
学习资料 – 第六章 Flink编程模型与API 枫叶云笔记 (fynote.com)
Flink 算子分三大类
Source 输入算子
Transformation 转换算子
Sink 输出算子Source算子整理
File Source
env.readTextFile(filePath)/** * Flink 读取文件最新写法 */ FileSource<String> fileSource = FileSource.forRecordStreamFormat( new TextLineInputFormat(), new Path("hdfs://mycluster/flinkdata/data.txt")).build();Socket Source
Kafka Source
val kafkaSource: KafkaSource[String] = KafkaSource.builder[String]() .setBootstrapServers("node1:9092,node2:9092,node3:9092") //设置Kafka集群Brokers .setTopics("testtopic") //设置topic .setGroupId("my-test-group") //设置消费者组 .setStartingOffsets(OffsetsInitializer.latest()) // 读取位置 .setValueOnlyDeserializer(new SimpleStringSchema()) //设置Value的反序列化格式 .build()自定义 Source
Flink Transformation 算子整理
map
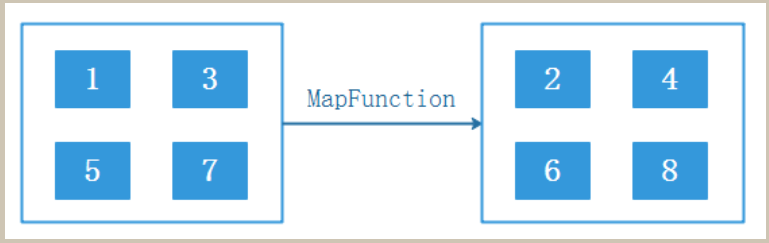
val ds: DataStream[Int] = env.fromCollection(List(1, 3, 5, 7))
val result: DataStream[Int] = ds.map(_ + 1)map是对单个数据元素做出相应处理,是One to One 的算子。最终数据量不变
flatMap
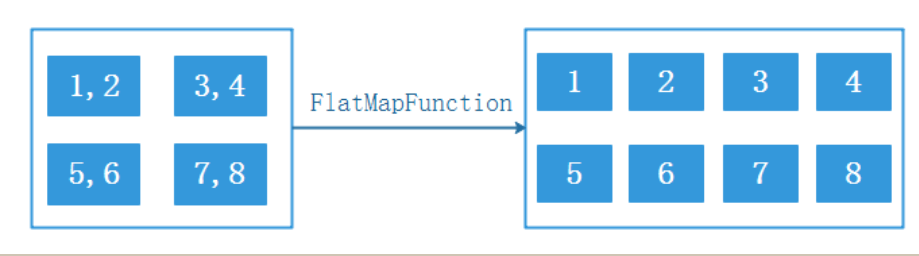
val ds: DataStream[String] = env.fromCollection(List("1,2", "3,4", "5,6", "7,8")) ds.flatMap(_.split(",")).print()数据经过flatmap操作之后,会切分成多行。比如“1,2” 经过flatmap(_.split(“,”)) 之后,会变成两行数据,1和2
