
Hive 企业调优实战架构与必备
Hive 的调优要具有全局观,从架构的角度去看
1. map/reduce/shuffle 阶段优化
公司企业生产一般建议将环形缓冲区内存设置到 512Mb 起
1.避免溢写磁盘,通过内存提高性能;
2.减少 spill 次数,防止阻塞
3.减少溢写文件的个数,减少文件合并,提高性能;
需要注意,环形缓冲区设置为512M,则map大小也得大于512M才可以,不然单个split文件大小只有128M的话,会浪费环形缓冲区的资源,且环形缓冲区内存本就是map内存的一部分。map 阶段会默认进行排序
目的是减少 reduce 在 copy 拉取 map 数据的寻址时间,其次提高 reduce 阶段的数据排序合并的效率Reduce 阶段的其他优化一般都是从集群层面的优化,比如 map 输出压缩, reduce 下载数据线程数
从 Shuffle 阶段看出 map/reduce 阶段应尽可能多给内存,尽量在内存中优化即可,这块的优化参数大部分都是集群层面的优化;
Shuffle 过程集群层面的优化
参数 1:reduce 启动复制的时间点 slowstart
关于 reduce 什么时候从 map 复制数据问题,慎用,会造成 reduce 占用资源等着 map 的情形,造成任务“卡住”的状态;
mapreduce.job.reduce.slowstart.completedmaps
--apache 默认值 0.05,表示 maptask 至少完成 5%以上,才开始
为 reduce 申请资源吗,执行 reducetask。实际生产通常设置为1。
注意这个参数直接客户端设置即可生效
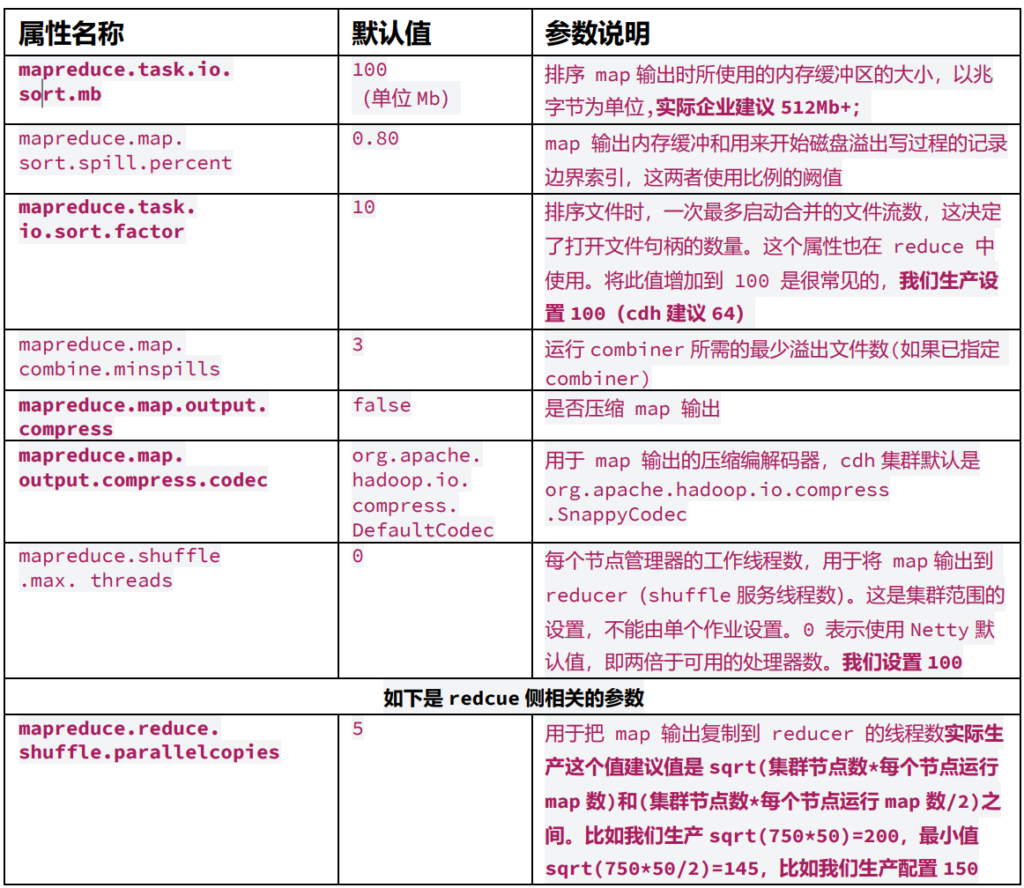
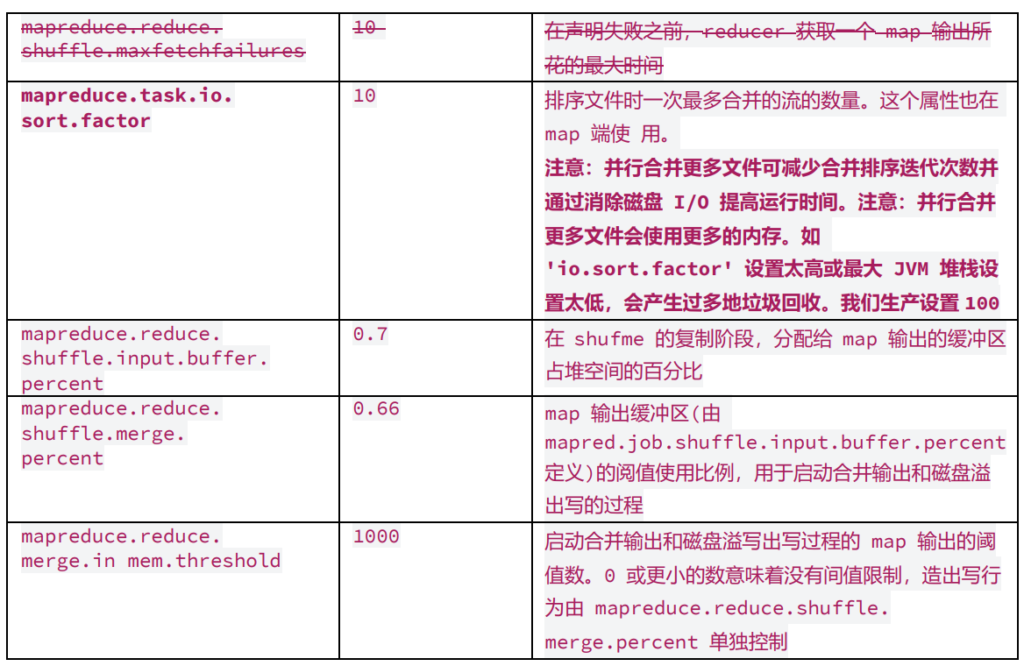
set mapreduce.job.reduce.slowstart.completedmaps=0.5 ; shuffle 参数系列 2:map/reduce 阶段集群参数推荐
在 Hive2.0 之后不推荐 MR 作 为计算引擎。Spark3 以后不支持 Hive on Spark;
Hive 企业调优主要分成两个模块:
◼ 代码层面调优(运行前)
◼ 任务运行参数层面调优(运行时)
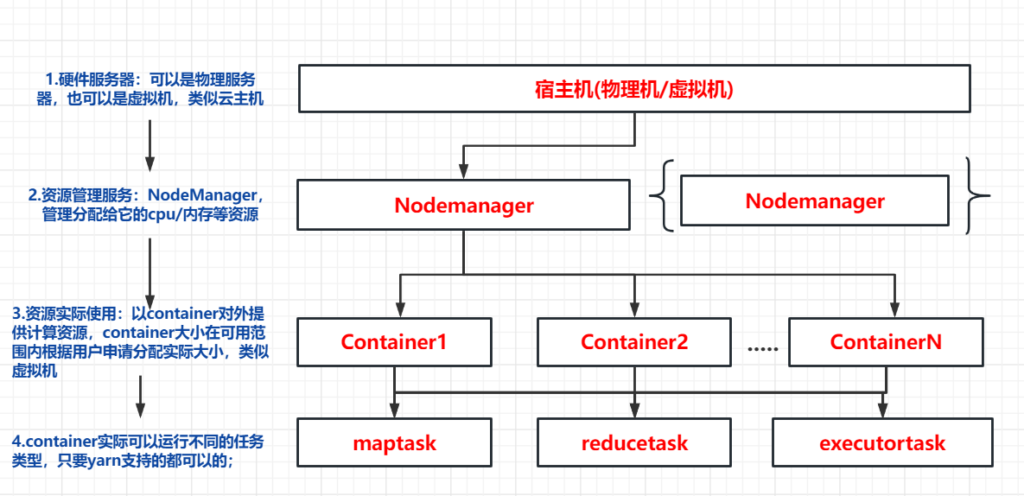
Hive 的 map/reduce 内存与核数调优
YARN 资源管理层次图
Hive 官网的参数查看路径: https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
MapReduce 官网参数:
控制 map/reduce 内存与核数相关参数
参数 1.设置每个 map 的内存和核数大小
set mapreduce.map.memory.mb=3072; (官方默认值 1024)
set mapreduce.map.cpu.vcores=1; (官网默认值 1core)
比如京东,苏宁,新浪这块设置的值每个 map 的 cores/内存=1core+2g
延展设置每个 map 的 java 堆内存大小,一般不建议设置,默认 80%,它
会自动根据这个参数计算
