通常的 SQL 执行先会经过 SQL Parser 解析 SQL,然后经过 Catalyst 优化器处理,最后到 Spark 执行
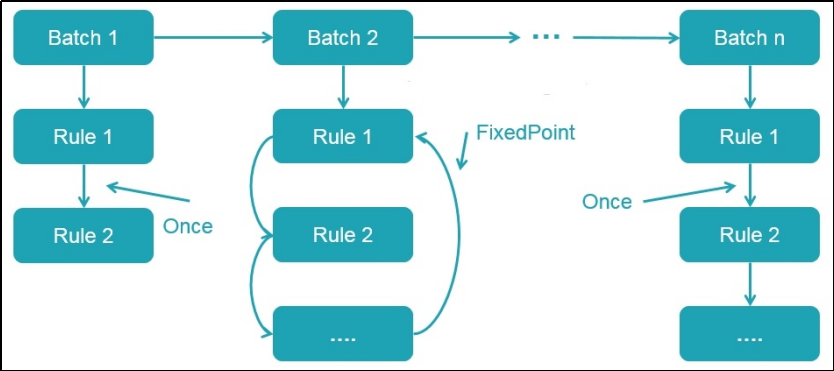
Catalyst 的过程
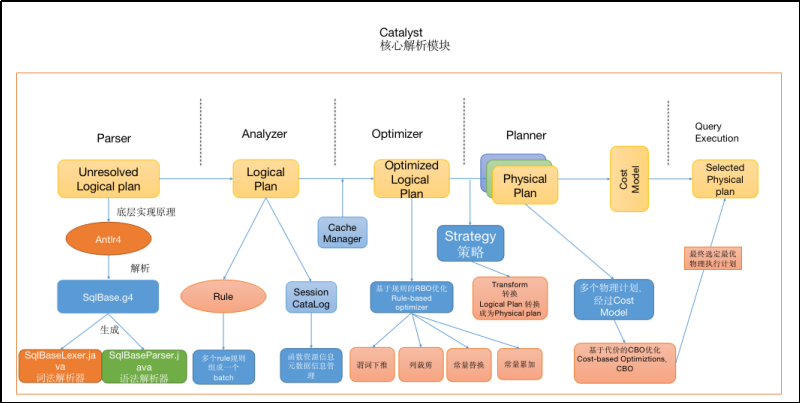
Analysis:主要利用 Catalog 信息将 Unresolved Logical Plan 解析成 Analyzed logical plan;
Logical Optimizations:利用一些 Rule (规则)将 Analyzed logical plan 解析成 Optimized Logical Plan;
Physical Planning:前面的 logical plan 不能被 Spark 执行,而这个过程是把 logical plan 转换成多个 physical plans,然后利用代价模型(cost model)选择最佳的 physical plan;
Code Generation:这个过程会把 SQL 查询生成 Java 字节码。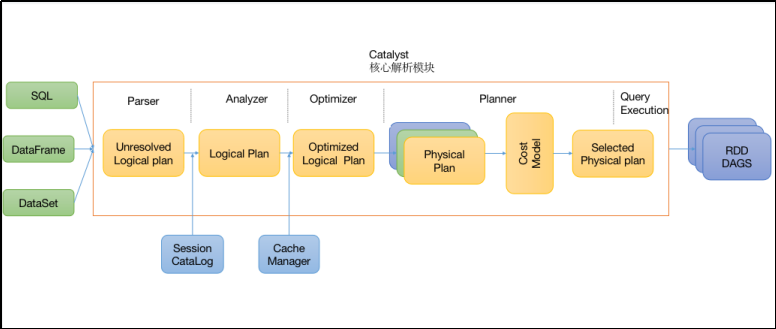
Catalyst执行过程
sql解析阶段 parse
生成逻辑计划 Analyzer
sql语句调优阶段 Optimizer
生成物理查询计划 plannerSQL解析阶段
Spark 通过==ANTLR4==,对 SQL 进行词法分析并构建语法树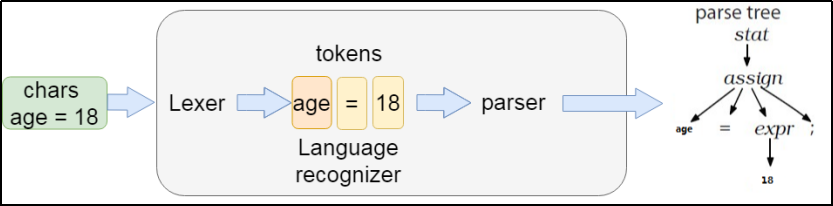
最终通过Lexer以及parse解析之后,生成语法树,生成语法树之后,使用AstBuilder将语法树转换成为LogicalPlan,这个LogicalPlan也被称为Unresolved LogicalPlan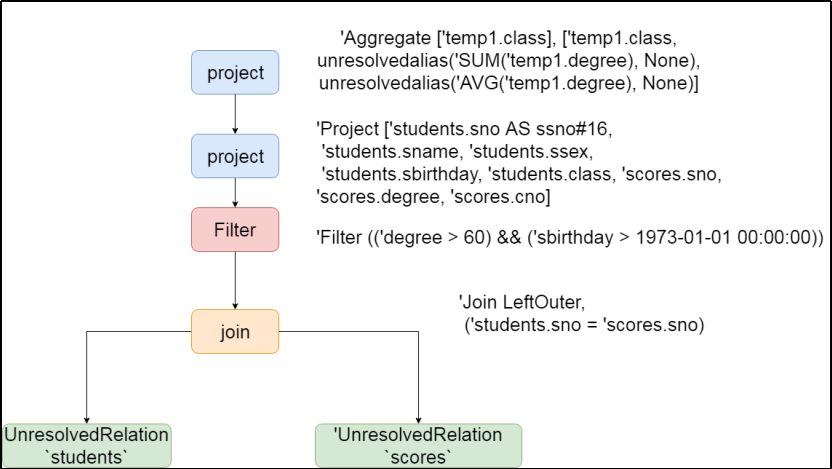
绑定逻辑计划Analyzer
