数据仓库(Data Warehouse)
是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)联机事务处理 OLTP(On-Line Transaction Processing)
数据库是面向业务的处理系统,它是针对具体业务在数据库联机的日常操
作,通常对记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题联机分析处理 OLAP(On-Line Analytical Processing)
数据仓库一般针对某些主题的历史数据进行分析,支持管理决策数据仓库实现方式:
数据仓库系统是一个信息提供平台,他从业务处理系统获得数据,主要以星型模型和雪花模型进行数据组织,并为用户提供各种手段从数据中获取信息和知识。从功能结构化分,数据仓库系统至少应该包含数据获取
(Data Acquisition)、数据存储(Data Storage)、数据访问(Data Access)三个关键部分。数据仓库和数据中台
数据仓库的主要场景是支持管理决策和业务分析
数据中台则是将数据服务化之后提供给业务系统,目标是将数据能力渗透到各个业务环节,不限于决策分析类场景数据模型
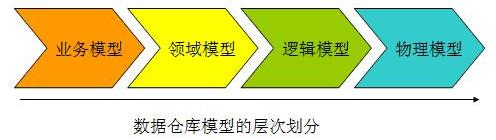
业务建模,生成业务模型,主要解决业务层面的分解和程序化。
领域建模,生成领域模型,主要是对业务模型进行抽象处理,生成领域概念
模型。
逻辑建模,生成逻辑模型,主要是将领域模型的概念实体以及实体之间的关
系进行数据库层次的逻辑化。
物理建模,生成物理模型,主要解决,逻辑模型针对不同关系型数据库的物
理化以及性能等一些具体的技术问题数据模型的建设主要能够帮助我们解决以下的一些问题
进行全面的业务梳理,改进业务流程
建立全方位的数据视角,消灭信息孤岛和数据差异
解决业务的变动和数据仓库的灵活性
帮助数据仓库系统本身的建设数据仓库数据模型架构
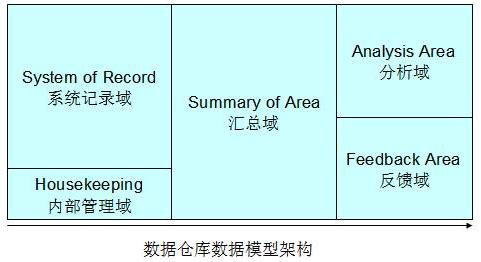
系统记录域(System of Record):这部分是主要的数据仓库业务数据存储区,数据模型在这里保证了数据的一致性
内部管理域(Housekeeping):这部分主要存储数据仓库用于内部管理的元
数据,数据模型在这里能够帮助进行统一的元数据的管理。
汇总域(Summary of Area):这部分数据来自于系统记录域的汇总,数据模型在这里保证了分析域的主题分析的性能,满足了部分的报表查询
分析域(Analysis Area):这部分数据模型主要用于各个业务部分的具体的主题业务分析。这部分数据模型可以单独存储在相应的数据集市中
反馈域(Feedback Area):可选项,这部分数据模型主要用于相应前端的反馈数据,数据仓库可以视业务的需要设置这一区域数据仓库的数据建模的四个阶段及相应工作内容
业务建模
1.划分整个单位的业务,一般按照业务部门的划分,进行各个部分之间业务工作的界定,理清各业务部门之间的关系。
2.深入了解各个业务部门内的具体业务流程并将其程序化。
3.提出修改和改进业务部门工作流程的方法并程序化。
4.数据建模的范围界定,整个数据仓库项目的目标和阶段划分领域概念建模
抽取关键业务概念,并将之抽象化。
将业务概念分组,按照业务主线聚合类似的分组概念。
细化分组概念,理清分组概念内的业务流程并抽象化。
理清分组概念之间的关联,形成完整的领域概念模型。逻辑建模
业务概念实体化,并考虑其具体的属性。
事件实体化,并考虑其属性内容。
说明实体化,并考虑其属性内容物理建模
针对特定物理化平台,做出相应的技术调整。
针对模型的性能考虑,对特定平台作出相应的调整。
针对管理的需要,结合特定的平台,做出相应的调整。
生成最后的执行脚本,并完善之kimball数仓架构
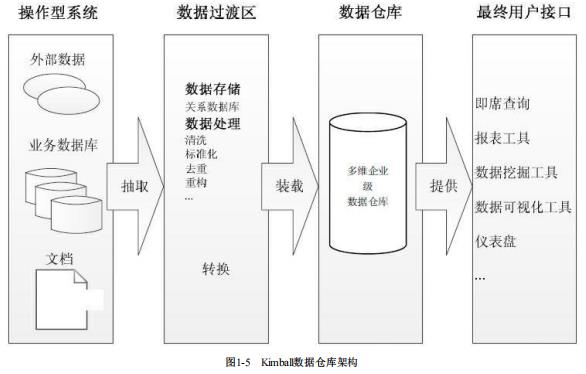
Kimball 模式(维度建模)
Kimball 模式从流程上看是是自底向上的,即从数据集市到数据仓库再到数
据源(先有数据集市再有数据仓库)的一种敏捷开发方法
流程
Kimball 都是以最终任务为导向
