribute by
(1)按照指定的字段对数据进行划分输出到不同的 reduce 中;后面不能跟 desc、 asc 排序;
(2)常和 sort by 一起使用,并且 distribute by 必须在 sort by 前面;
----【3】distribute by 示例
set mapred.reduce.tasks=2;
select * from student_part_msck distribute by user_year; 4. cluster by
(1)相当于 distribute by+sort by,只能默认升序,不能使用倒序;
----【4】distribute by 和 sort by 结合使用示例
select * from student_part_msck cluster by user_city;
等价于
select * from student_part_msck distribute by user_city sort by user_city;join 的类型与用法
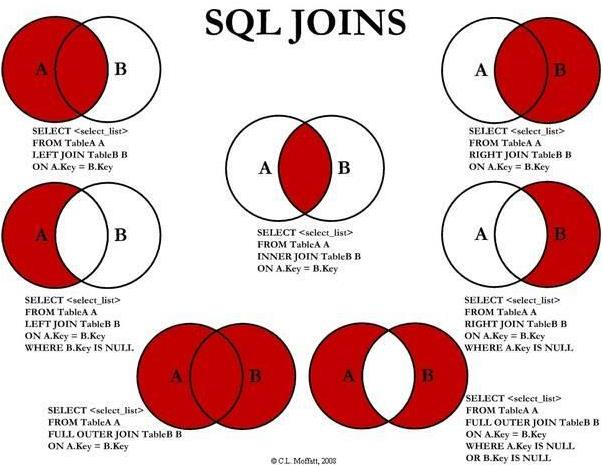
内连接[inner] join:
两个表中关联键相同的记录才会查询出来。通用写法:
select * from a inner join b on a.id=b.id;
外连接—左外连接 left [outer] join:
以左表为主表,右表中有的就会关联上,
右表中没有关联上的数据就用 null 补齐。通用写法:
select * from a left outer join b on a.id=b.id;
外连接—右外连接 right [outer] join:以右表为主表,左表有的则关联,没有则 null 补齐。通用写法:
select * from a right outer join b on a.id=b.id;
外连接—全外连接 full [outer] join:左表和右表中的并集,左表和右表中所有的数据都会关联上。通用写法:
select * from a full outer join b on a.id=b.id;
半连接—左半连接 left semi join:
mysql 中有一个语法 in/exists 用于判断字段是否在给定的值中。
select * from a left semi join b on a.id=b.id;
等价于
select * from a where id in/exists (select id from b)
左半连接:判断左表中的关联键是否在右表中存在,若存在,则返回左表的
存在的数据的相关字段,若不存在,则不返回。
笛卡尔积关联 cross join:返回两个表的笛卡尔积结果,不需要指定关联键。
除非特殊需求,并且数据量不是特别大的情况下,才可以慎用 CROSS JOIN,否则,
很难跑出正确的结果,或者 JOB 压根不能执行完。
select a.*,b.* from user_base_info as a cross join user_phone_info as b; Join 的原理和机制
Hive 中的 Join 可分为 Common Join(Reduce 阶段完成 join)和 Map Join(Map 阶段完成 join)、SMB(Sort-Merge-Buket) Join
1.Hive Common Join
在 Reduce 阶段完成 join。 整个过程包含 Map、Shuffle、Reduce 阶段。
(1)Map 阶段
Step1:
读取源表的数据,Map 输出时候以 Join on 条件中的列为 key,如果 Join 有多个关联键,则以这些关联键的组合作为 key;
Step2:
Map 输出的 value 为 join 之后所关心的(select 或者 where 中需要用到的) 列;同时在 value 中还会包含表的 Tag 信息,用于标明此 value 对应哪个表;
Step3:
按照 key 进行排序。
(2)Shuffle 阶段
根据 key 的值进行 hash,并将 key/value 按照 hash 值推送至不同的 reduce 中, 这样确保两个表中相同的 key 位于同一个 reduce 中。