Filter
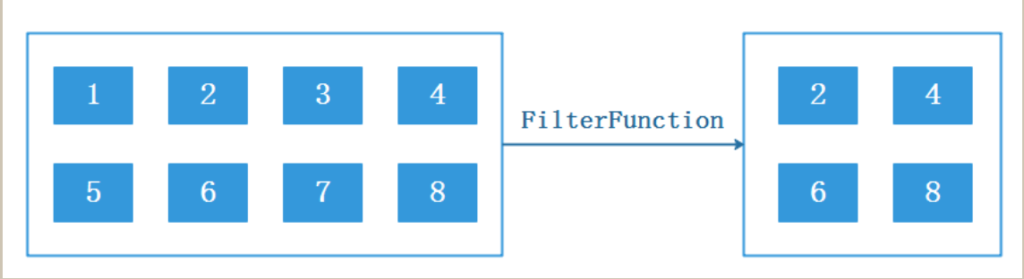
val stream = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9) stream.filter(_ % 2 == 0).print()对数据做出条件筛选。等同于sql中的where条件过滤
keyBy
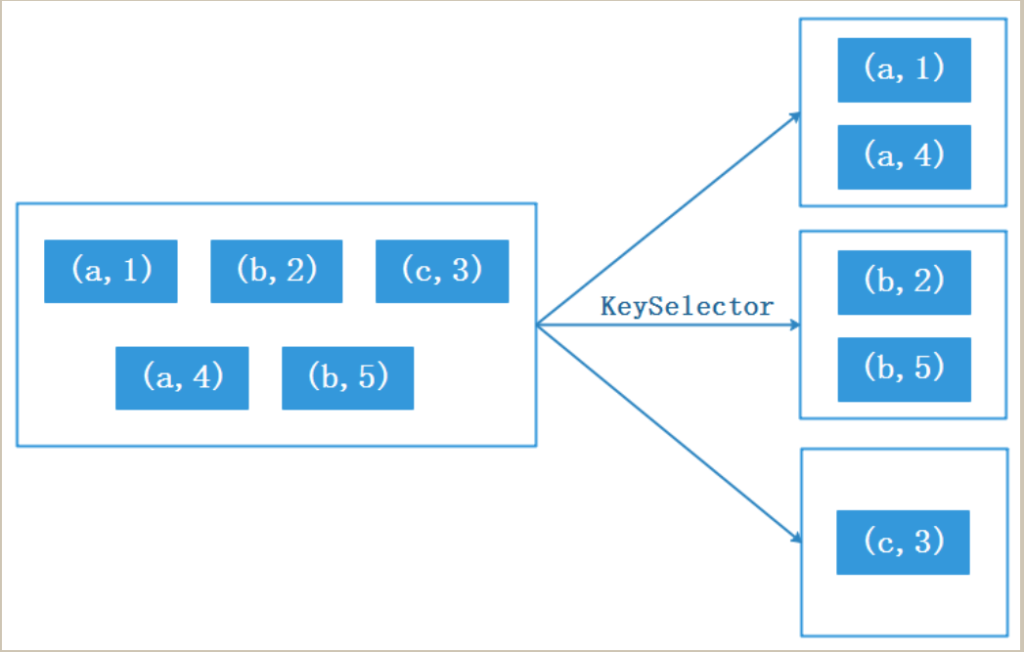
val ds: DataStream[(String, Int)] = env.fromCollection(List(("a", 1), ("b", 2), ("c", 3), ("a", 4), ("b", 5)))
ds.keyBy(tp=>{tp._1}).sum(1).print()Aggregations
Flink提供了多种聚合函数,包括sum、min、minBy、max、maxBy,这些函数都是常见的聚合操作,作用如下:
1.sum:针对输入keyedStream对指定列进行sum求和操作。
2.min:针对输入keyedStream对指定列进行min最小值操作,结果流中其他列保持最开始第一条数据的值。
3.minBy:同min类似,对指定的字段进行min最小值操作minBy返回的是最小值对应的整个对象。
4.max:针对输入keyedStream对指定列进行max最大值操作,结果流中其他列保持最开始第一条数据的值。
5.maxBy:同max类似,对指定的字段进行max最大值操作,maxBy返回的是最大值对应的整个对象。//统计duration 的总和
keyedStream.sum("duration").print
//统计duration的最小值,min返回该列最小值,其他列与第一条数据保持一致
keyedStream.min("duration").print
//统计duration的最小值,minBy返回的是最小值对应的整个对象 keyedStream.minBy("duration").print
//统计duration的最大值,max返回该列最大值,其他列与第一条数据保持一致
keyedStream.max("duration").print
//统计duration的最大值,maxBy返回的是最大值对应的整个对象 keyedStream.maxBy("duration").printreduce
