
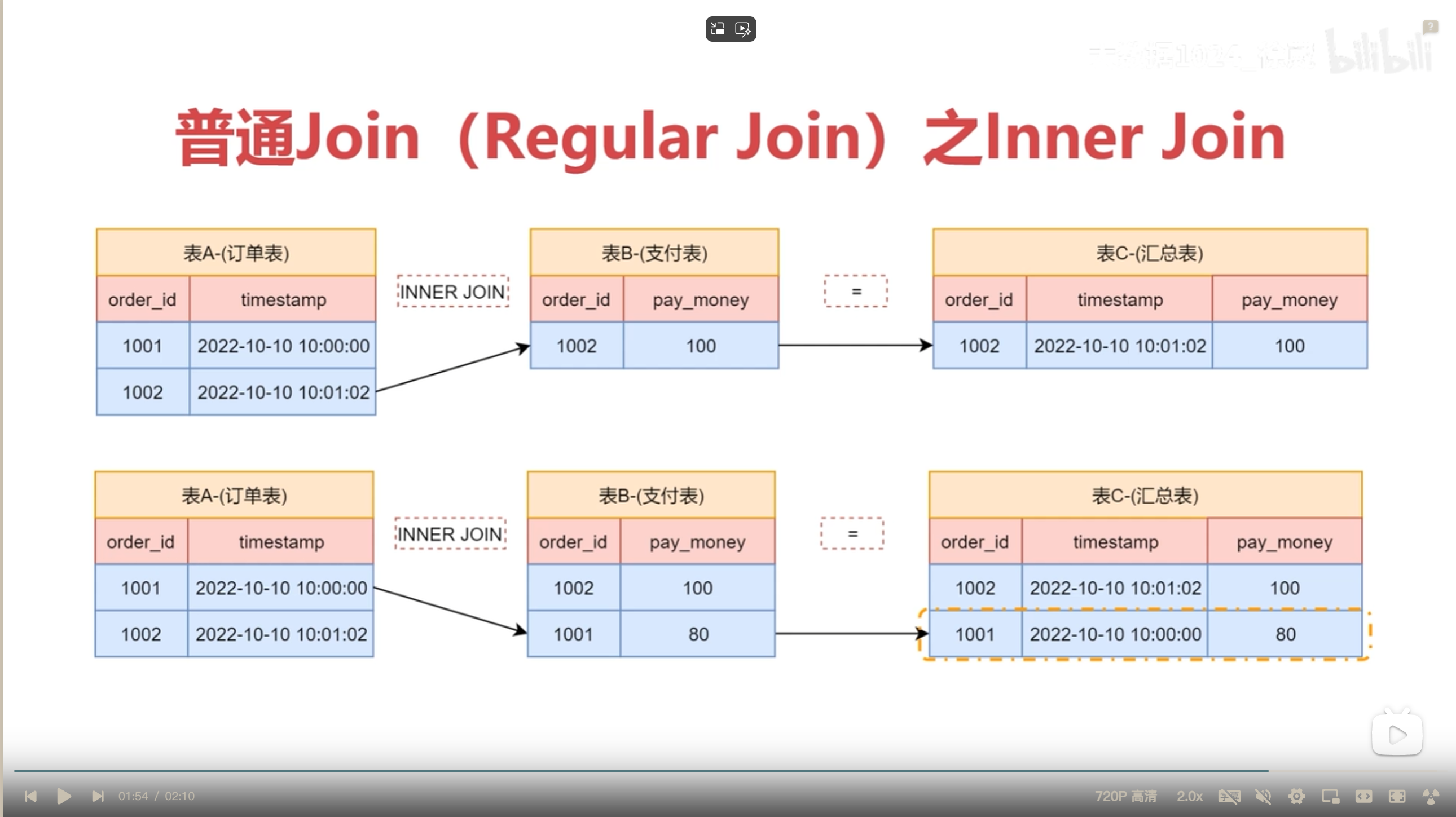
regular join 使用条件

regular join 输出数据结果

regular join 中的 inner Join 原理图解
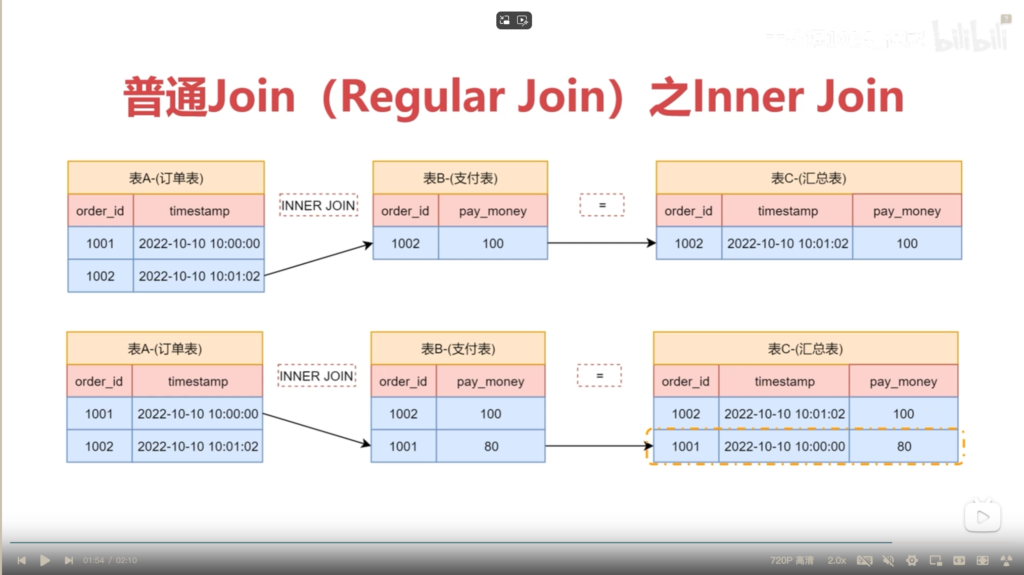
示例代码
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment}
import java.time.ZoneId
/**
* 普通Join (Regular Join) 之 Inner Join
* Created by Richardo.zhang
*/
object RegularJoin_InnerJoin {
def main(args: Array[String]): Unit = {
//创建执行环境
val settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build()
val tEnv = TableEnvironment.create(settings)
//指定国内的时区
tEnv.getConfig.setLocalTimeZone(ZoneId.of("Asia/Shanghai"))
//订单表
//定义sql语句字符串
val UserOderTableSql =
"""
|CREATE TABLE user_order(
| order_id BIGINT,
| ts BIGINT,
| d_timestamp AS TO_TIMESTAMP_LTZ(ts,3)
| -- 注意:d_timestamp的值可以从原始数据中取,原始数据中没有的话也可以从kafka的元数据中取
| -- d_timestamp TIMESTAMP_LTZ(3) METADATA FROM 'timestamp'
|) WITH (
| 'connector' = 'kafka',
| 'topic' = 'user_order',
| 'properties.bootstrap.servers' = 'hdp0001:9092,hdp0002:9092,hdp0003:9092',
| 'properties.group.id' = 'gid-sql-order',
| -- 为了便于演示,在这使用latest-offset,每次启动都使用最新的数据
| 'scan.startup.mode' = 'latest-offset',
| 'format' = 'json',
| 'json.fail-on-missing-field' = 'false',
| 'json.ignore-parse-errors' = 'true'
|)
|""".stripMargin
//执行sql语句字符串
tEnv.executeSql(UserOderTableSql)
//支付表
//定义sql语句字符串
val PaymentFlowTableSql =
"""
|CREATE TABLE payment_flow(
| order_id BIGINT,
| pay_money BIGINT
|) WITH (
| 'connector' = 'kafka',
| 'topic' = 'payment_flow',
| 'properties.bootstrap.servers' = 'hdp0001:9092,hdp0002:9092,hdp0003:9092',
| 'properties.group.id' = 'gid-sql-payment',
| -- 为了便于演示,在这使用latest-offset,每次启动都使用最新的数据
| 'scan.startup.mode' = 'latest-offset',
| 'format' = 'json',
| 'json.fail-on-missing-field' = 'false',
| 'json.ignore-parse-errors' = 'true'
|)
|""".stripMargin
//执行sql字符串
tEnv.executeSql(PaymentFlowTableSql)
//结果表
//定义sql字符串
val resTableSql =
"""