(3)Reduce 阶段
根据 key 的值完成 join 操作,期间通过 Tag 来识别不同表中的数据
SELECT
a.id,a.dept,b.age
FROM a join b
ON (a.id = b.id); 
2. Hive Map Join
Map Join 通常用于一个很小的表和一个大表进行 join 的场景,具体小表有多 小,由参数 hive.mapjoin.smalltable.filesize 来决定,该参数表示小表的总大小,默 认值为 25000000 字节,即 25M
假设 a 表为一张大表,b 为小表,并且 hive.auto.convert.join=true, 那么 Hive 在执行时候会自动转化为 Map Join
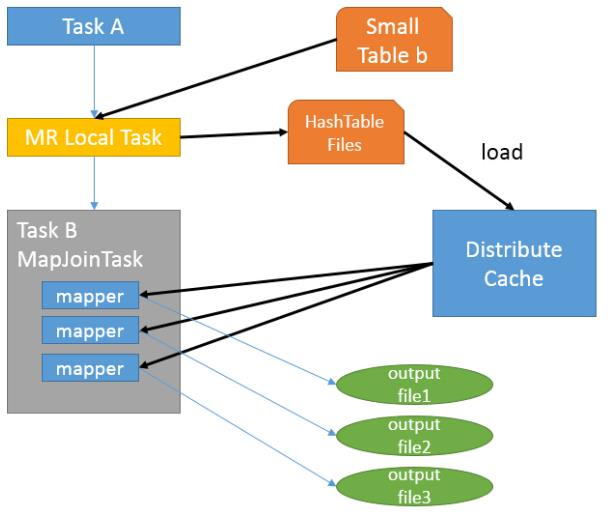
由于 Map Join 没有 Reduce,所以由 Map 直接输出结果文件,有多少个 Map Task,就有多少个结果文件。
使用限制:
- LEFT OUTER JOIN 的左表必须是大表
- RIGHT OUTER JOIN 的右表必须是大表
- INNER JOIN 左表或右表均可以作为大表
- FULL OUTER JOIN 不能使用 MAPJOIN
- 使用 MAPJOIN 时需要引用小表或是子查询时,需要引用别名
- 在 MAPJOIN 中,可以使用不等值连接或者使用 OR 连接多个条件
- 在 MAPJOIN 中最多支持指定 6 张小表,否则报语法错误
hint优化器方式指定小表的方式如下:
select /*+ MAPJOIN(time_dim) */ count(1) from
store_sales as a join time_dim as b on (a.ss_sold_time_sk = b.t_time_sk) 3. SMB(Sort-Merge-Buket) Join
大表关联大表时,在运行 SMB Join 的时候会重新创建两张表,当然这是在后台默认做的,不 需要用户主动去创建,如下所示:
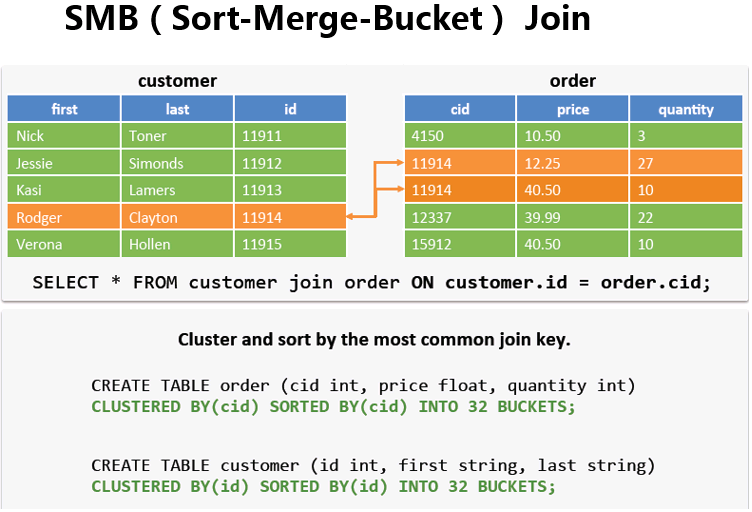
设置(默认是 false):
set hive.auto.convert.sortmerge.join=true
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true; 函数
1.常用内置函数
使用如下命令查看当前 hive 版本支持的所有内置函数。
使用如下命令查看当前 hive 版本支持的所有内置函数。
show functions;
显示函数的描述信息:
DESC FUNCTION concat;
显示函数的扩展描述信息:
DESC FUNCTION EXTENDED concat; 2.字符串函数
hive> select concat('abc','def','gh') ;
执行结果:abcdefgh
hive> select concat_ws(',abc','def','gh') ;
执行结果:def,abcgh
hive> select format_number(5.23456,3);
执行结果:5.235
hive> select substr('abcde',3);
执行结果:cde
hive>select substr('abcde',-1) ;(和 ORACLE 相同)
执行结果:e
hive> select instr('abcdf','df') ;
执行结果:4
hive> select str_to_map('k1:v1,k2:v2',',');
执行结果:{"k2":"v2","k1":"v1"}
hive> select upper('abSEd');
执行结果:ABSED
hive> select lower('abSEd') ;
执行结果:absed
hive> select regexp_replace('foobar','oo|ar','');
执行结果:fb
hive>select regexp_extract('foothebar','foo(.*?)(bar)',1);
执行结果:the
hive> select split('abtcdtef','t') ;