reduce算子是一种聚合算子,它接受一个函数作为参数,并将输入的KeyedStream中的元素进行两两聚合操作,该函数将两个相邻的元素作为输入参数,并生成一个新的DataStream数据流作为输出
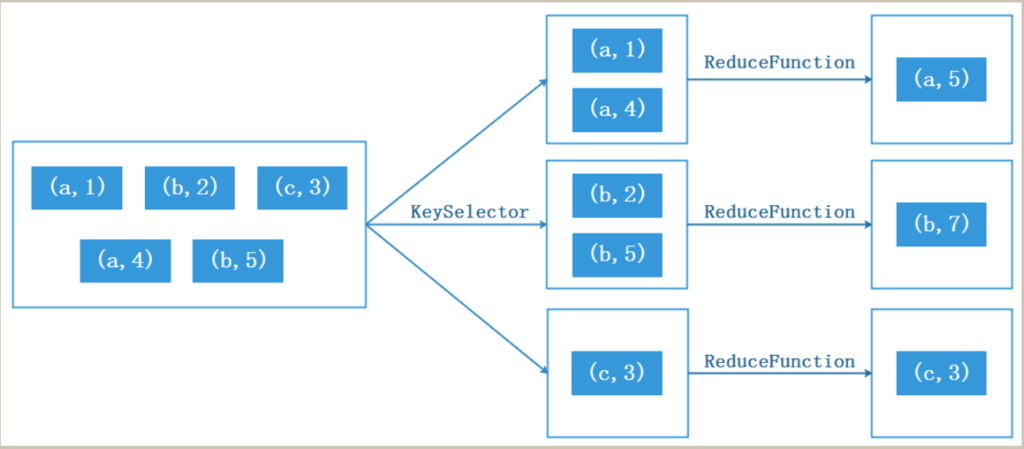
val ds: DataStream[(String, Int)] = env.fromCollection(List(("a", 1), ("b", 2), ("c", 3), ("a", 4), ("b", 5)))
ds.keyBy(tp=>{tp._1}) .reduce((v1,v2)=>{(v1._1,v1._2+v2._2)}).print()union
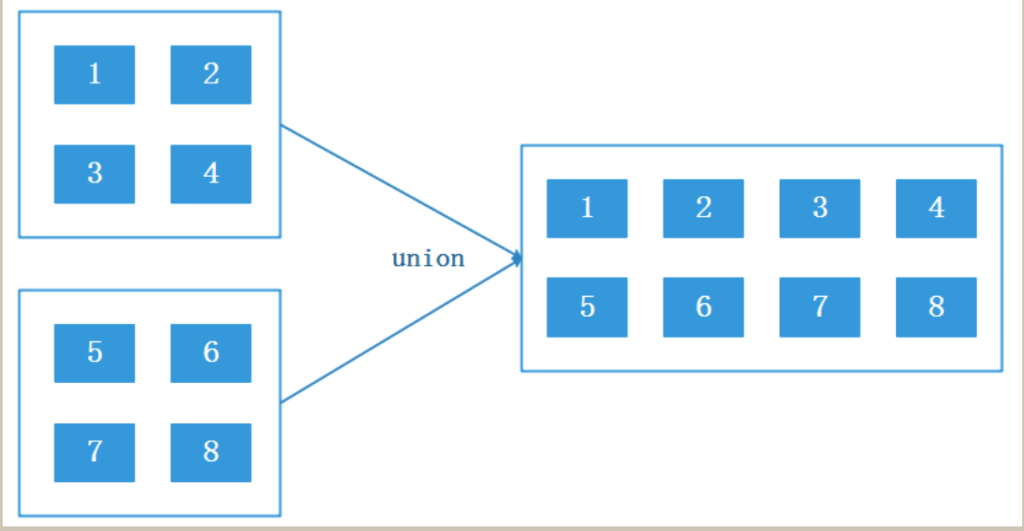
val ds1: DataStream[Int] = env.fromCollection(List(1, 2, 3, 4))
val ds2: DataStream[Int] = env.fromCollection(List(5, 6, 7, 8)) ds1.union(ds2).print()connect
connect算子将两个输入的DataStream数据流作为参数,将两个不同数据类型的DataStream数据流连接在一起,生成一个ConnectedStreams对象作为结果,与union算子不同,union只是简单的将两个类型一样的流合并在一起,而connect算子可以将不同类型的DataStream连接在一起,并且connect只能连接两个流。
connect生成的结果保留了两个输入流的类型信息,例如:dataStream1数据集为(String, Int)元祖类型,dataStream2数据集为Int类型,通过connect连接算子将两个不同数据类型的流结合在一起,其内部数据为[(String, Int), Int]的混合数据类型,保留了两个原始数据集的数据类型。
对于连接后的数据流可以使用map、flatMap、process等算子进行操作,但内部方法使用的是CoMapFunction、CoFlatMapFunction、CoProcessFunction等函数来进行处理,这些函数称作“协处理函数”,分别接收两个输入流中的元素,并生成一个新的数据流作为输出,输出结果DataStream类型保持一致。
val ds1: DataStream[(String, Int)] = env.fromCollection(List(("a", 1), ("b", 2), ("c", 3))) val ds2: DataStream[String] = env.fromCollection(List("aa","bb","cc")) //connect连接两个流,两个流的数据类型可以不一样