|CREATE TABLE order_payment(
| order_id BIGINT,
| d_timestamp TIMESTAMP_LTZ(3),
| pay_money BIGINT
|) WITH (
| 'connector' = 'kafka',
| 'topic' = 'order_payment',
| 'properties.bootstrap.servers' = 'hdp0001:9092,hdp0002:9092,hdp0003:9092',
| 'format' = 'json',
| 'sink.partitioner' = 'default'
|)
|""".stripMargin
//执行sql字符串
tEnv.executeSql(resTableSql)
//关联订单表和支付表
val joinSql =
"""
|INSERT INTO order_payment
|SELECT
| uo.order_id,
| uo.d_timestamp,
| pf.pay_money
|FROM user_order AS uo
|-- 这里使用INNER JOIN 或者 JOIN 是一样的效果
|INNER JOIN payment_flow AS pf ON uo.order_id = pf.order_id
|""".stripMargin
//执行sql字符串
tEnv.executeSql(joinSql)
}
}阿里云kafka集群的操作记录
cd /opt/cloudera/parcels/CDH/lib/kafka
-- 实操 regular join - inner join
user_order
payment_flow
order_payment
#创建topic (生效)
bin/kafka-topics.sh --create --topic user_order --zookeeper localhost:2181 --partitions 3 --replication-factor 3
bin/kafka-topics.sh --create --topic payment_flow --zookeeper localhost:2181 --partitions 3 --replication-factor 3
bin/kafka-topics.sh --create --topic order_payment --zookeeper localhost:2181 --partitions 3 --replication-factor 3
#打开生产者 user_order 表结构 order_id BIGINT, ts BIGINT, d_timestamp AS TO_TIMESTAMP_LTZ(ts,3)
bin/kafka-console-producer.sh --topic user_order --broker-list hdp0001:9092,hdp0002:9092,hdp0003:9092
{"order_id":1001,"ts":1719030376000} 2024-06-22 12:26:16
{"order_id":1002,"ts":1719030376100}
{"order_id":1003,"ts":1719030376100}
{"order_id":1003,"ts":1719035589000}
#打开生产者 payment_flow 表结构 order_id BIGINT, pay_money BIGINT
bin/kafka-console-producer.sh --topic payment_flow --broker-list hdp0001:9092,hdp0002:9092,hdp0003:9092
{"order_id":1002,pay_money:10000}
{"order_id":1001,pay_money:9000}
{"order_id":1003,pay_money:8000}
#打开消费者
bin/kafka-console-consumer.sh --bootstrap-server hdp0001:9092,hdp0002:9092,hdp0003:9092 --topic order_payment
