

推荐学习视频 – 1-9-1 FlinkSQL之窗口Join(Window Join)介绍_哔哩哔哩_bilibili
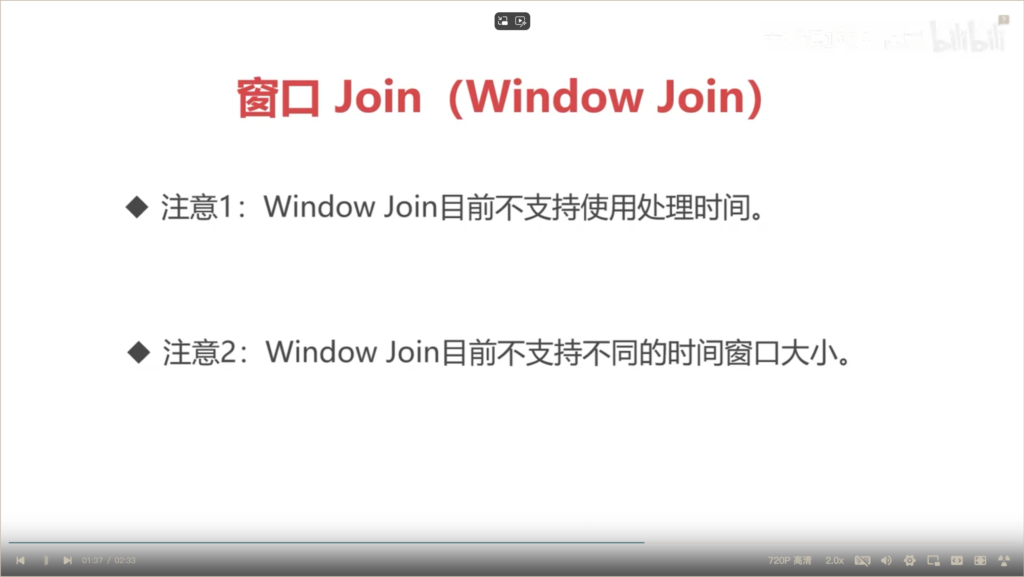
使用条件
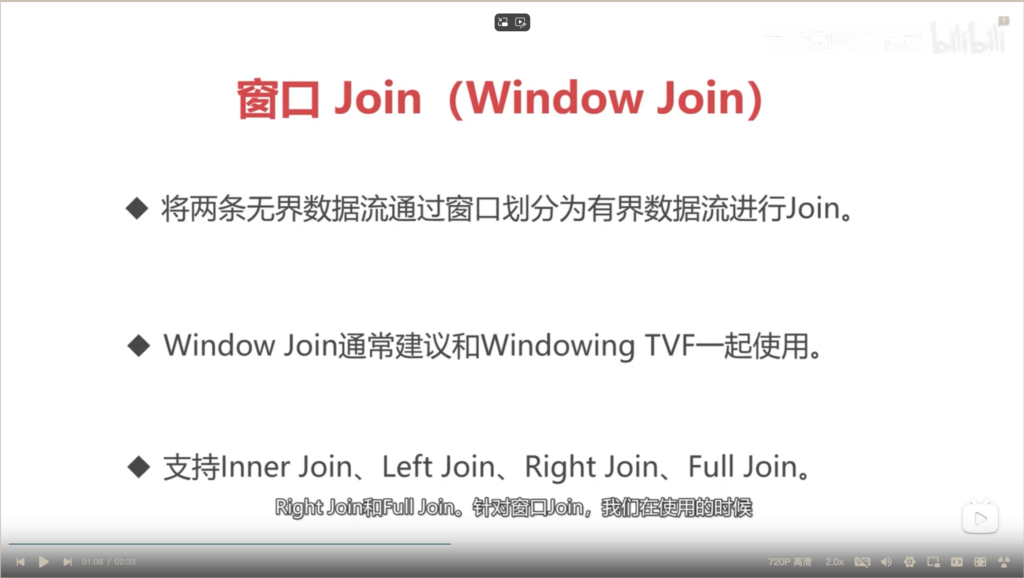
窗口Join原理图解

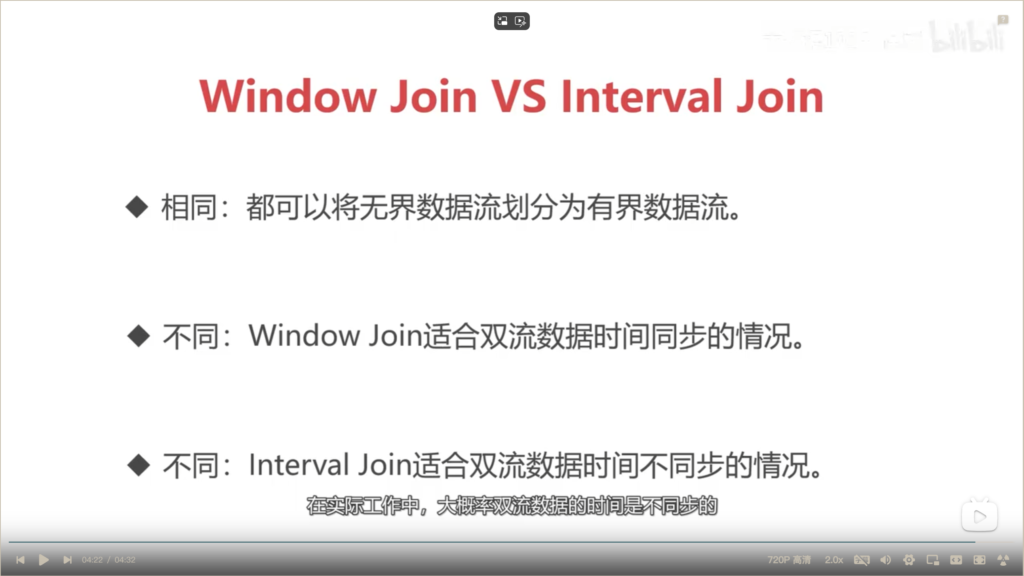
Window Join 和 Interval Join的区别
Window Join代码示例
package com.imooc.scala.sqljoin
import java.time.ZoneId
import org.apache.flink.configuration.CoreOptions
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment}
/**
* 滚动窗口Join
* Created by xuwei
*/
object TumbleWindowJoin_WindowTVF {
def main(args: Array[String]): Unit = {
//创建执行环境
val settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build()
val tEnv = TableEnvironment.create(settings)
//设置全局并行度为1--为了便于验证窗口触发的效果
tEnv.getConfig.set(CoreOptions.DEFAULT_PARALLELISM.key(),"1")
//指定国内的时区
tEnv.getConfig.setLocalTimeZone(ZoneId.of("Asia/Shanghai"))
//设置Source自动置为idle的时间--如果数据源可以一直正常产生数据,则不需要配置此参数!!!
tEnv.getConfig.set("table.exec.source.idle-timeout","10s")
//订单表
val UserOrderTableSql =
"""
|CREATE TABLE user_order(
| order_id BIGINT,
| order_type STRING,
| ts BIGINT,
| order_time AS TO_TIMESTAMP_LTZ(ts,3),
| -- 指定最大允许乱序的时间是10S
| WATERMARK FOR order_time AS order_time - INTERVAL '10' SECOND
|)WITH(
| 'connector' = 'kafka',
| 'topic' = 'user_order',
| 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
| 'properties.group.id' = 'gid-sql-order',
| -- 为了便于演示,在这使用latest-offset,每次启动都使用最新的数据
| 'scan.startup.mode' = 'latest-offset',
| 'format' = 'json',
| 'json.fail-on-missing-field' = 'false',
| 'json.ignore-parse-errors' = 'true'
|)
|""".stripMargin
tEnv.executeSql(UserOrderTableSql)
//支付表
val PaymentFlowTableSql =
"""