执行结果:["ab","cd","ef"] 3.日期函数
转化 UNIX 时间戳(从 1970-01-0100:00:00UTC 到指定时间的秒数)到当前时区的时间格式
hive> select from_unixtime(1323337489,'yyyyMMdd');
执行结果:20111208
获得当前时区的 UNIX 时间戳
hive> select unix_timestamp();
执行结果:1323309615
转换格式为"yyyy-MM-ddHH:mm:ss"的日期到 UNIX 时间戳。如果转化失败,则返回 null
hive>select unix_timestamp('2011-12-07 13:01:03');
执行结果:1323234063
转换 pattern 格式的日期到 UNIX 时间戳。如果转化失败,则返回 null
hive>select unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss');
执行结果:1323234063
返回日期时间字段中的日期部分
hive> select to_date('2021-12-23 10:03:01');
执行结果:2021-12-23
返回日期中的年。
hive> select year('2021-12-08 10:03:01');
执行结果:2021
返回日期中的月份
hive> select month('2011-12-08 10:03:01');
执行结果:12
返回日期中的天
hive>select day('2021-12-08 10:03:01');
执行结果:8
返回日期中的小时
hive> select hour('2021-12-08 10:03:01');
执行结果:10
返回日期中的分钟
hive> select minute('2021-12-08 10:03:01');
执行结果:3
返回日期中的秒
hive> select second('2021-12-08 10:03:01');
执行结果:1
返回日期在当前的周数
hive> select weekofyear('2021-12-08 10:03:01');
执行结果:49
返回结束日期减去开始日期的天数
hive> select datediff('2021-12-08','2021-12-01');
执行结果:7
返回开始日期 startdate 增加 days 天后的日期
hive> select date_add('2021-12-08',10);
执行结果:2021-12-18
返回开始日期 startdate 减少 days 天后的日期
hive> select date_sub('2021-12-08',10);
执行结果:2012-11-28 4. 数学函数
返回 double 类型的整数值部分(遵循四舍五入)
hive> select round(3.1415926);
执行结果:3
返回指定精度 d 的 double 类型
hive> select round(3.1415926,4);
执行结果:3.1416
返回数值 a 的绝对值
hive> select abs(-3.9);
执行结果:3.9
语法:positive(int a),positive(double a)
返回值:int double
说明:返回 a
hive> select positive(-10);
执行结果:-10
hive> select positive(12);
执行结果:12
语法:negative(int a),negative(double a)
返回值:int double
说明:返回-a
hive> select negative(-5);
执行结果:5
hive> select negative(8);
执行结果:-8 5.集合函数
hive> select size(map('k1','v1','k2','v2'));
执行结果:2
hive> select size(array(1,2,3,4,5));
执行结果:5
语法:array_contains(Array<T>,value)
返回值: boolean
返回 Array<T>中是否包含元素 value
