
性能调优的套路
1.开发调优,包括开发原则、开发经验、Spark 配置应用
2.通用的性能调优,主要是资源和Shuffle相关的优化,包括一些比较典型的场景(Shuffle调优、Broadcast优化),硬件资源的优化(CPU、磁盘、内存、网络)
3.Spark SQL的定向优化,包括我们常见的数据倾斜、数据清洗、数据关联的优化,以及Spark SQL本身有哪些优化可以让我们坐享其成(Catalyst、Tungsten、Adaptive Query Execution(简称AQE)、Dynamic Partition Pruning(DPP)
Spark 性能调优的本质
根据木桶理论,最短的木板决定了木桶的容量,因此,对于一只有短板的木桶,其他木板调节得再高也无济于事,最短的木板才是木桶容量的瓶颈
性能调优不是一锤子买卖,补齐一个短板,其他板子可能会成为新的短板。因此,它是一个动态、持续不断的过程
性能调优的手段和方法是否高效,取决于它针对的是木桶的长板还是瓶颈。针对瓶颈,事半功倍;针对长板,事倍功半
性能调优的方法和技巧,没有一定之规,也不是一成不变,随着木桶短板的此消彼长需要相应的动态切换
性能调优的过程收敛于一种所有木板齐平、没有瓶颈的状态如何定位性能瓶颈
一是先验的专家经验
二是后验的运行时诊断运行时诊断
对于任务的执行情况,Spark UI 提供了丰富的可视化面板,来展示 DAG、Stages 划分、执行计划、Executor 负载均衡情况、GC 时间、内存缓存消耗等等详尽的运行时状态数据
对于硬件资源消耗,开发者可以利用 Ganglia 或者系统级监控工具,如 top、vmstat、iostat、iftop 等等来实时监测硬件的资源利用率
特别地,针对 GC 开销,开发者可以将 GC log 导入到 JVM 可视化工具,从而一览任务执行过程中 GC 的频率和幅度怎么切入
从硬件资源消耗的角度切入,往往是个不错的选择
从硬件的角度出发,计算负载划分为计算密集型、内存密集型和 IO 密集型如果能够明确手中的应用属于哪种类型,自然能够缩小搜索范围,从而更容易锁定性能瓶颈
性能调优的方法与手段
在日常的调优工作中,我们往往从应用代码和 Spark 配置项这2个层面出发性能调优的最终目的
性能调优的最终目的,是在所有参与计算的硬件资源之间寻求协同与平衡,让硬件资源达到一种平衡、无瓶颈的状态通用性能调优
通用开发原则
Filter + Coalesce 和用 mapPartitions 代替 map
用 ReduceByKey 代替 GroupByKey原则一:坐享其成
应该尽可能地充分利用 Spark 为我们提供的“性能红利”
钨丝计划
AQE
SQL functions调用相应的 API 去充分享用 Spark 自身带来的性能优势
原则二:能省则省、能拖则拖
尽量把能节省数据扫描量和数据处理量的操作往前推
尽力消灭掉 Shuffle,省去数据落盘与分发的开销