val result: DataStream[(String, Int)] = ds1.connect(ds2).map(tp => tp, value => {(value, 1)})iterate
iterate算子用于实现迭代计算的算子,它允许对输入的DataStream进行多次迭代操作,直到迭代条件不满足时迭代停止,该算子适合迭代计算场景,例如:机器学习中往往会对损失函数进行判断是否到达某个精度来判断训练是否需要结束就可以使用该算子来完成。
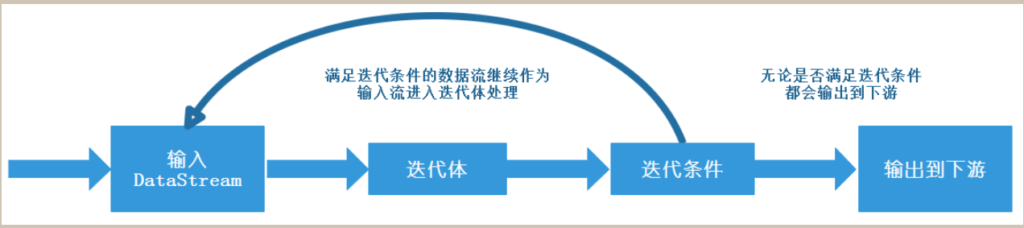
该算子接受一个初始输入流作为起点,整个迭代过程由两部分组成:迭代体和迭代条件,迭代体负责对输入的数据流进行处理,迭代条件用来判断本次流是否应该继续作为输入流反馈给迭代体继续迭代,满足条件的数据会继续作为输入流进入迭代体进行迭代计算直到不满足迭代条件为止。注意:无论数据流是否满足迭代条件都会输出到下游。
//定义迭代流,并指定迭代体和迭代条件
val result: DataStream[Int] = ds2.iterate( iteration => { //定义迭代体
val minusOne: DataStream[Int] = iteration.map(v => {println("迭代体中value值为:"+v);v - 1})
//定义迭代条件,满足的继续迭代
val stillGreaterThanZero: DataStream[Int] = minusOne.filter(_ > 0)
//定义哪些数据最后进行输出
val lessThanZero: DataStream[Int] = minusOne.filter(_ <= 0)
//返回tuple,第一个参数是哪些数据流继续迭代,第二个参数是哪些数据流进行输出 (stillGreaterThanZero, lessThanZero) })函数接口
富函数类
所有RichFunction中有一个生命周期的概念,典型的生命周期方法有:
open()方法是rich function的初始化方法,当一个算子例如map或者filter被调用之前open()会被调用,一般用于初始化资源。
close()方法是生命周期中的最后一个调用的方法,做一些清理工作。
getRuntimeContext()方法提供了函数的RuntimeContext的一些信息,例如函数执行的并行度,任务的名字,以及state状态Flink Sink 算子整理
