
学习资料 – 第七章 Flink状态管理与容错 枫叶云笔记 (fynote.com)
Flink是一个有状态的流式计算框架,其中的算子任务分为无状态和有状态两种。
无状态算子直接基于当前输入数据进行转换输出,例如map、filter、flatMap等操作
而有状态算子则需要额外的数据来计算结果,例如sum、avg、window等算子
状态保存在内存中,然而,当Flink程序遇到故障时,内存中的状态会丢失,为了确保在程序重启后能正确恢复状态,Flink提供了容错机制,我们可以将状态持久化存储,使其在故障发生时能够被恢复,这就需要通过State Backend (状态后端)实现。
容错是保证Flink程序的健壮性和可靠性的关键部分,通过将状态进行持久化存储,Flink能够在发生故障后重新加载状态并继续处理数据,从而确保数据处理的准确性和完整性。
Flink提供完整的状态管理和容错机制,包括状态存储、访问、持久化、故障恢复等核心功能
Flink 状态分类
在Flink中根据处理的数据是否根据Key进行分区,将Flink管理的状态分为KeyedState(键控状态)和Operator State(算子状态)两种类型,此外还有一种Broadcast State广播状态。KeyedState(键控状态)
KeyedState顾名思义就是基于KeyedStream上的状态,这个状态是跟特定的Key绑定的
相同key的数据会分配到同一个任务被执行,KeyedState说的是KeyedStream流上的每一个Key都对应一个StateFlink针对Keyed State提供了ValueState值状态、ListState列表状态、ReducingState归约状态、AggregatingState聚合状态、MapState映射状态来保存State状态
Keyed State分类
1.ValueState值状态
ValueState可以保存一个可以更新和检索的值,KeyedStream中每个key都对应一个State值。这个值可以通过update(T)进行更新,通过 value()方法进行获取值。
2.ListState列表状态
ListState保存一个元素的列表,可以往这个列表中追加数据,并在当前的列表上进行检索。可以通过add(T)或者addAll(List)进行添加元素,通过Iterable get()获得整个列表,还可以通过update(List)覆盖当前的列表。
3.ReducingState归约状态
保存一个单值,表示添加到状态的所有值的聚合,接口与ListState类似,但使用 add(T)增加元素,会使用提供的ReduceFunction进行聚合。
4.AggregatingState聚合状态
保留一个单值,表示添加到状态的所有值的聚合。和ReducingState不同的是,聚合类型可能与添加到状态的元素的类型不同,也就是IN和OUT类型可以不同。接口与ListState类似,使用add(IN) 添加元素,然后会根据指定的AggregateFunction进行聚合。
5.MapState映射状态
MapState<UK, UV>是一种用于存储键值对数据的状态类型,类似Java Map结构,它可以在流处理作业中维护和更新映射关系,并提供了丰富的方法来操作和查询这些键值对数据,如:put()、get()、contains()、entries()、keys()、values()等。键控状态使用方式
在使用以上各种状态之前都需要进行状态注册, 状态的注册可以通过StateDescriptor(状态描述器)实现,需要指定状态的名称(name)和类型(type),以ValueState注册为例,代码如下:
ValueStateDescriptor<Long> descriptor = new ValueStateDescriptor<>("time", Long.class);
以上注册了一个名称为“time”的Long类型的ValueStateDescriptor状态描述器,在ReducingState、AggregatingState状态描述器中需要用户自定义处理数据的逻辑以达到存储我们想要的状态目的。
此外需要注意的是一个Flink程序中可以有多个状态,但是注册的状态名称不能相同。Flink运行时可以通过注册状态的名称找到该状态。
键控状态生存时间TTL
