SparkSQL的优势:
写更少的代码
读更少的数据(SparkSQL的表数据在内存中存储不使用原生态的JVM对象存储方式,而是采用内存列存储)
使用高效的数据格式
使用列数存储
谓词下推
提供更好的性能(字节码生成技术、SQL优化)
号称比MapReduce快100倍
强大的SQL 优化器 Catalyst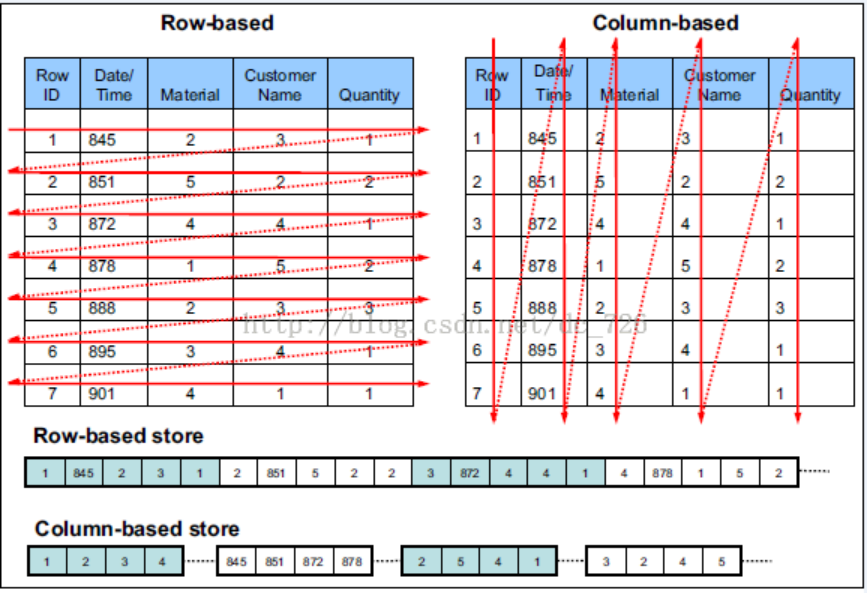
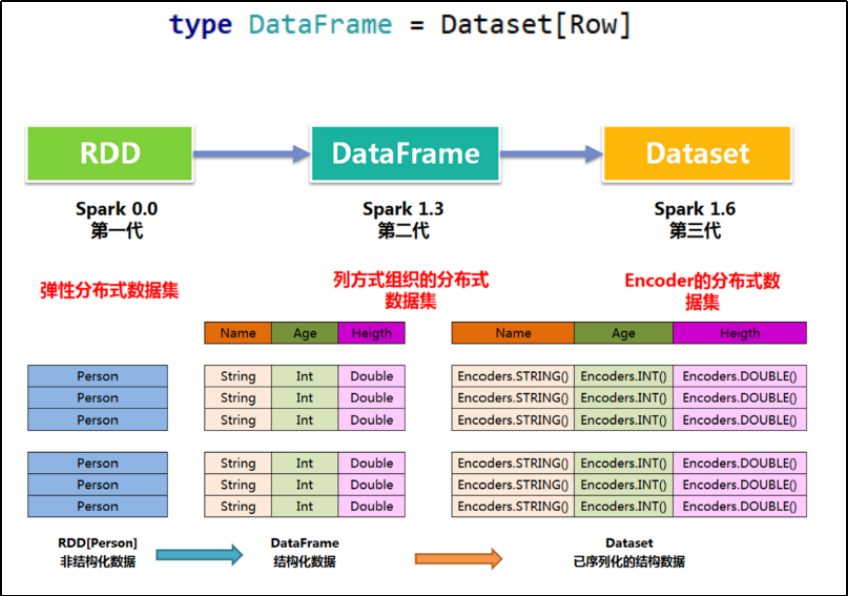
Spark SQL 数据抽象
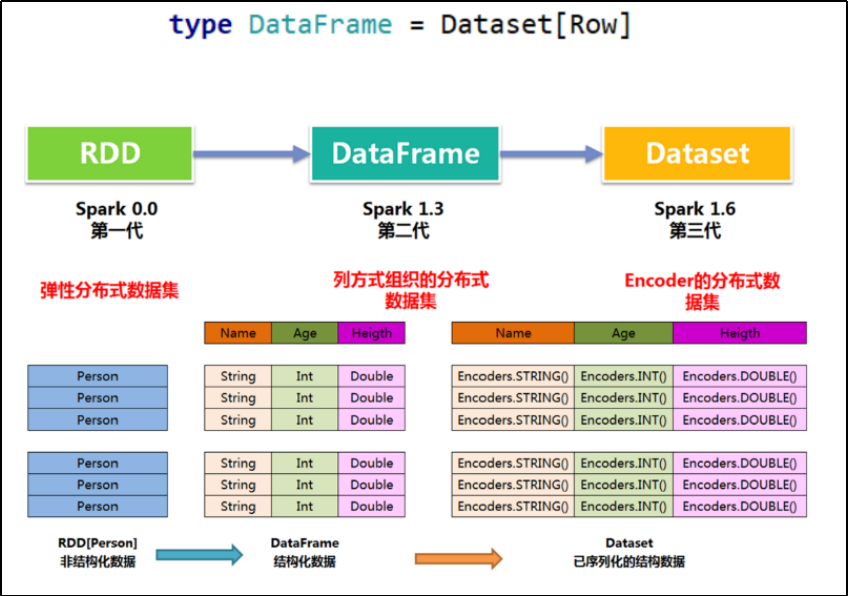
DataFrame和DataSet
DataFrame
DataFrame更像传统数据库的二维表格,除了数据之外,还记录数据的结构信息,即schema
DataFrame也支持嵌套数据类型(struct、array和map)
Dataframe的劣势在于在编译期缺少类型安全检查,导致运行时出错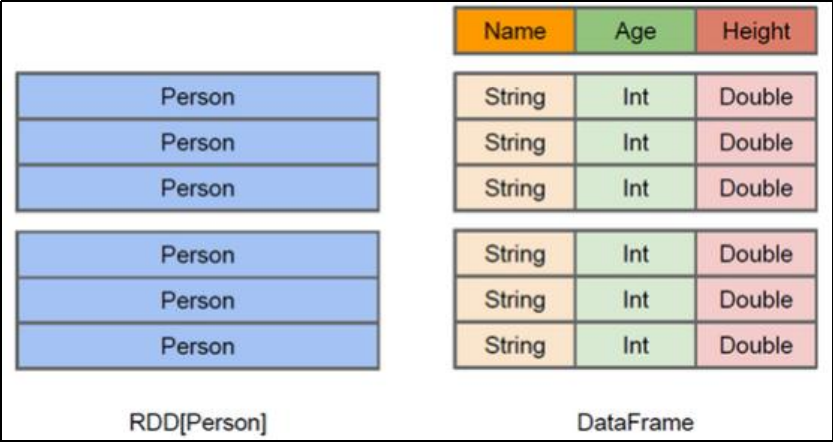