1:在得到数据后需要先做数据的探索,尝试将数据按照目标先拆分出不同的表需求
2:在明确数据依赖后将各个任务再通过 ETL 由 Stage 层转化到 DM 层(dwd/dim)。
3:在DM层的完成事实表(dwd)、维度表(dim)的拆分,数据集市一方面可以直接向 BI 环节输出数据了,另一方面可以生成DW层(dws)输出数据,方便后续的多维分析Kimball 支持数据仓库总线结构,提倡维度建模,以星型模型或是雪花模型等
方式构建维度数据仓库
目前数据仓库设计一般都是综合了两者的实现,整体上采用分层架构,具体的模型设计上采用维度建模数仓在设计之初,首先需要明确大方向和目标
1. 明确分层和组成,以及不同部分的定位和相互关系。
2. 规范化、标准化整个数据建模流程
3. 数据统计口径要一致、明确,没有二异性
4. 提高效率,结合前三点,将整个数仓架构梳理清晰,尽量降低数据之间横向的复杂交互,保持数据流向的清晰、简洁,解决烟囱式重复建设,从而提高生产、使用效率,降低成本数据仓库设计基础
关系数据模型
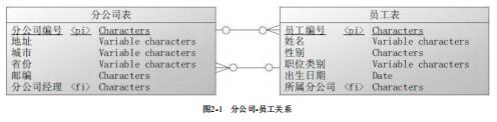
关系
由行和列构成的二维结构,对应关系数据库中的表
如示例中的分公司表和员工表属性
由属性名称和类型名称构成的顺序对,对应关系数据库中表的列,如地址
(Variable Characters)是公司表的一个属性属性域
属性的取值范围
每一个属性都有一个预定义的值的范围
属性域是关系模型的一个重要特征,关系中的每个属性都与一个域相关。各个属性的域可能不同,也可能相同。域描述了属性所有可能的值(枚举值)元组
关系中的一条记录,对应关系数据库中的一个表行关系数据库
一系列规范化的表的集合
这里的规范化可以理解为表结构的正确性关系表的属性
每个表都有唯一的名称;
一个表中每个列有不同的名字;
一个列的值来自于相同的属性域;
列是无序的;行是无序的。关系数据模型中的键
(1)超键
在关系中能唯一标识元素属性的列或者列集称为关系模式的超键
超键可能包含用于唯一标识记录所不必要的额外的列(2)候选键
不含有多余属性的超键称为候选键表的候选键有三个属性:
唯一性:在每条记录中,候选键的值唯一标识该记录
最小性:具有唯一性属性的超键的最小子集
非空性:候选键的值不允许为空一个表中允许有多个候选键
(3)主键
唯一标识表中记录的候选键
主键是唯一、非空的没有被选做主键的候选键称为备用键
(4)外键
一个表中的一个列或多个列的集合,这些列匹配某些其他(也可以是一个)表中的候选键。注意外键所引用的不一定是主键,但一定是候选键
关系数据模型中的完整性
空值
表示一个列的值目前还不知道或者对于当前记录来说不可用
关系完整性规则
(1)实体完整性
在一个基本表中,主键列的取值不能为空(2)参照完整性
如果表中存在外键,则外键值必须与主表中的某些记录的候选键值相同,或者外键的值必须为空(3)用户自定义完整性
一些特殊的约束条件,比如性别只能是男或女,年龄不能超过 150 岁等
针对某一具体关系数据库的约束条件称为用户定义的完整性,它反映某一具体应用所涉及的数据必须满足的语意要求关系数据库语言
DDL
数据定义语言,用于定义数据库结构和模式
create、alter、drop、truncate、comment、rename等DML
数据操纵语言,用于检索、管理和维护数据库对象
select、insert、update、delete、merge、call、explain、lock 等DCL
数据控制语言,用于授予和回收数据库对象上的权限
grant 和 revokeTCL
为事务控制语言,用于管理DML 对数据的改变
commit、rollback、savepoint、settransaction 等关系数据模型中的规范化
关系数据模型的规范化是一种数据组织的技术。规范化方法对表进行分解,
以消除数据冗余,避免异常更新,提高数据完整性。
范式
建立科学的、规范的数据库是需要满足一些规范的来优化数据数据存储方式,在关系型数据库中这些规范就可以称为范式常用的范式有第一范式(1NF)、第二范式(2NF)、第三范式(3NF)第一范式
表中的列只能含有原子性(不可再分)的值。第二范式
满足第一范式;没有部分依赖。什么是部分依赖?