如果不能干掉Shuffle,尽可能地把涉及 Shuffle 的操作拖到最后去执行原则三:摆脱单机思维模式
忽略或无视分布式数据实体的编程模式,就叫做单机思维模式
单机思维模式会让开发者在分布式环境中,无意识地引入巨大的计算开销Spark Conf
Spark Conf分类
计算负载主要由 Executors 承担,Driver 主要负责分布式调度,调优空间有限,因此对 Driver 端的配置项可以不作考虑,要汇总的配置项都围绕 Executors 展开
硬件资源类
Shuffle 类
Spark SQL 大类。硬件资源
硬件资源类包含的是与 CPU、内存、磁盘有关的配置项
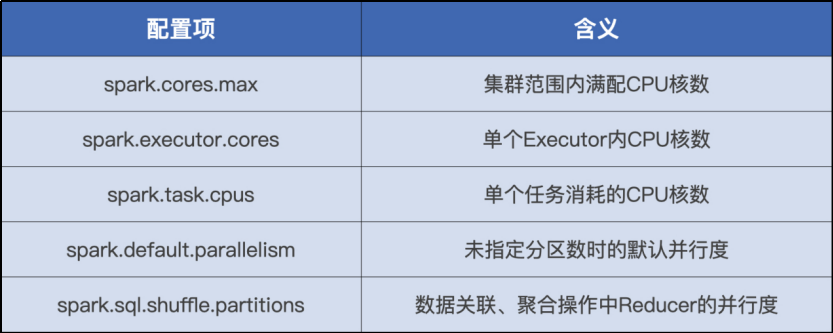
CPU Conf
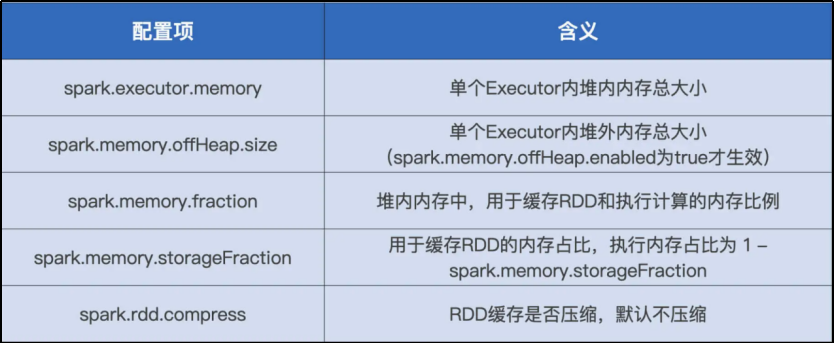
内存 Conf
磁盘Conf
spark.local.dir ,这个参数允许开发者设置磁盘目录,该目录用于存储 RDD cache 落盘数据块和 Shuffle 中间文件
有条件在计算节点中配备足量的 SSD 存储,甚至是更多的内存资源,完全可以把 SSD 上的文件系统目录,或是内存文件系统添加到 spark.local.dir 配置项中去,从而提供更好的 I/O 性能shuffle conf
通过 spark.shuffle.file.buffer 和 spark.reducer.maxSizeInFlight 这两个配置项,来分别调节 Map 阶段和 Reduce 阶段读写缓冲区的大小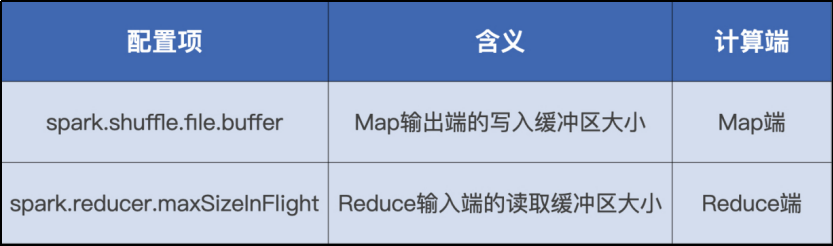
具体思路:
在 Map 阶段
通过设置 spark.shuffle.file.buffer 来扩大写缓冲区的大小,缓冲区越大,能够缓存的落盘数据越多,Spark 需要刷盘的次数就越少,I/O 效率也就能得到整体的提升
在 Reduce 阶段
通过 spark.reducer.maxSizeInFlight 配置项控制 Reduce 端缓冲区大小,来调节 Shuffle 过程中的网络负载
缓冲区越大,可以暂存的数据块越多,在数据总量不变的情况下,拉取数据所需的网络请求次数越少,单次请求的网络吞吐越高,网络 I/O 的效率也就越高事实上,对 Shuffle 计算过程的优化牵扯到了全部的硬件资源,包括 CPU、内存、磁盘和网络。因此,关于 CPU、内存和硬盘的配置项,也同样可以作用在 Map 和 Reduce 阶段的内存计算过程上
不需要排序的shuffle场景
Sort shuffle manager 机制
Spark 统一采用 Sort shuffle manager 来管理 Shuffle 操作,在 Sort shuffle manager 的管理机制下,无论计算结果本身是否需要排序,Shuffle 计算过程在 Map 阶段和 Reduce 阶段都会引入排序操作repartition、groupBy