set mapreduce.job.heap.memory-mb.ratio=0.8。
强烈不建议乱设置如下参数
set mapreduce.map.java.opts='-Xmx5200m'
参数 2.设置每个 reduce 的内存大小
set mapreduce.reduce.memory.mb=6144; (官方默认值 1024)
set mapreduce.reduce.cpu.vcores= 2 ; (官网默认值 1core)
同理如上,不建议随便对堆内存分配调整
set mapreduce.reduce.java.opts='-Xmx5200m' 以上关于 map/reduce 的参数都可以通过客户端直接设置生效,会覆盖集群层 面的参数;
如何控制 map 个数与性能调优
defaultNum=totalSize/blockSize
expNum=mapred.map.tasks
expMaxNum=max(expNum,defaultNum)//期望大小只有大于默认大小才会生效;
realSplitNum =totalSize/max(mapred.min.split.size,blockSize)
实际的 map 个数=min(realSplitNum,expMaxNum)
参数 1:下面参数开启 map 前小文件合并,官方默认开启(Hive0.5.0)
set hive.input.format =
org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
参数 2:(默认值如下)
mapreduce.input.fileinputformat.split.maxsize=256000000
mapreduce.input.fileinputformat.split.minsize=1
mapreduce.input.fileinputformat.split.minsize.per.node=1
mapreduce.input.fileinputformat.split.minsize.per.rack=1
增加 split 最小参数值,减少 map 数
set mapred.max.split.size=256000000;
set mapred.min.split.size= 128000000;
set mapred.min.split.size.per.node=128000000;
set mapred.min.split.size.per.rack=128000000;
默认也是最优化的每个 map 处理的数据大小等于 block 大小;合理控制 map 个数,map 个数过多浪费资源,同时会造成资源抢占。map 过少造成 单个 map 处理数据量过大,会造成任务跑的慢。建议单个 map 的处理数据 量在 128Mb-512Mb 之间
特别注意一点,如果生产上有些文件存储不可切分 split,这文件大小就等于 map 的处理大小。但是虽然不可切分,但是可以合并如何控制 reduce 个数与性能调优
生产中 reduce 个数主要由如下 3 个参数关联
参数 1:直接指定 reduce 个数
set mapred.reduce.tasks/ mapreduce.job.reduces