|CREATE TABLE payment_flow(
| order_id BIGINT,
| pay_money BIGINT,
| ts BIGINT,
| pay_time AS TO_TIMESTAMP_LTZ(ts,3),
| -- 指定最大允许乱序的时间是10S
| WATERMARK FOR pay_time AS pay_time - INTERVAL '10' SECOND
|)WITH(
| 'connector' = 'kafka',
| 'topic' = 'payment_flow',
| 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
| 'properties.group.id' = 'gid-sql-payment',
| -- 为了便于演示,在这使用latest-offset,每次启动都使用最新的数据
| 'scan.startup.mode' = 'latest-offset',
| 'format' = 'json',
| 'json.fail-on-missing-field' = 'false',
| 'json.ignore-parse-errors' = 'true'
|)
|""".stripMargin
tEnv.executeSql(PaymentFlowTableSql)
//结果表
val resTableSql =
"""
|CREATE TABLE order_payment(
| order_id BIGINT,
| order_type STRING,
| order_time TIMESTAMP_LTZ(3),
| pay_money BIGINT,
| -- 结果表中只能保留数据流中的一个事件时间字段(order_time or pay_time)
| -- 如果有多个,需要把其他的事件时间字段类型改为TIMESTAMP或者TIMESTAMP_LTZ
| pay_time TIMESTAMP_LTZ
|)WITH(
| 'connector' = 'kafka',
| 'topic' = 'order_payment',
| 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
| 'format' = 'json',
| 'sink.partitioner' = 'default'
|)
|""".stripMargin
tEnv.executeSql(resTableSql)
//关联订单表和支付表
val joinSql =
"""
|INSERT INTO order_payment
|SELECT
| l.order_id,
| l.order_type,
| l.order_time,
| r.pay_money,
| r.pay_time
|FROM (
| SELECT *
| FROM TABLE(TUMBLE(TABLE user_order,DESCRIPTOR(order_time),INTERVAL '3' SECOND))
|) AS l
|INNER JOIN(
| SELECT *
| FROM TABLE(TUMBLE(TABLE payment_flow,DESCRIPTOR(pay_time),INTERVAL '3' SECOND))
|) AS r
|ON l.order_id = r.order_id
|AND l.window_start = r.window_start
|AND l.window_end = r.window_end
|""".stripMargin
tEnv.executeSql(joinSql)
}
}