这两个算子一个是对原始数据集重新划分分区,另一个是对数据集进行分组,压根儿就没有排序的需求
在不需要聚合,也不需要排序的计算场景中,就可以通过设置 spark.shuffle.sort.bypassMergeThreshold 的参数,来改变 Reduce 端的并行度(默认值是 200)
当 Reduce 端的分区数小于这个设置值的时候,我们就能避免 Shuffle 在计算过程引入排序Spark SQL 配置项
对执行性能贡献最大的,当属 AQE(Adaptive query execution,自适应查询引擎)引入的 3 个特性
自动分区合并
自动数据倾斜处理
Join 策略调整AQE 功能默认是禁用的,想要使用这些特性,我们需要先通过配置项 spark.sql.adaptive.enabled 来开启 AQE

与自动分区合并有关的配置
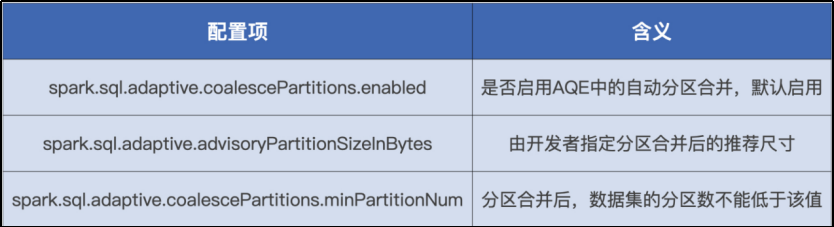
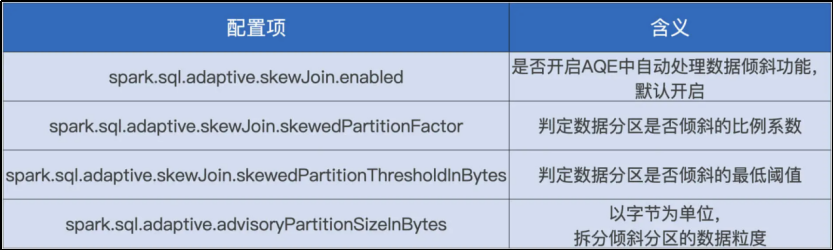
与自动数据倾斜处理有关的配置
Join 策略调整相关的配置


Shuffle 调优
面对 Shuffle,开发者应当“能省则省、能拖则拖”
拖:把应用中会引入 Shuffle 的操作尽可能地往后面的计算步骤去
省:在数据关联场景中,广播变量就可以轻而易举地省去 Shuffle
广播变量是一种分发机制,它一次性封装目标数据结构,以 Executors 为粒度去做数据分发
广播变量分发时,driver并不是把数据广播给所有excutor,已接收到数据的excutor会自发的去传输给附近尚未收到数据的excutor
CPU视角调优
对于 CPU 来说,最需要协同和平衡的硬件资源非内存莫属
Spark 中 CPU 与内存的平衡,其实就是 CPU 与执行内存之间的协同与配比
Spark 中 CPU 与内存的平衡被打破的话,要么 CPU 工作不饱和,要么 OOM 内存溢出
调优需要使用 3 类配置参数,它们分别控制着并行度、执行内存大小和集群的并行计算能力
并行度
spark.default.parallelism 设置 RDD 的默认并行度
spark.sql.shuffle.partitions Shuffle Reduce 阶段默认的并行度并发度
spark.executor.cores(Executor 的线程池大小) / spark.task.cpus(每个任务在执行期间需要消耗的线程数)也就是同一时间内,一个 Executor 内部可以同时运行的最大任务数量
spark.task.cpus 默认数值为 1,并且通常不需要调整
所以,并发度基本由 spark.executor.cores 参数敲定
CPU 低效原因有哪些?
线程挂起
调度开销如何优化 CPU 利用率?