默认值是-1,代表系统会根据算法需要自行决定 Reducer 的数量,使用这个值我们可以直接指定 job 的 reduce 个数,其他参数就不生效了,这种方式一般不用;
参数 2:通过 reduce 处理的数据量,推断 reduce 个数;
set hive.exec.reducers.bytes.per.reducer=1000000000
reduce 计算方式:计算 reducer 数的公式很简单:
Num=min(hive.exec.reducers.max,map 输出数据大小
/hive.exec.reducers.bytes.per.reducer)
hive.exec.reducers.max默认是1099个,可以调整
参数 3:当我们使用参数 1,参数 2 设置活推断 reduce 个数时,需
要受这个参数限制,推断的 reduce 个数不能超过这个数的限制;
Set hive.exec.reducers.max;
集群规模很大的时候,数据量很大的时候,建议设置更大些,比如 1999/2999 等,这个值我们可以通过客户端直接设置生效;
set hive.exec.reducers.max=2999;
set hive.exec.reducers.bytes.per.reducer=1000000000
异常情况:
有些 hivesql 的 reduce 个数如下几种情况不受上面推断个数控制:
比如 order by 全局排序,这种情况下 reduce 个数 1;
比如笛卡尔乘积,count(*),count(1)这种需要全局统计的Hive 任务 Task 任务容错机制
map/reduce 实例失败后,在退出之前向 APPMaster 发送错误报告,错误报告会被记录进用户 日志,APPMaster 然后将这个任务实例标记为 failed,将其 containner 资源释放给其他任务使用。
1.控制 Map Task 失败最大尝试次数,默认值 4
老版本废弃参数 mapred.map.max.attempts
Set mapreduce.map.maxattempts=4;
2.控制 Reduce Task 失败最大尝试次数,默认值 4
老版本废弃参数 mapred.reduce.max.attempts
Set mapreduce.reduce.maxattempts =4;
map 或者 reduce 允许失败的百分比,默认是 0,慎用这个参数
mapreduce.map.failures.maxpercent=0;
mapreduce.reduce.failures.maxpercent=0;(默认) AppMaster 容错机制原理与使用
AppMaster 也提供了重试机制,YARN 中的应用程序失败之后,最多尝试次 数由 mapred-site.xml 文件中的 mapreduce.am.max-attempts 属性配置
Set mapreduce.am.max-attempts=2;(官方默认值)Hive 任务推测执行参数优化
MRappMaster 当监控到一个任务实例的运行速度慢于其他任务实例时,会 为该任务启动一个备份任务实例,让这个两个任务同时处理一份数据,如 map/reduce。谁先处理完,成功提交给 MRappMaster 就采用谁的,另一个则 会被 killed,这种方式可以有效防止那些长尾任务拖后腿。是为任务推测 speculative execution