bin/kafka-console-consumer.sh --bootstrap-server hdp0001:9092,hdp0002:9092,hdp0003:9092 --topic user_order
bin/kafka-console-consumer.sh --bootstrap-server hdp0001:9092,hdp0002:9092,hdp0003:9092 --topic payment_flow
regular join - inner join使用sql92语法进行关联的示例
//关联订单表和支付表
val joinSql =
"""
|INSERT INTO order_payment
|SELECT
| uo.order_id,
| uo.d_timestamp,
| pf.pay_money
|FROM user_order AS uo, payment_flow AS pf
|WHERE uo.order_id = pf.order_id
|""".stripMargin
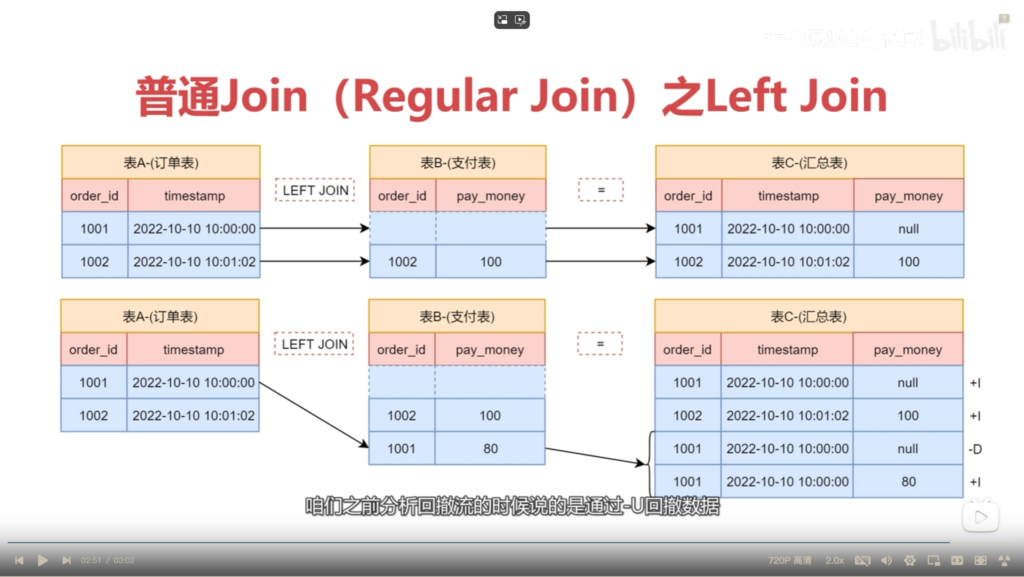
tEnv.executeSql(joinSql)regular join 中的left Join 原理图解
package com.imooc.scala.sqljoin
import java.time.ZoneId
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment}
/**
* 普通Join(Regular Join)之 Left Join
* Created by xuwei
*/
object RegularJoin_LeftJoin {
def main(args: Array[String]): Unit = {
//创建执行环境
val settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build()
val tEnv = TableEnvironment.create(settings)
//指定国内的时区
tEnv.getConfig.setLocalTimeZone(ZoneId.of("Asia/Shanghai"))
//订单表
val UserOrderTableSql =
"""
|CREATE TABLE user_order(
| order_id BIGINT,
| ts BIGINT,
| d_timestamp AS TO_TIMESTAMP_LTZ(ts,3)
| -- 注意:d_timestamp的值可以从原始数据中取,原始数据中没有的话也可以从Kafka的元数据中取
| -- d_timestamp TIMESTAMP_LTZ(3) METADATA FROM 'timestamp'
|)WITH(
| 'connector' = 'kafka',
| 'topic' = 'user_order',
| 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
| 'properties.group.id' = 'gid-sql-order',
| -- 为了便于演示,在这使用latest-offset,每次启动都使用最新的数据
| 'scan.startup.mode' = 'latest-offset',
| 'format' = 'json',
| 'json.fail-on-missing-field' = 'false',
| 'json.ignore-parse-errors' = 'true'
|)
|""".stripMargin
tEnv.executeSql(UserOrderTableSql)
//支付表
val PaymentFlowTableSql =
"""
|CREATE TABLE payment_flow(
| order_id BIGINT,
| pay_money BIGINT
|)WITH(
| 'connector' = 'kafka',
| 'topic' = 'payment_flow',
| 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
| 'properties.group.id' = 'gid-sql-payment',