员工表的一个候选键是{id,moblie,deptNo},而 deptName 依赖于
(deptNo),同样 name 仅依赖于{id},因此不是 2NF 的第三范式
满足第二范式;没有传递依赖什么是传递依赖?
例如,员工表的 province、city、district 依赖于 zip,而 zip 依赖于(id),换句话说,province、city、district 传递依赖于(id),违反了 3NF 规则数据不能存在传递关系,即每个属性都跟主键有直接关系而不是间接关系。像:
a-->b-->c 属性之间含有这样的关系,是不符合第三范式的维度数据模型
维度数据模型简称维度模型(Dimensiomal modeling,DM),是一套技术和概
念的集合,用于数据仓库设计。
事实和维度是两个维度模型中的核心概念
事实表示对业务数据的度量
维度是观察数据的角度事实通常是数字类型的,可以进行聚合和计算
而维度通常是一组层次关系或描述信息,用来定义事实
维度模型按照业务流程领域即主题域建立
例如进货、销售、库存、配送等不同的主题域可能共享某些维度,为了提高数据操作的性能和数据一致性,需要使用一致性维度
一致性维度
指的是具有相同属性和内容的维度维度数据模型建模过程
维度模型设计期间主要涉及 4 个主要的过程
(1)选择业务过程
(2)声明粒度
(3)确认维度
(4)确认事实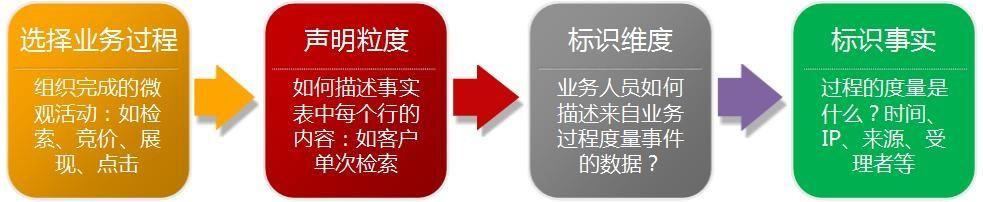
以共同粒度从多个组织业务过程合并度量的事实表称为合并事实表
原子粒度是最低级别的粒度。强烈建议从关注原子级别粒度数据开始设计,因为原子粒度数据能够承受无法预期的用户查询
维度规范化
与关系模型类似,维度也可以进行规范化。对维度的规范化(又叫雪花化),
可以去除冗余属性,是对非规范化维度做的规范化处理在很多情况下,维度规范化后的结构等同于一个低范式级别的关系型结构。
设计维度数据模型时,会因为如下原因而不对维度做规范化处理:
(1)规范化会增加表的数量,使结构更复杂。
(2)不可避免的多表连接,使查询更复杂。
(3)查询性能原因。星型模型
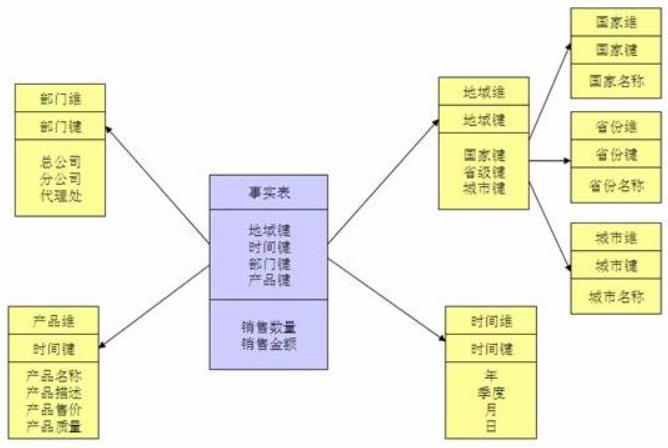
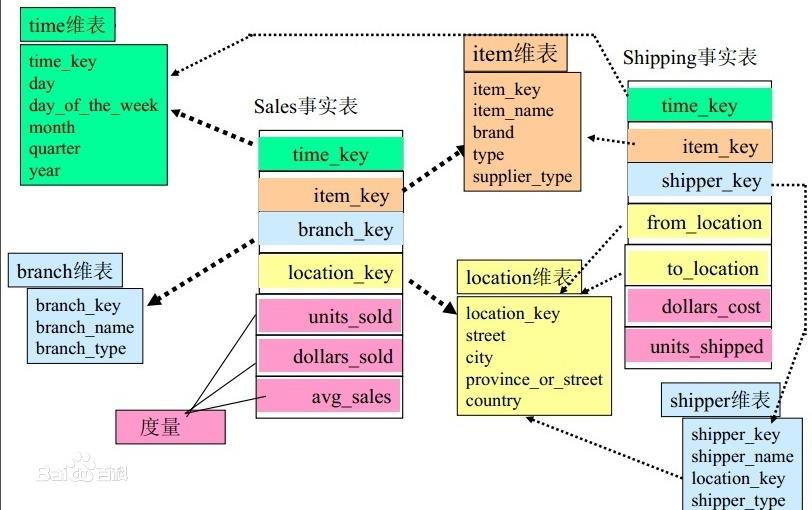
星型模式由事实表和维度表组成,一个星型模式中可以有一个或多个事实表,每个事实表引用任意数量的维表
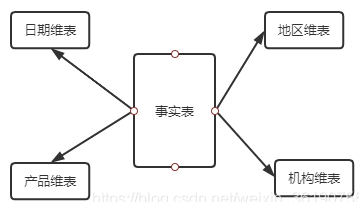
事实表