hive> select array_contains(array(1,2,3,4,5),3);
执行结果:true
语法:map_values(Map<K,V>)
返回值:array<V>
返回 Map<K,V>中所有 value 的集合
hive>select map_values(map('k1','v1','k2','v2'));
执行结果:["v2","v1"] 6.条件函数
语法:if(boolean testCondition,T valueTrue,T valueFalseOrNull)
返回值:T
说明:当条件 testCondition 为 TRUE 时,返回 valueTrue;否则返回 valueFalseOrNull
hive> select if(1=2,100,200) ;
执行结果:200
语法:COALESCE(T v1,T v2,…)
返回值:T
返回参数中的第一个非空值:如果所有值都为 NULL,那么返回 NULL
hive> select COALESCE(null,'100',50);
执行结果:100
语法:CASE a WHEN b THEN c [WHEN d THEN e]*[ELSE f] END
返回值:T
hive> Select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
执行结果:mary 7.用户自定义函数
UDF(User-Defined-Function):用户自定义函数,一对一的输入输出。
UDAF(User-Defined Aggregation Funcation):用户自定义聚合函数,多进一出。
例如:count/max/min。
UDTF(User-Defined Table-Generating Functions):用户自定义表生成函数,一对
多的输入输出。例如:lateral view explode。- 【使用方式】:
- 在 HIVE 会话中 add 自定义函数的 jar 文件,然后创建 function 继 而使用函数。具体步骤如下:
- (1)编写自定义函数。
- (2)打包上传到集群机器中。
- (3)进入 hive 客户端,添加 jar 包:
- hive> add jar /home/ds_teacher/hive_udf.jar。
- (4)创建临时函数:
- hive> create temporary function getLen as ‘com.ds.GetLength’;
- (5) 使用临时函数: hive> select getLen(‘1234567’);
- (6)销毁临时函数:hive> drop temporary function getLen;
8.窗口函数
SQL 窗口查询引入了三个新的概念:窗口分区、窗口帧、以及窗口函数。
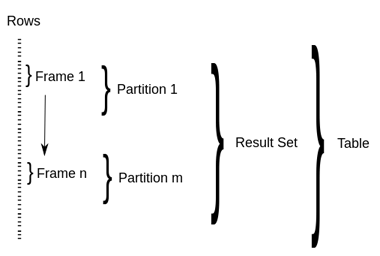
- (1)窗口分区:PARTITION 语句会按照一个或多个指定字段,将查询结果集 拆分到不同的窗口分区中,并可按照一定规则排序。如果没有 PARTITION BY,则 整个结果集将作为单个窗口分区;如果没有 ORDER BY,我们则无法定义窗口帧, 进而整个分区将作为单个窗口帧进行处理。
- (2)窗口帧:窗口帧用于从分区中选择指定的多条记录,供窗口函数处理。 Hive 提供了两种定义窗口帧的形式:ROWS 和 RANGE。两种类型都需要配置上 界和下界。例如:ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 表 示选择分区起始记录到当前记录的所有行
- 窗口函数:窗口函数会基于当前窗口帧的记录计算结果。Hive 提供了 以下窗口函数:
- NTILE(n),用于将分组数据按照顺序切分成 n 片,返回当前切片值; ROW_NUMBER()、RANK() 会为帧内的每一行返回一个序数,区别在于存在字 段值相等的记录时,RANK() 会返回相同的序数;
- LEAD(col, n), LAG(col, n) 返回当前记录的上 n 条或下 n 条记录的字段值;
- FIRST_VALUE(col), LAST_VALUE(col) 可以返回窗口帧中第一条或最后一条记录的指定字段值;