FileSink
JdbcSink
at-least-once语义
exactly-once语义KafkaSink
只写出value
写出Key、Value数据
只有keyRedisSink
自定义Sink输出
DataStream分区操作
Flink内部提供了常见的分区策略有如下8种:
哈希分区(Hash partitioner)
随机分区(shuffle partitioner)
轮询分区(reblance partitioner)
重缩放分区(rescale partitioner)
广播分区(broadcast partitioner)
全局分区(global partitioner)
并行分区(forward partitioner)
自定义分区默认情况下,Flink使用轮询方式(rebalance partitioner)将数据从上游分发到下游算子。然而,在某些情况下,用户可能希望自己控制分区,例如在数据倾斜的场景中,为了实现这种控制,可以使用预定义的分区策略或自定义分区策略来决定数据的流转和处理方式。
keyBy哈希分区
在Flink中可以对DataStream调用KeyBy方法来使用hash partitioner,该方法需要指定一个key,对该key进行hash计算然后与下游task个数取模来决定数据应该被下游哪些分区task处理。shuffle随机分区
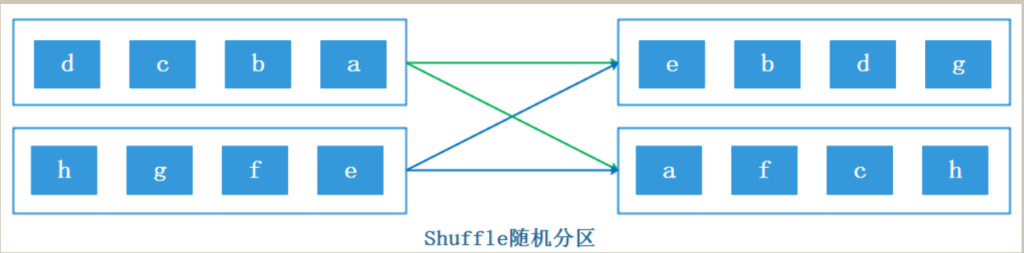
val ds: DataStream[String] = env.socketTextStream("node5", 9999) ds.shuffle.print().setParallelism(3)rebalance轮询分区
在Flink中可以对DataStream调用rebalance方法来使用reblance partitioner分区策略对数据进行轮询重分区,这种分区方式采用RoundRobin负载均衡算法保证每个分区的数据平衡,当数据出现倾斜时可以使用这种分区策略对数据进行重分区。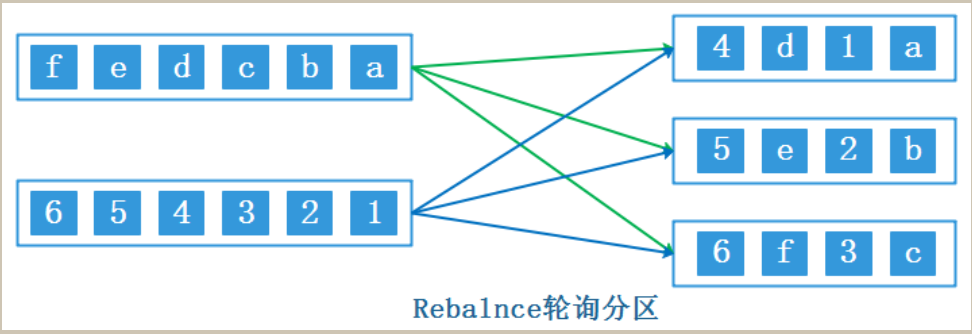
Flink中改变并行度默认采用的就是rebalance partitioner分区策略。
rebalance partitioner分区策略会对数据全局性的通过网络传输实现数据轮询重分区,网络开销大val ds: DataStream[String] = env.socketTextStream("node5", 9999) ds.rebalance.print().setParallelism(3)rescale重缩放分区