事实表记录了特定事件的数字化的考量,一般由数字值和指向维度表的外键组成。
通常会把事实表的粒度级别设计得比较低,使得事实表可以记录很原始的
操作型事件,但这样做的负面影响是累加大量记录可能会更耗时事实表的三种类型:
(1)事务事实表 - 记录特定事件的事实
(2)快照事实表 - 记录给定时间点的事实(如月底账户余额)
(3)累积事实表 - 记录给定时间点的聚合事实(如当月的总的销售金额)一般需要给事实表设计一个代理键作为每行记录的唯一标识。
代理键是由系统生成的主键,它不是应用数据,没有业务含义,对用户来说是透明的
维表
维度表的记录数通常比事实表少,但每条记录包含有大量用于描述事实数据的属性字段。
以下是几种最常用的维度表:
(1)时间维度表
(2)地理维度表
(3)产品维度表
(4)人员维度表
(5)范围维度表通常给维度表设计一个单列、整型数字类型的代理键,映射业务数据中的主键。
星型模型的优点
星型模式是非规范化的,在星型模式的设计开发过程中,不受应用于事务型关系数据库的范式规则的约束。
(1) 简化查询
(2) 简化业务报表逻辑
(3) 获得查询性能
(4) 快速聚合
(5) 便于向立方体提供数据星型模式被广泛用于高效地建立 0LAP 立方体
几乎所有的 0LAP 系统都提供 ROLAP 模型(关系型 0LAP),它可以直接将星型模式中的数据当作数据源,而不用单独建立立方体结构。星型模型的缺点
星型模式的主要缺点是不能保证数据完整性。
另一个缺点是对于分析需求来说不够灵活。
星型模式不能自然地支持业务实体的多对多关系,需要在维度表和事实表之间建立额外的桥接表雪花模型
雪花模式也是由事实表和维度表所组成。所谓的“雪花化”就是将星型模式中的维度表进行规范化处理
即维度表采用范式建模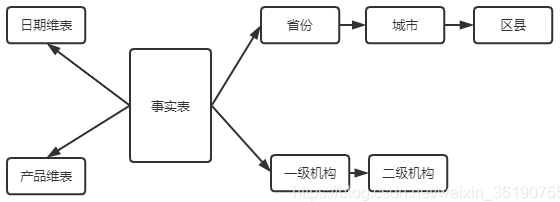
雪花模型的优点
(1) 一些 OLAP 多维数据库建模工具专为雪花模型进行了优化。
(2) 规范化的维度属性节省存储空间
雪花模型的缺点
雪花模型的主要缺点是维度属性规范化增加了查询的连接操作和复杂度。
折中的模型方式
底层使用雪花模型,上层用表连接建立视图模拟星型模式。
这种方法既通过对维度的规范化节省了存储空间,同时又对用户屏蔽了查询的复杂性。
当外部的查询条件不需要连接整个维度表时,这种方法会带来性能损失星座模型
维表是共享状态的,可以被多个事实表关联使用,这种模式可以看做星型模式的汇集,因而称作星系模式或者事实星座模式。
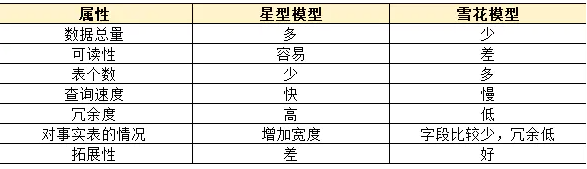
星型模型 VS 雪花模型