默认 map/reduce 等推测执行都是开启的
set mapreduce.map.speculative=true
---默认,开启 map 推测执行
set mapreduce.reduce.speculative=true
---默认,开启 reduce 推测执行,
set mapreduce.job.speculative.speculative-cap-running-tasks=0.1
---在任何时刻可以被推测执行的任务数百分比
set hive.mapred.reduce.tasks.speculative.execution=true
--注意,如上,hive 有自己的关于控制 reduce 推测执行的参数表示是否
开启 Reduce 任务的推测执行。 即系统在一个 Reduce 任务中执行进度远低于
其他任务的执行进度, 会尝试在另外的机器上启动一个相同的 Reduce 任务集群小文件治理
大量的小文件的会占用大量的 namenode 堆内存空间,给集群的存储造成瓶颈
Hive 小文件从源头治理参数优化
参数 1:下面参数开启 map 前小文件合并,官方默认开启(Hive0.5.0)
set hive.input.format =
org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; 参数 2:下面这个参数表示当一个 MR 作业的平均输出文件大小小于这个数字时,Hive 将启 动一个额外的 map-reduce 作业(敲重点,这里有个坑),将输出文件合并为更大的文件。当 然注意这个参数有个开启关闭按钮参数,分别针对 map-only/map-reduce 任务的
set hive.merge.smallfiles.avgsize=32000000;
set hive.merge.mapfiles = true ;
注意集群层面默认开启 map-only 任务的小文件合并
set hive.merge.mapredfiles = true;
注意集群层面默认不开启 map-reduce 任务的小文件合并,如果需要合并需要手动开启;上面这三个参数一般一起使用;
hive.merge.size.per.task=25600000;
上面这个参数表示作业结束时合并文件的大小,这个一般最好跟生产集群的 block 大小一致合适并行执行优化以及适用场景
一段 HIveSQL 会分成多个 job/stage 执行。默认情况下,Hive 一次只会执行 一个阶段。不过,某个特定的 job 可能包含众多的阶段,而这些阶段可能并非完全 互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个 job 的执行 时间缩短。如果有更多的阶段可以并行执行,那么 job 可能就越快完成。
set hive.exec.parallel=true;(注意默认值集群是 false)
--是否开启 job 并行执行
SET hive.exec.parallel.thread.number=8;