与rebalance partitioner分区策略类似,rescaling 分区策略也采用RoundRobin负载均衡算法进行重分区,但该分区策略不采用全局性的网络传输来实现数据的重分区,它使用一种本地的分区策略,通过调整任务的数量来改变数据的分配方式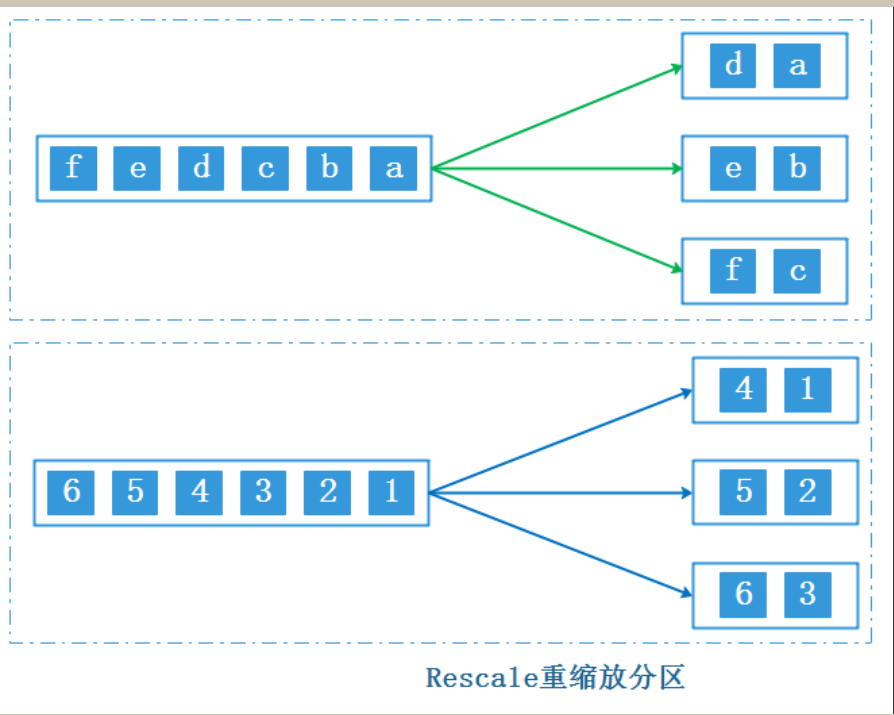
使用rescale 时,建议下游算子并行度是上游算子并行度的整数倍,这样效率比较高
ds.rescale.print("rescale").setParallelism(4)broadcast广播分区
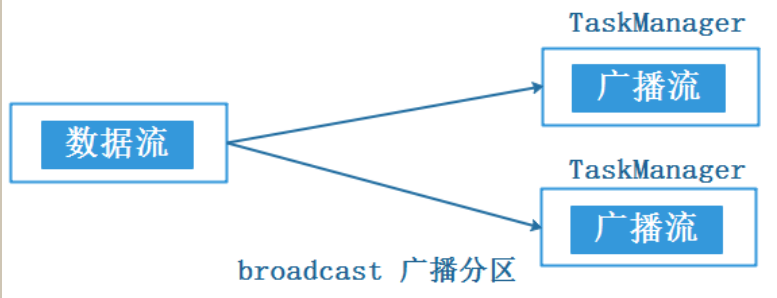
broadcast partitioner 分区策略适合于小数据集广播,例如,当大数据集关联小数据集时,可以通过广播小数据集方式将数据分发到算子的每个分区中
global全局分区
该方法会强制将多个上游task处理的数据发送到下游1个task中处理
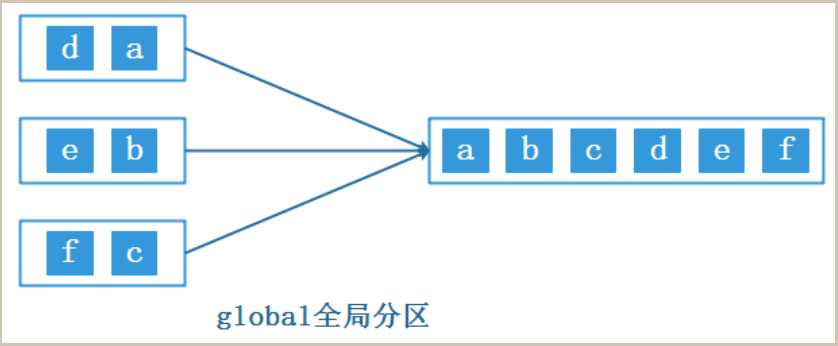
ds.global.print("global")forward并行分区
在Flink中可以对DataStream调用forward方法使用forward partitioner并行分区策略原封不动的将上游分区数据转发到下游分区中,即上游分区数据分发到下游对应分区一对一的数据分发。map、flatMap、filter 等算子上下游并行度一样时默认就是这种分区策略
partitionCustom 自定义分区
Side Output侧输出
在Flink处理数据流时,常常会面临这样的情况:需要对一个数据源进行处理,该数据源包含不同类型的数据,我们需要将其分割处理。使用filter算子对数据源进行筛选分割会导致数据流的多次复制,从而造成不必要的性能浪费。
为了解决这个问题,Flink引入了侧输出(Side Output)机制,该机制可以将数据流进行分割,而无需对流进行复制。
使用侧输出时,用户可以通过定义输出标签(Output Tag)来标识不同的侧输出流。在处理数据流时,通过适当的操作符和条件,可以将特定类型的数据发送到相应的侧输出流。
侧输出适合Flink中流分割处理、异常数据处理、延迟数据处理场景val env = StreamExecutionEnvironment.getExecutionEnvironment
//导入隐式转换
import org.apache.flink.api.scala._
/**