| -- 为了便于演示,在这使用latest-offset,每次启动都使用最新的数据
| 'scan.startup.mode' = 'latest-offset',
| 'format' = 'json',
| 'json.fail-on-missing-field' = 'false',
| 'json.ignore-parse-errors' = 'true'
|)
|""".stripMargin
tEnv.executeSql(PaymentFlowTableSql)
//结果表
val resTableSql =
"""
|CREATE TABLE order_payment(
| order_id BIGINT NOT NULL,
| d_timestamp TIMESTAMP_LTZ(3),
| pay_money BIGINT,
| PRIMARY KEY(order_id) NOT ENFORCED
|)WITH(
| 'connector' = 'upsert-kafka',
| 'topic' = 'order_payment',
| 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
| 'key.format' = 'json',
| 'value.format' = 'json'
|)
|""".stripMargin
tEnv.executeSql(resTableSql)
//关联订单表和支付表
val joinSql =
"""
|INSERT INTO order_payment
|SELECT
| uo.order_id,
| uo.d_timestamp,
| pf.pay_money
|FROM user_order AS uo
|-- 这里使用LEFT JOIN 或者LEFT OUTER JOIN 是一样的效果
|LEFT JOIN payment_flow AS pf ON uo.order_id = pf.order_id
|""".stripMargin
tEnv.executeSql(joinSql)
}
}
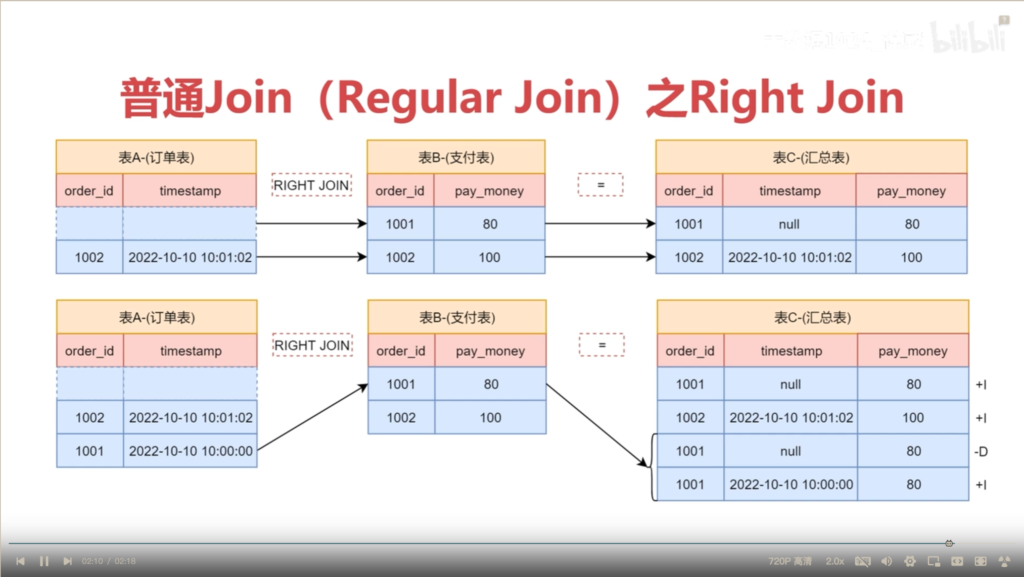
regular join 中的right Join 原理图解
package com.imooc.scala.sqljoin
import java.time.ZoneId
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment}
/**
* 普通Join(Regular Join)之 Right Join
* Created by xuwei
*/
object RegularJoin_RightJoin {
def main(args: Array[String]): Unit = {
//创建执行环境
val settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build()
val tEnv = TableEnvironment.create(settings)
//指定国内的时区
tEnv.getConfig.setLocalTimeZone(ZoneId.of("Asia/Shanghai"))
//订单表
val UserOrderTableSql =
"""
|CREATE TABLE user_order(
| order_id BIGINT,
| ts BIGINT,
| d_timestamp AS TO_TIMESTAMP_LTZ(ts,3)
| -- 注意:d_timestamp的值可以从原始数据中取,原始数据中没有的话也可以从Kafka的元数据中取
| -- d_timestamp TIMESTAMP_LTZ(3) METADATA FROM 'timestamp'
|)WITH(
| 'connector' = 'kafka',
| 'topic' = 'user_order',
| 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
| 'properties.group.id' = 'gid-sql-order',
| -- 为了便于演示,在这使用latest-offset,每次启动都使用最新的数据