Analyzer 阶段会使用事先定义好的 Rule 以及 SessionCatalog 等信息对 Unresolved LogicalPlan 进行 transform
1、确定最终返回字段名称以及返回类型
2、确定聚合函数
3、确定表当中获取的查询字段
4、确定过滤条件
5、确定join方式
6、确定表当中的数据来源以及分区个数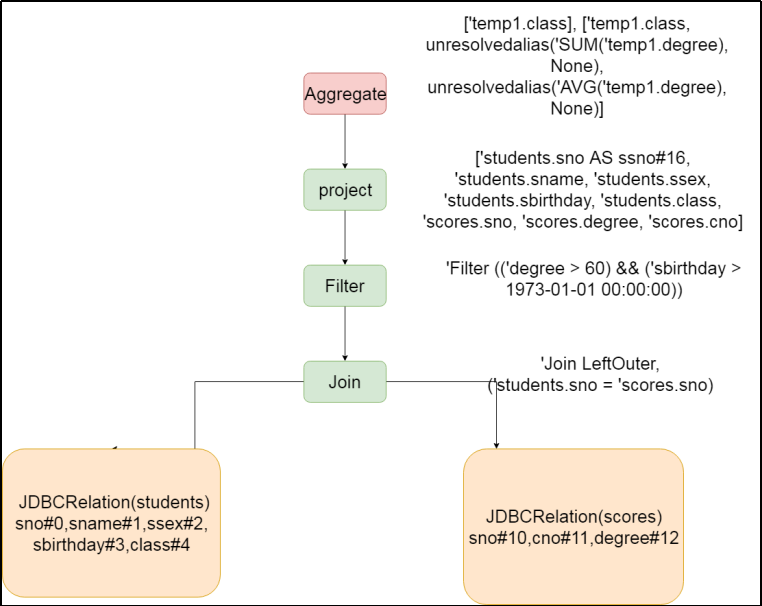
逻辑优化阶段Optimizer
这个阶段的优化器主要是基于规则的(Rule-based Optimizer,简称 RBO)
Analyzed Logical Plan 是可以直接转换成 Physical Plan 然后在 Spark 中执行的,但是未必是最优的执行计划。所以本阶段进一步对Analyzed Logical Plan 进行处理,得到更优的逻辑算子树
启发式规则如下
列裁剪
谓词下推
常量累加
常量替换生成可执行的物理计划阶段Physical Plan
为了能够执行这个sql,最终必须得要翻译成为可以被执行的物理计划,这个阶段使用的是策略strategy
一个逻辑计划(Logical Plan)经过一系列的策略处理之后,得到多个物理计划(Physical Plans),物理计划在 Spark 是由 SparkPlan 实现的。多个物理计划再经过代价模型(Cost Model)得到选择后的物理计划(Selected Physical Plan)
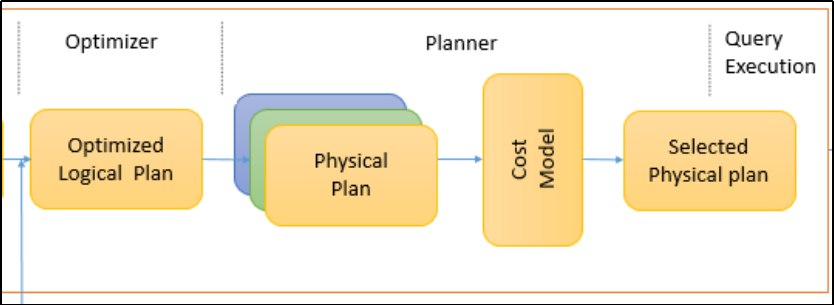
Cost Model 对应的就是基于代价的优化(Cost-based Optimizations,CBO,主要由华为的大佬们实现的,详见 SPARK-16026 )
代码生成阶段
Tungsten(钨丝计划) 代码生成分为三部分
表达式代码生成(expression codegen)
全阶段代码生成(Whole-stage Code Generation)
加速序列化和反序列化(speed up serialization/deserialization)SQL执行