- COUNT(), SUM(col), MIN(col) 和一般的聚合操作相同。
窗口函数表达式
窗口函数的语法分为四个部分:
(1)函数子句:指明具体操作,如 sum-求和,first_value-取第一个值;
(2)partition by 子句:指明分区字段,如果没有,则将所有数据作为一个分区; (3)order by 子句:指明了每个分区排序的字段和方式,也是可选的,没有就是 按照表中的顺序;
(4)窗口子句:指明相对当前记录的计算范围,可以向上(preceding),可以 向下(following),也可以使用 between 指明上下边界的值,没有的话默认为当 前分区。以下是所有可能的窗口子句定义组合,语法如下:
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURR
ENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOW
ING)
(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点(一般结合 PRECEDING,FOLLOWING 使用)
UNBOUNDED PRECEDING 表示该窗口最前面的行(起点)
UNBOUNDED FOLLOWING:表示该窗口最后面的行(终点)ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(从起点到当前行)
ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING(表示往前 2 行到往后 1 行)
ROWS BETWEEN 2 PRECEDING AND 1 CURRENT ROW(表示往前 2 行到当前行)
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING(当前行到终点) RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位 DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
LAG(col,n,DEFAULT) 用于统计窗口内往上第 n 行值 第一个参数为列名,第二个参数为往上第 n 行(可选,默认为 1),第三个参数 为默认值(当往上第 n 行为 NULL 时候,取默认值,如不指定,则为 NULL)
与 LAG 相反,LEAD(col,n,DEFAULT) 用于统计窗口内往下第 n 行值 第一个参数为列名,第二个参数为往下第 n 行(可选,默认为 1),第三个参数 为默认值(当往下第 n 行为 NULL 时候,取默认值,如不指定,则为 NULL)
first_value : 取分组内排序后,截止到当前行,第一个值
last_value: 取分组内排序后,截止到当前行,最后一个值
数据压缩与存储
行式存储和列式存储
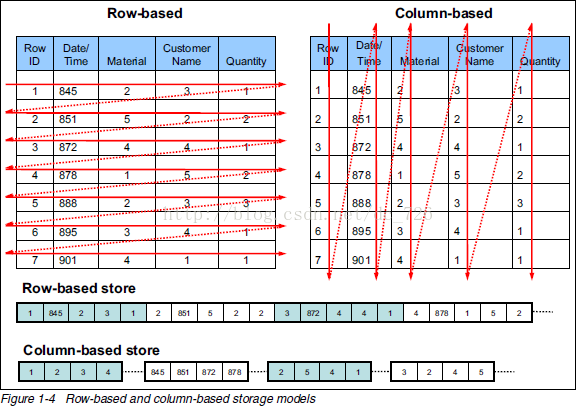
Hive 中常用的存储格式有 TEXTFILE 、SEQUENCEFILE、AVRO、RCFILE、ORCFILE、 PARQUET等,其中TEXTFILE 、SEQUENCEFILE和AVRO是行式存储,RCFILE、ORCFILE、 PARQUET 是列式存储
在建表时使用 STORED AS (TextFile|RCFile|SequenceFile|AVRO|O RC|Parquet)来指定存储格式
- TextFile 每一行都是一条记录,可结合 Gzip、Bzip2 使用
- SequenceFile 是 Hadoop API 提供的一种二进制文件支持,其具有使用方便、 可分割、可压缩的特点
- RCFile 是一种行列存储相结合的存储方式
- ORC 文件格式提供了一种将数据存储在 Hive 表中的高效方法,Hive 从大型表读取,写 入和处理数据时,使用 ORC 文件可以提高性能
- Parquet 是一个面向列的二进制文件格式,Parquet 使用压 缩 Snappy,gzip;目前 Snappy 默认