* Socket中的数据格式如下:
* 001,186,187,success,1000,10
* 002,187,186,fail,2000,20
* 003,186,188,success,3000,30
* 004,188,186,success,4000,40
* 005,188,187,busy,5000,50
*/
val ds: DataStream[String] = env.socketTextStream("node5", 9999)
//定义侧输出流的标签
val outputTag: OutputTag[String] = OutputTag[String]("side-output")
val mainStream: DataStream[String] = ds.process((value: String, ctx: ProcessFunction[String, String]#Context, out: Collector[String]) => {
//value 格式:001,186,187,success,1000,10
val split: Array[String] = value.split(",")
val callType: String = split(3) //通话类型
//判断通话类型
if ("success".equals(callType)) {
//成功类型,输出到主流
out.collect(value)
} else {
//其他类型,输出到侧输出流
ctx.output(outputTag, value)
}
})
//获取主流
mainStream.print("主流")
//获取侧输出流
mainStream.getSideOutput(outputTag).print("侧输出流")
env.execute()
ProcessFunction
Flink 的 ProcessFunction 是 DataStream API 中的一个重要组成部分,它允许用户为流数据定义自定义的处理逻辑
ProcessFunction 中有两个核心方法,如下:
processElement() 方法
这个方法用于处理每个元素,对于流中的每个元素,都会调用一次。它的参数包括输入数据值 value、上下文 ctx 和收集器 out。方法没有返回值,处理后的输出数据是通过收集器 out 定义的。
onTimer() 方法
这个方法用于定义定时触发的操作,只有在注册的定时器触发时才会调用。定时器是通过 TimerService 注册的,相当于设定了一个闹钟,到达设定的时间就会触发。