| 'scan.startup.mode' = 'latest-offset',
| 'format' = 'json',
| 'json.fail-on-missing-field' = 'false',
| 'json.ignore-parse-errors' = 'true'
|)
|""".stripMargin
tEnv.executeSql(UserOrderTableSql)
//支付表
val PaymentFlowTableSql =
"""
|CREATE TABLE payment_flow(
| order_id BIGINT,
| pay_money BIGINT
|)WITH(
| 'connector' = 'kafka',
| 'topic' = 'payment_flow',
| 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
| 'properties.group.id' = 'gid-sql-payment',
| -- 为了便于演示,在这使用latest-offset,每次启动都使用最新的数据
| 'scan.startup.mode' = 'latest-offset',
| 'format' = 'json',
| 'json.fail-on-missing-field' = 'false',
| 'json.ignore-parse-errors' = 'true'
|)
|""".stripMargin
tEnv.executeSql(PaymentFlowTableSql)
//结果表
val resTableSql =
"""
|CREATE TABLE order_payment(
| order_id BIGINT NOT NULL,
| d_timestamp TIMESTAMP_LTZ(3),
| pay_money BIGINT,
| PRIMARY KEY(order_id) NOT ENFORCED
|)WITH(
| 'connector' = 'upsert-kafka',
| 'topic' = 'order_payment',
| 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
| 'key.format' = 'json',
| 'value.format' = 'json'
|)
|""".stripMargin
tEnv.executeSql(resTableSql)
//关联订单表和支付表
val joinSql =
"""
|INSERT INTO order_payment
|SELECT
| pf.order_id,
| uo.d_timestamp,
| pf.pay_money
|FROM user_order AS uo
|-- 这里使用RIGHT JOIN 或者RIGHT OUTER JOIN 是一样的效果
|RIGHT JOIN payment_flow AS pf ON uo.order_id = pf.order_id
|""".stripMargin
tEnv.executeSql(joinSql)
}
}
regular join 中的full Join 原理图解

package com.imooc.scala.sqljoin
import java.time.ZoneId
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment}
/**
* 普通Join(Regular Join)之 Full Join
* Created by xuwei
*/
object RegularJoin_FullJoin {
def main(args: Array[String]): Unit = {
//创建执行环境
val settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build()
val tEnv = TableEnvironment.create(settings)
//指定国内的时区
tEnv.getConfig.setLocalTimeZone(ZoneId.of("Asia/Shanghai"))
//订单表