在给定 Executor 线程池和执行内存大小的时候,去计算一个能够让数据分片平均大小在(M/N/2, M/N)之间的并行度,这往往是个不错的选择
M:动态变化的执行内存总量 M。M 的下限是 Execution Memory 初始值,上限是 spark.executor.memory * spark.memory.fraction 划定的所有内存区域。在应用刚刚开始执行的时候,M 的取值就是这个上限,但随着 RDD 缓存逐渐填充 Storage Memory,M 的取值也会跟着回撤。
N:N 的取值含义是一个 Executor 内最大的并发度,更严格的计算公式是 spark.executor.cores 除以 spark.task.cpus。但实际上,上下限公式的计算用的不是 N,而是 N~。N~ 的含义是 Executor 内当前的并发度,也就是 Executor 中当前并行执行的任务数。显然 N~ <= N。内存视角调优
如何最大化利用内存?
预估内存占用
调整内存配置项以堆内内存为例,内存规划方法
堆内内存划分为 Reserved Memory、User Memory、Storage Memory 和 Execution Memory 这 4 个区域
预留内存固定为 300MB,其他 3 个区域需要规划
预估内存占用
内存占用的预估,主要分为三步
第一步,计算 User Memory 的内存消耗
先汇总应用中包含的自定义数据结构,并估算这些对象的总大小 #size,然后用 #size 乘以 Executor 的线程池大小,即可得到 User Memory 区域的内存消耗 #User
第二步,计算 Storage Memory 的内存消耗
先汇总应用中涉及的广播变量和分布式数据集缓存,分别估算这两类对象的总大小,分别记为 #bc、#cache。另外,我们把集群中的 Executors 总数记作 #E。这样,每个 Executor 中 Storage Memory 区域的内存消耗的公式就是:#Storage = #bc + #cache / #E
第三步,计算执行内存的消耗
执行内存的消耗与多个因素有关
第一个因素是 Executor 线程池大小 #threads,第二个因素是数据分片大小,而数据分片大小取决于数据集尺寸 #dataset 和并行度 #N。因此,每个 Executor 中执行内存的消耗的计算公式为:#Execution = #threads * #dataset / #N调整内存配置项
求出3 个内存区域的预估大小 #User、#Storage、#Execution之后
应用下列公式
公式(spark.executor.memory – 300MB)* spark.memory.fraction * spark.memory.storageFractionspark.memory.fraction = (#Storage + #Execution)/(#User + #Storage + #Execution)
spark.memory.storageFraction = (#Storage)/(#Storage + #Execution)
spark.executor.memory = 300MB + #User + #Storage + #ExecutionCache的注意事项
cache是惰性操作,因此在调用.cache之后,需要先用 Action 算子触发缓存的物化过程
由于 Storage Memory 内存空间受限,因此 Cache 应该遵循最小公共子集原则
除此之外,我们也应当及时清理用过的 Cache,尽早腾出内存空间供其他数据集消费,从而尽量避免 Eviction 的发生
用.unpersist 来清理弃用的缓存数据,它是.cache 的逆操作
unpersist 操作支持同步、异步两种模式:
异步模式:调用 unpersist() 或是 unpersist(False)
Driver 把清理缓存的请求发送给各个 Executors 之后,会立即返回,并且继续执行用户代码,比如后续的任务调度、广播变量创建等等
同步模式:调用 unpersist(True)
Driver 发送完请求之后,会一直等待所有 Executors 给出明确的结果(缓存清除成功还是失败)在需要主动清除 Cache 的时候,我们往往采用异步的调用方式,也就是调用 unpersist() 或是 unpersist(False)。