- AVRO 是开源项目,为 Hadoop 提供数据序列化和数据交换服务。Avro 是一种 用于支持数据密集型的二进制文件格式
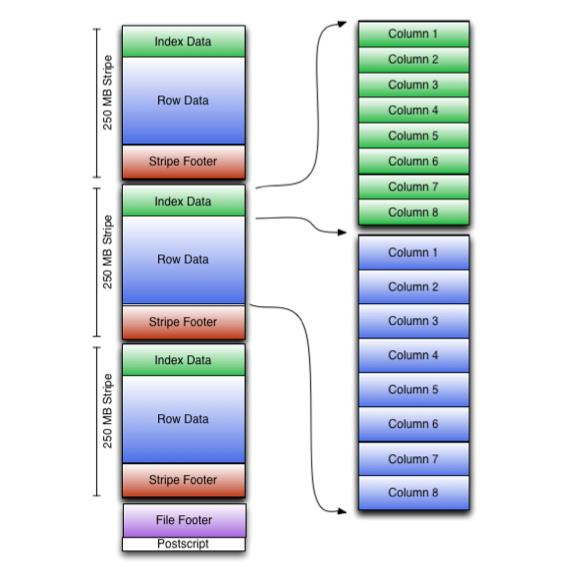
orc文件结构
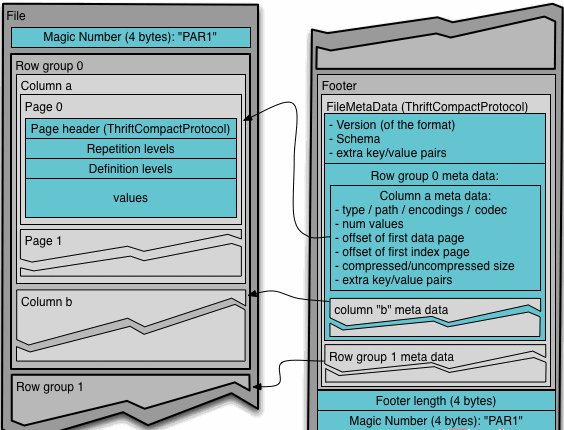
parquet 相较于 orc 的仅有优势:支持嵌套结构
Parquet 文件结构
数据压缩
在 hadoop 作业执行过程中,job 执行速度更多的 是局限于 I/O,而不是受制于 CPU。如果是这样,通过文件压缩可以提高 hadoop 性能。然而,如果作业的执行速度受限于 CPU 的性能,那么压缩文件可能就不合 适,因为文件的压缩和解压会花费掉较多的时间。当然确定适合集群最优配置的 最好方式是通过实验测试,然后衡量结果
压缩配置
-- 任务中间压缩
set hive.exec.compress.intermediate=true;
Set
hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
(常用)
set hive.intermediate.compression.type=BLOCK;
-- map/reduce 输出压缩(一般采用序列化文件存储)
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
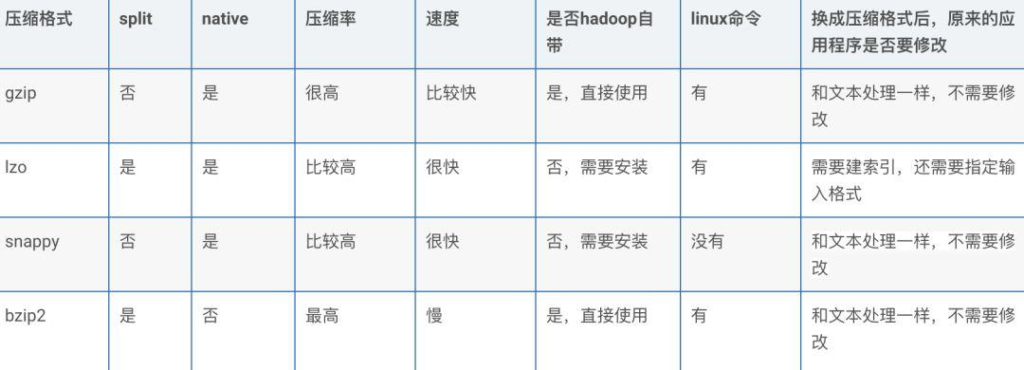
set mapred.output.compression.type=BLOCK;压缩格式
如何选择压缩格式,需要根据具 体的需求决定。(I/O,CPU)
gzip 压缩
【优点】:压缩率比较高,而且压缩/解压速度也比较快;hadoop 本身支持
【缺点】:不支持 split
【应用场景】:当每个文件压缩之后在 130M 以内的(1 个块大小内),都
可以考虑用 gzip 压缩格式
lzo 压缩
【优点】:压缩/解压速度也比较快,合理的压缩率;支持 split,是 hadoop中最流行的压缩格式
【缺点】:压缩率比 gzip 要低一些;hadoop 本身不支持,需要安装
在应用 中对 lzo 格式的文件需要做一些特殊处理(为了支持 split 需要建索引,还需要指定 inputformat 为 lzo 格式)
【应用场景】:一个很大的文本文件,压缩之后还大于 200M 以上的可以考
虑,而且单个文件越大,lzo 优点越越明显
snappy 压缩
【优点】:高速压缩速度和合理的压缩率;支持 hadoop native 库
【缺点】:不支持 split;压缩率比 gzip 要低;hadoop 本身不支持,需要安装
【应用场景】:当 mapreduce 作业的 map 输出的数据比较大的时候,作为
map 到 reduce 的中间数据的压缩格式;或者作为一个 mapreduce 作业的输出和另外一个 mapreduce 作业的输入
bzip2 压缩
【优点】:支持 split;具有很高的压缩率,比 gzip 压缩率都高;hadoop 本身支持,但不支持 native
【缺点】:压缩/解压速度慢;不支持 native
【应用场景】:适合对速度要求不高,但需要较高的压缩率的时候,可以作
为 mapreduce 作业的输出格式;或者输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况;或者对单个很大的文本文件想压缩减少存储空间,同时又需要支持 split,而且兼容之前的应用程序(即应用程序不需要修改)的情况性能调优
查看 SQL 的执行计划
(1)explain:查看执行计划的基本信息。
(2)explain dependency:dependency 在 explain 语句中使用,会产生有关计划中输入的额外信息,它显示了输入的各种属性。
(3)explain authorization:查看 SQL 操作相关权限的信息。通过 explain authorization 可以知道当前 SQL 访问的数据来源(INPUTS)和数据输出(OUTPUTS),以及当前 Hive 的访问用户(CURRENT_USER)和操作(OPERATION)
(4)explain vectorization:查看 SQL 的向量化描述信息。