--同一段 sql 最多可以并行执行多少作业 job分区与动态分区的参数
1. set hive.exec.dynamic.partition =true
--(默认 false),表示开启动态分区功能
2. set hive.exec.dynamic.partition.mode = nonstrict;
--默认 strict 模式,表示用户必须指定至少一个静态分区字段,以防用户覆盖所有分区。Nonstrict 模式表示允许所有分区都可以直接动态分区;
3. set hive.exec.max.dynamic.partitions.pernode=100;
--默认 100,一般可以设置大一点,比如 1000,表示每个 maper 或 reducer 可以允许创建的最大动态分区个数,默认是 100,超出则会报错
4. set hive.exec.max.dynamic.partitions =1000(默认值)
-- 表示一个动态分区语句可以创建的最大动态分区个数,超出报错
5. set hive.exec.max.created.files =10000
--(默认) 全局可以创建的最大文件个数,超出报错。Map-Join优化
Map Join 的目的是减少 Shuffle 和 Reducer 阶段的代价,并仅在 Map 阶 段进行 Join
目前,如果小表的总大小大于 25MB,Conditional Task 会选择原始 Common Join 来运行。25MB 是一个非常保守的数字,你可以使用 set hive.smalltable.filesize 来修改。
参数 1:是否开启 mapjoin 模式识别
set hive.auto.convert.join=true;
参数 2:判定小表大小的界定值
set hive.mapjoin.smalltable.filesize= 25000000; Map-Join 原理是把小表通过本地化任务生成 hashtable,形成哈希文件。 最后将这个哈希文件上传到 hadooop 的分布式缓存中,该缓存会将这些文件 发送到每个 mapper 的所在节点的本地磁盘上。这些完成后才会启动 MR 作 业来完成 Join 操作
因为 hashtable 的形成是通过本地 Local Task,其内存空间受 HADOOP_HEAPSIZE 的限制,一般也就 2G,所以不建议讲 map-join 的小表 大小设置超过 1Gb,否则容易报 OOM,其次影响性能。
mapjoin 对于 full join 不生效,其次对于需要保留小表全量 的情况下不生效(smalltable left join bigtable ,这个时候不生效)。原因很简单,如果每个 maptask 都保留一个全量小表,map 端聚合后直接写文件了,没法对每个map 都全保留的小表进行去重,这样会造成数据膨胀;
Group by 的参数优化
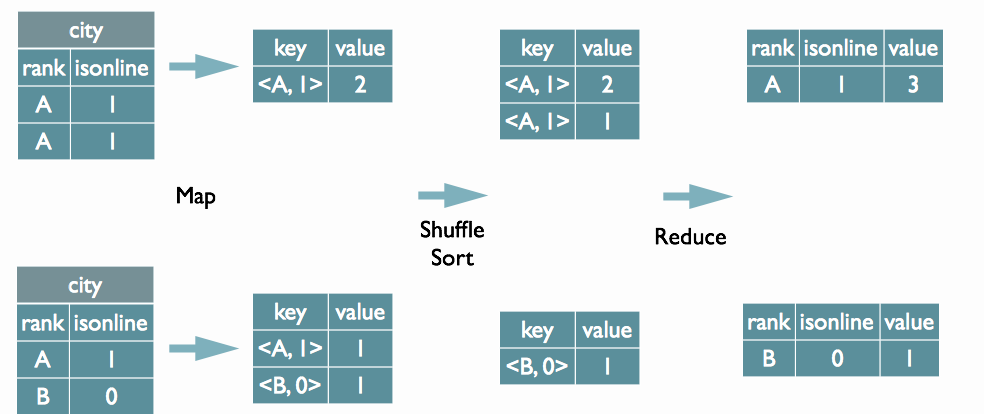
Hive 针对 group by 优化:
1.map 端聚合
预先在 map 端进行一些聚合操作,减轻 reduce 端的压力。先起一个类似 combiner 在 map 端做部分预聚合,本质就是 Hive 使用内存中的哈希