磁盘视角调优
磁盘虽然在处理延迟上远不如内存,但在性能调优中依然不可或缺
理解磁盘在功能上和性能上的价值,可以帮助我们更合理地利用磁盘,以成本优势平衡不同硬件资源的计算负载
从性能上看,利用好磁盘复用机制,可以极大地提高应用的执行性能
磁盘复用指的是 Shuffle Write 阶段产生的中间文件被多次计算重复利用的过程磁盘复用有两种用途
一个是失败重试
磁盘复用缩短了失败重试的路径,在保障作业稳定性的同时,提升执行性能
另一个是 ReuseExchange 机制
相同或是相似的物理计划可以共享 Shuffle 计算的中间结果
ReuseExchange 对于执行性能的贡献相当可观,它可以让基于同一份数据源的多个算子只读取一次 Parquet 文件,并且只做一次 Shuffle,来大幅削减磁盘与网络开销Spark SQL 在优化阶段选择 ReuseExchange的条件
多个查询所依赖的分区规则要与 Shuffle 中间数据的分区规则保持一致
多个查询所涉及的字段要保持一致网络视角调优
如何有效降低网络开销
数据读取阶段,使用NODE_LOCAL 的本地级别,Spark 就可以用磁盘 I/O 替代网络开销获取数据
在数据处理阶段,我们应当遵循“能省则省”的开发原则,在适当的场景用 Broadcast Joins 来避免 Shuffle 引入的网络开销
若没法避免 Shuffle,我们可以在计算中多使用 Map 端聚合,减少需要在网络中分发的数据量
在数据通过网络分发之前,我们可以利用 Kryo Serializer 序列化器,提升序列化字节的存储效率,从而有效降低在网络中分发的数据量,整体上减少网络开销Spark SQL性能优化
在 2.0 版本之前,Spark SQL 仅仅支持启发式、静态的优化过程
启发式的优化又叫 RBO(Rule Based Optimization,基于规则的优化),它往往基于一些规则和策略实现,如谓词下推、列剪枝,这些规则和策略来源于数据库领域已有的应用经验。也就是说,启发式的优化实际上算是一种经验主义。2.2 版本中推出了 CBO(Cost Based Optimization,基于成本的优化)
CBO 的特点是“实事求是”,基于数据表的统计信息(如表大小、数据列分布)来选择优化策略
因为有统计数据做支持,所以 CBO 选择的优化策略往往优于 RBO 选择的优化规则CBO 也面临三个方面的窘境:“窄、慢、静”
窄:指的是适用面太窄,CBO 仅支持注册到 Hive Metastore 的数据表
慢:指的是统计信息的搜集效率比较低,对于注册到 Hive Metastore 的数据表,开发者需要调用 ANALYZE TABLE COMPUTE STATISTICS 语句收集统计信息,而各类信息的收集会消耗大量时间
静指的是静态优化,这一点与 RBO 一样。如果在运行时数据分布发生动态变化,CBO 先前制定的执行计划并不会跟着调整、适配。3.0 版本推出了 AQE(Adaptive Query Execution,自适应查询执行)
AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化AQE 优化机制触发的时机是 Shuffle Map 阶段执行完毕
AQE 优化的频次与执行计划中 Shuffle 的次数一致
如果你的查询语句不会引入 Shuffle 操作,那么 Spark SQL 是不会触发 AQE 的
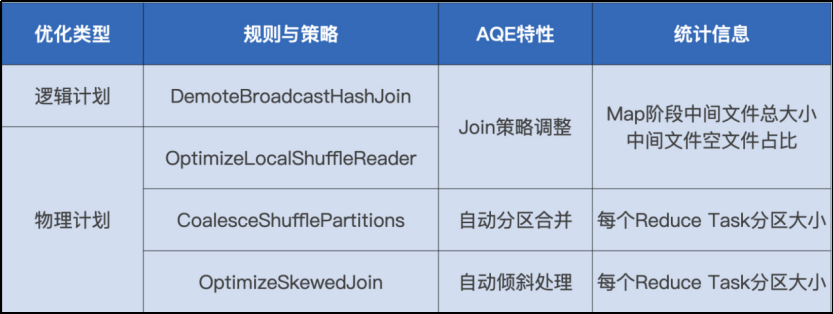
AQE 既定的规则和策略主要有 4 个,分为 1 个逻辑优化规则和 3 个物理优化策略
AQE 的三大特性
Join 策略调整
自动分区合并
以及自动倾斜处理Join 策略调整:如果某张表在过滤之后,尺寸小于广播变量阈值,这张表参与的数据关联就会从 Shuffle Sort Merge Join 降级(Demote)为执行效率更高的 Broadcast Hash Join
自动分区合并:在 Shuffle 过后,Reduce Task 数据分布参差不齐,AQE 将自动合并过小的数据分区
自动倾斜处理:结合配置项,AQE 自动拆分 Reduce 阶段过大的数据分区,降低单个 Reduce Task 的工作负载3.0 版本中第二个引人注目的特性 DPP