(5)explain extended:加上 extended 可以输出有关计划的额外信息。这通常是物理信息,例如文件名,这些额外信息对我们用处不大。 执行计划常见的属性
(1)Map Operator Tree:MAP 端的执行计划树
(2)Reduce Operator Tree:Reduce 端的执行计划树
这两个执行计划树里面包含这条 sql 语句的 operator:
(1)TableScan:表扫描操作,map 端第一个操作肯定是加载表,所以就是表扫描操作,常见的属性:
➢ alias:表名称
➢ Statistics:表统计信息,包含表中数据条数,数据大小等
(2)Select Operator:选取操作,常见的属性 :
➢ expressions:需要的字段名称及字段类型
➢ outputColumnNames:输出的列名称
➢ Statistics:表统计信息,包含表中数据条数,数据大小等
(3)Group By Operator:分组聚合操作,常见的属性:
➢ aggregations:显示聚合函数信息
➢ mode:聚合模式,值有
hash:随机聚合,就是 hash partition;
partial:局部聚合;
final:最终聚合
➢ keys:分组的字段,如果没有分组,则没有此字段
➢ outputColumnNames:聚合之后输出列名
➢ Statistics:表统计信息,包含分组聚合之后的数据条数,数据大小等
(4)Reduce Output Operator:输出到 reduce 操作,常见属性:
➢ sort order:
值为空 不排序;
值为 + 正序排序,
值为 - 倒序排序;
值为 +- 排序的列为两列,第一列为正序,第二列为倒序
(5)Filter Operator:过滤操作,常见的属性:
➢ predicate:过滤条件,如 sql 语句中的 where id>=1,则此处显示(id >= 1)
(6)Map Join Operator:join 操作,常见的属性:
➢ condition map:join 方式 ,如 Inner Join 0 to 1 Left Outer Join 0 to 2
➢ keys: join 的条件字段
➢ outputColumnNames: join 完成之后输出的字段
➢ Statistics: join 完成之后生成的数据条数,大小等
(7)File Output Operator:文件输出操作,常见的属性:
➢ compressed:是否压缩
➢ table:表的信息,包含输入输出文件格式化方式,序列化方式等
(8)Fetch Operator:客户端获取数据操作,常见的属性:
➢ limit,值为 -1 表示不限制条数,其他值为限制的条数 性能调优
开启 Fetch 抓取(默认已开启)
Fetch 抓取是指,Hive 中对某些情况的查询可以不必使用 MapReduce 计算,在这种情况下,Hive 可以简单地读取 user_base_info 对应的存储目录下的文件, 然后输出查询结果到控制台。
本地模式
Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。表的优化
小表 Join 大表:
启用mapjoin
需要注意的是 Join 小表默认进内存的大小为 25M,可以通过修改
hive.mapjoin.smalltable.filesize=2500000 配置,改变默认大小,但一般修改最大值 不能超过 128M,这个值刚好是 MapReduce 分块的最小单元,也是 HDFS 一个块的默认大小
大表 Join 大表:
1. 空 KEY 过滤
过滤掉非法的或者异常的、无效的或者无意义的 key值。
2. 空 key 转换
有时虽然某个 key 为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在 join 的结果中,此时我们可以表 a 中 key 为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的 reducer 上
#设置 5 个 reduce 个数
set mapreduce.job.reduces = 5;