DataSet
DataSet会逐步取代 RDD 和 DataFrame 成为唯一的API接 口
与DataFrame相比,保存了类型信息,是强类型的,提供了编译时类型检查
调用Dataset的方法先会生成逻辑计划,然后Spark的优化器进行优化,最终生成物理计划,然后提交到集群中运行DataFrame表示 为DataSet[Row],即DataSet的子集
Row & Schema
DataFrame = RDD[Row] + Schema;DataFrame 的前身是 SchemaRDD
Row是一个泛化的无类型 JVM object
对DataFrame和Dataset进行操作时,都需要import spark.implicits._
Dataset每一行的类型都是一个case class,在自定义了case class之后可以很自由的获得每一行的信息
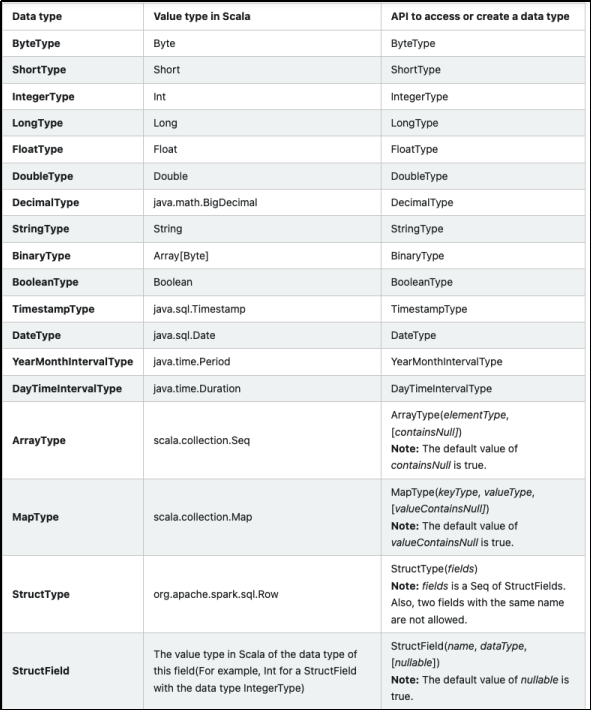
Spark SQL的数据类型