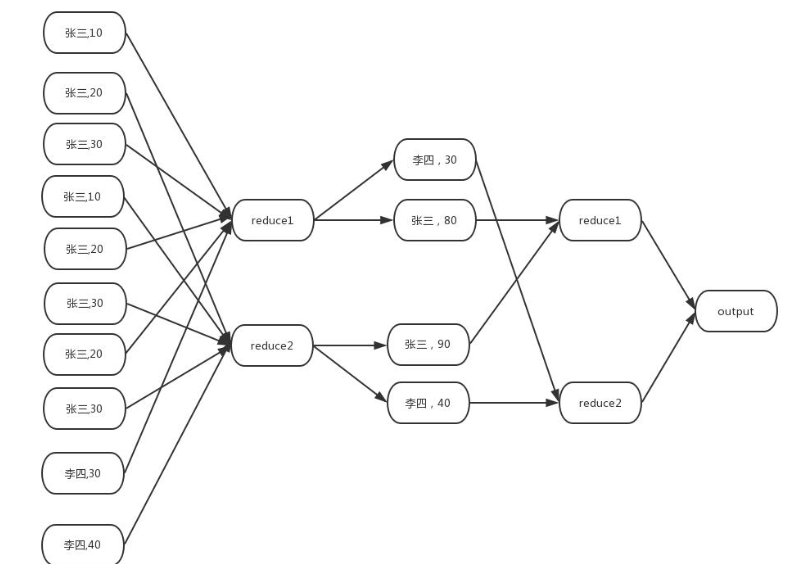
表来保存聚合值,这样可以有效减少 shuffle 数据量,此为 map 端聚合2.负载均衡
生成两个 MR job
➢ 第一个 MR job 中的 map 端会随机将数据分发给 reduce 端,从而降低数据倾斜的发生。
➢ 第二个 MR job 在根据预处理的数据结果按照 Group By Key 再次分发数据完成分组。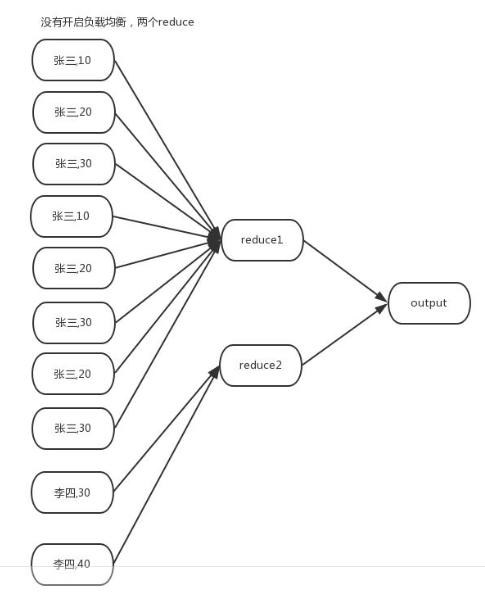
1.set hive.map.aggr=true;
--group by 的查询是否开启 Map 端聚合,默认值是 true。Hive 在默认开启hive.map.aggr 的同时, 引入了两个参数,hive.map.aggr.hash.min.reduction 和hive.groupby.mapaggr.checkinterval, 用于控制何时启用 hash 聚合
2.set hive.groupby.skewindata=false
--有数据倾斜的时候进行负载均衡(默认是 false)。是否优化倾斜的查询为两道作业。其实现方法是在 group by 时启动两个 MR job。第一个 job 会将 map 端数据随机输入reducer,每个 reducer 做部分聚合,相同的 key 就会分布在不同的 reducer 中。第二个job 再将前面预处理过的数据按 key 聚合并输出结果,这样就起到了均衡的效果。(注意这个对于 count(distinct 场景不适用))
3. set hive.groupby.mapaggr.checkinterval=100000
--在这个行数之后,Hive 检查哈希表中的条目数
4. hive.map.aggr.hash.min.reduction=0.5
哈希表和输入行之间的比率,以关闭 map-side 聚合。如果哈希表大小与输入行之间的比率大于此数字,则哈希聚合将被关闭,设置为 1 以确保永远不会关闭哈希聚合。如果输入键在每个 map 任务中是唯一的(或高度选择性的),则 map 端聚合没有价值。所以map 端聚合不适合 groupby 分组重合率低的数据场景
5.hive.map.aggr.hash.percentmemory=0.5
--表示开启 Map 任务的聚合,聚合所用的哈希表,所能占用到整个 Map 被分的内存50%。例如,Map 任务被分配 2GB 内存,那么哈希表最多只能用 1GB
6. hive.multigroupby.singlereduce=true(默认)
--表示如果一个 SQL 语句中有多个分组,聚合操作,且分组是使用相同的字段,那么这些分组聚合操作可以用一个作业的 Reduce 完成,而不是分解成多个作业、多个 Reduce 完成。这可以减少作业重复读取和 Shuffle 的操作。 count(distinct)操作比较特殊,无法进行中间的聚合操作, 因此该hive.map.aggr=true 参数对有 count(distinct)操作的 sql 不适用
给整个脚本作业加统一名称,很香的,不用再去搜 applicaitionid 的了
set mapred.job.name=”bigdata_zyy”;