#JOIN 两张表
select n.* from nullidtable n left join ori o on case when n.id is null then con
cat('hive', rand()) else n.id end = o.id;mapjoin
Group By 优化
默认情况下,Map 阶段同一 Key 数据分发给一个 reduce,当一个 key 数据过大时就会产生数据倾斜。但在数据计算时,并不是所有的聚合操作都需要在Reduce 端完成,很多聚合操作都可以先在 Map 端进行部分聚合,最后在 Reduce端得出最终结果
#是否在 Map 端进行聚合, 默认为 True
set hive.map.aggr = true;
当选项设定为 true,生成的查询计划会有两个 MR Job
# 在 Map 端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000;
#有数据倾斜的时候进行负载均衡(默认是 false)
set hive.groupby.skewindata = true;Count(Distinct)去重统计
由于 COUNT DISTINCT 操作需 要用一个 Reduce Task 来完成,这一个 Reduce 需要处理的数据量太大,就会导 致整个 Job 很难完成,一般 COUNT DISTINCT 使用先 GROUP BY 再 COUNT 的方式 替换
#直接去重
select count(distinct id) from bigtable;
#改写后去重
select count(id) from (select id from bigtable group by id) a; 笛卡尔积
尽量避免笛卡尔积,join 的时候不加 on 条件,或者无效的 on 条件都有可能会 产生笛卡尔积。Hive 只能使用 1 个 reducer 来完成笛卡尔积,会导致计算性能较 低。
行列过滤
动态分区调整
#开启动态分区功能(默认 true, 开启)
hive.exec.dynamic.partition=true
#设置为非严格模式(动态分区的模式默认 strict,表示必须指定至少一个分区为静态分区,
nonstrict 模式表示允许所有的分区字段都可以使用动态分区。)
hive.exec.dynamic.partition.mode=nonstrict
#在所有执行 MR 的节点上,最大一共可以创建多少个动态分区。
hive.exec.max.dynamic.partitions=1000
# 在每个执行 MR 的节点上, 最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。
比如:源数据中包含了一年的数据,即 day 字段有 365 个值,那么该参数就需要设置成大于 365,
如果使用默认值 100,则会报错。
hive.exec.max.dynamic.partitions.pernode=100
#整个 MR Job 中,最大可以创建多少个 HDFS 文件。
hive.exec.max.created.files=100000
#当有空分区生成时, 是否抛出异常。 一般不需要设置。
hive.error.on.empty.partition=false 数据倾斜问题
reduce 阶段卡在 99.99%不动;各 种 container 报错 OOM(内存溢出);读写数据量很大,超过其他正常 reduce
数据倾斜的原理
在进行 shuffle 的时候,必须将各个节点上相同的 key 拉取到某个节点上的一个 task 来进行处理,比如按照 key 进行聚合或 join 等操作。此时如果某个 key 对应的数据量特别大的话,就会发生数据倾斜
发生数据倾斜的原因在于 Task 的数据分配不均衡
分为两种情况:
1:数据本身就是倾斜的,数据中某种数据出现的次数过多;
2:分区规则导致这些相同的数据都分配给了同一个 Task,导致这个 Task 拿到了大量的数据,而其他 Task 数据量比较少,所以运行起来较慢高阶函数
多维组合查询
GROUPING SETS
CUBE
ROLLUP
lateral view explode()