val UserOrderTableSql =
"""
|CREATE TABLE user_order(
| order_id BIGINT,
| ts BIGINT,
| d_timestamp AS TO_TIMESTAMP_LTZ(ts,3)
| -- 注意:d_timestamp的值可以从原始数据中取,原始数据中没有的话也可以从Kafka的元数据中取
| -- d_timestamp TIMESTAMP_LTZ(3) METADATA FROM 'timestamp'
|)WITH(
| 'connector' = 'kafka',
| 'topic' = 'user_order',
| 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
| 'properties.group.id' = 'gid-sql-order',
| -- 为了便于演示,在这使用latest-offset,每次启动都使用最新的数据
| 'scan.startup.mode' = 'latest-offset',
| 'format' = 'json',
| 'json.fail-on-missing-field' = 'false',
| 'json.ignore-parse-errors' = 'true'
|)
|""".stripMargin
tEnv.executeSql(UserOrderTableSql)
//支付表
val PaymentFlowTableSql =
"""
|CREATE TABLE payment_flow(
| order_id BIGINT,
| pay_money BIGINT
|)WITH(
| 'connector' = 'kafka',
| 'topic' = 'payment_flow',
| 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
| 'properties.group.id' = 'gid-sql-payment',
| -- 为了便于演示,在这使用latest-offset,每次启动都使用最新的数据
| 'scan.startup.mode' = 'latest-offset',
| 'format' = 'json',
| 'json.fail-on-missing-field' = 'false',
| 'json.ignore-parse-errors' = 'true'
|)
|""".stripMargin
tEnv.executeSql(PaymentFlowTableSql)
//结果表
val resTableSql =
"""
|CREATE TABLE order_payment(
| order_id BIGINT NOT NULL,
| d_timestamp TIMESTAMP_LTZ(3),
| pay_money BIGINT,
| PRIMARY KEY(order_id) NOT ENFORCED
|)WITH(
| 'connector' = 'upsert-kafka',
| 'topic' = 'order_payment',
| 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
| 'key.format' = 'json',
| 'value.format' = 'json'
|)
|""".stripMargin
tEnv.executeSql(resTableSql)
//关联订单表和支付表
val joinSql =
"""
|INSERT INTO order_payment
|SELECT
| case when pf.order_id is null then uo.order_id else pf.order_id end,
| uo.d_timestamp,
| pf.pay_money
|FROM user_order AS uo
|-- 这里使用FULL JOIN 或者FULL OUTER JOIN 是一样的效果
|FULL JOIN payment_flow AS pf ON uo.order_id = pf.order_id
|""".stripMargin
tEnv.executeSql(joinSql)
}
}