DPP(Dynamic Partition Pruning,动态分区剪裁)
指的是在星型数仓的数据关联场景中,可以充分利用过滤之后的维度表,大幅削减事实表的数据扫描量,从整体上提升关联计算的执行性能。
动态分区裁剪的适用条件
spark.sql.optimizer.dynamicPartitionPruning.enabled 参数必须设置为 true,不过这个值默认就是启用的;
需要裁减的表必须是分区表,而且分区字段必须在 join 的 on 条件里面;
Join 类型必须是 INNER, LEFT SEMI (左表是分区表), LEFT OUTER (右表是分区表), or RIGHT OUTER (左表是分区表)
满足上面的条件也不一定会触发动态分区裁减,还必须满足 spark.sql.optimizer.dynamicPartitionPruning.useStats 和 spark.sql.optimizer.dynamicPartitionPruning.fallbackFilterRatio 两个参数综合评估出一个进行动态分区裁减是否有益的值,满足了才会进行动态分区裁减评估函数实现org.apache.spark.sql.dynamicpruning.PartitionPruning#pruningHasBenefit
大表Join小表
大表和小表的定义:大表与小表尺寸相差 3 倍以上,我们就将其归类为大表 Join 小表的计算场景
优先考虑 BHJ,它是 Spark 支持的 5 种 Join 策略中执行效率最高的
BHJ 处理大表 Join 小表时的前提条件是,广播变量能够容纳小表的全量数据
如果小表的数据量超过广播阈值
退而求其次,选择 SMJ(Shuffle Sort Merge Join)的实现方式大表Join大表
大表Join大表的定义:参与 Join 的两张体量较大的事实表,尺寸相差在 3 倍以内,且全部无法放进广播变量
内表和外表的定义:我们要根据两张表的尺寸大小区分出外表和内表。一般来说,内表是尺寸较小的那一方,外表是尺寸较大的一方
分而治之
分而治之”的调优思路是把“大表 Join 大表”降级为“大表 Join 小表”,先把一个复杂任务拆解成多个简单任务,再合并多个简单任务的计算结果
“分而治之”的核心思想是通过均匀拆分内表的方式 ,把一个复杂而又庞大的 Shuffle Join 转化为多个 Broadcast Joins
目的是,消除原有 Shuffle Join 中两张大表所引入的海量数据分发,大幅削减磁盘与网络开销的同时,从整体上提升作业端到端的执行性能。数据倾斜
当参与 Join 的两张表存在数据倾斜问题的时候,该如何应对“大表 Join 大表”的计算场景
根据倾斜位置的不同,可以分为 3 种情况来讨论
单表倾斜,内表倾斜
单表倾斜,外表倾斜
双表倾斜以 Task 为粒度解决数据倾斜
利用 AQE 的特性:自动倾斜处理
给定如下配置项参数,Spark SQL 在运行时可以将策略 OptimizeSkewedJoin 插入到物理计划中,自动完成 Join 过程中对于数据倾斜的处理
spark.sql.adaptive.skewJoin.skewedPartitionFactor,判定倾斜的膨胀系数。
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes,判定倾斜的最低阈值。
spark.sql.adaptive.advisoryPartitionSizeInBytes,以字节为单位定义拆分粒度。以 Executor 为粒度解决数据倾斜
“分而治之”和“两阶段 Shuffle”
分而治之:对于内外表中两组不同的数据,我们分别采用不同的方法做关联计算,然后通过 Union 操作,再把两个关联计算的结果集做合并,最终得到“大表 Join 大表”的计算结果
对于 Join Keys 分布均匀的数据部分,可以沿用把 Shuffle Sort Merge Join 转化为 Shuffle Hash Join 的方法如何理解“两阶段 Shuffle”
通过“加盐、Shuffle、关联、聚合”与“去盐化、Shuffle、聚合”这两个阶段的计算过程,在不破坏原有关联关系的前提下,在集群范围内以 Executors 为粒度平衡计算负载