以上键控状态随着时间的推移,状态大小也会持续增长,默认状态存储在内存中,时间久了就会给内存带来很大压力,我们可以调用.clear()方法直接清除状态,如果业务逻辑不允许使用clear()方法直接清除状态,我们可以通过配置状态的”生存时间”(Time-to-Live,TTL)来限制状态在内存中存在的时间,当状态存在的时间超过设置的TTL时,系统将自动尽快清除该状态,避免状态一直占用内存空间。
OperatorState(算子状态)
Flink中的Operator State(算子状态)用于在算子的并行任务中维护和管理状态信息,与KeyedState键控状态不同,Operator State与Key无关,与并行的操作算子实例相关联,也就是说Flink中每个算子的每个并行度上都会维护一个状态,适用于连接外部系统的算子或没有键定义的场景,但Operator State不如KeyedState状态丰富,所以使用场景较少。
算子状态重分布策略
Even-split Redistribution均衡重分布
每个算子并行实例中含有部分状态元素的List列表,整个状态数据是所有List列表的合集。当调用restore方法进行状态恢复时,通过将全部状态数据以轮询方式平均分配到多个并行实例上来恢复状态。
Union Redistribution联合重分布
每个算子并行实例中含有所有状态元素的List列表。当调用restore方法进行状态恢复时,每个算子并行task都能获取完整的状态数据。
Broadcast State广播状态
Broadcast State广播状态常见的应用场景是动态配置或动态规则。传统的做法是定期扫描配置文件,一旦发现变化就重新加载配置,但这种方式可能会导致配置更新不及时或资源浪费。使用广播状态可以将配置数据视为一条流,与要处理的数据流进行连接,从而实现实时的配置更新和计算。
广播状态是一种全局有效的状态,需要将其广播给所有并行的子任务。每个子任务需要将广播状态作为算子状态进行保存,以保证在故障恢复后处理结果的一致性。广播状态以Key-Value键值对的形式描述,底层采用映射状态(MapState)来实现。
检查点(checkpoint)
Flink的checkpoint是一种实现容错和状态恢复的机制。当Flink程序发生故障并重新启动时,为了确保数据处理的一致性,我们需要对Flink处理数据的状态进行恢复,Flink中状态数据默认存储在JobManager堆内存中,当Flink程序重启后,内存中状态数据会丢失,所以为了实现状态的恢复,必须对状态数据进行持久化存储,Flink提供了checkpoint机制来实现状态的持久化存储。
checkpoint会定期将Flink程序的状态保存到持久化存储系统中,通常是分布式文件系统,当Flink程序发生故障时,可以重新启动应用程序并从之前的状态中恢复,使得Flink程序能够回到故障发生前的一致状态。因此,checkpoint也被称为”一致性检查点”。
checkpoint容错原理
checkpoint容错原理大致是对Flink程序状态进行持久化保存,当Flink程序故障恢复时从保存的状态中进行状态恢复,确保恢复后的Flink程序状态的正确性。checkpoint barrier
checkpoint的核心思想是对Flink程序进行周期性的生成分布式一致性快照(snapshot),生成分布式快照的时间周期用户可以设置,分布式快照可以将同一时间点Task/Operator的状态数据全局统一快照处理,包括前面提到的Keyed State和Operator State。Flink是如何周期性生成snapshot的呢?
Flink会在输入的数据集上间隔性地生成checkpoint barrier(检查点分界线),通过barrier将间隔时间段内的数据划分到相应的checkpoint中,如下图:
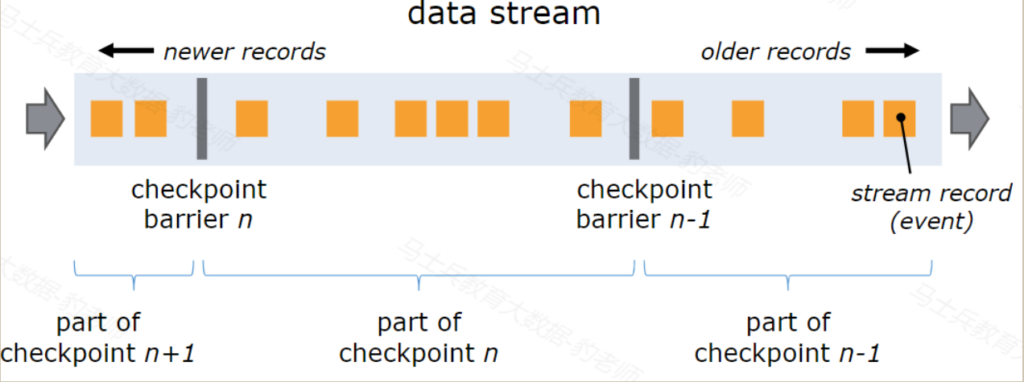
checkpoint barrier是一种特殊的数据,每个barrier都有自己的独立的编号,会随着整个数据流向Flink下游算子传递,当Flink每个算子处理到当前barrier时都会进行snapshot快照保存,该快照会存储在指定的状态后端中。
当所有的Flink算子都对该barrir进行了快照保存,说明当前barrir之前的数据完全被Flink处理完成,这时Flink JobManager中的checkpoint coordinator(检查点协调器)会通知各个TaskManager节点对每个算子生成的snapshot进行统一保存,形成完整的checkpoint检查点。
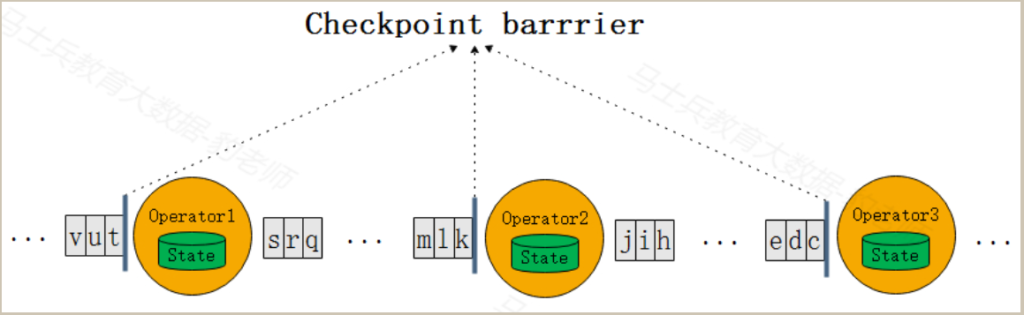
barrier对齐和不对齐机制
当Flink应用程序有多个并行度或者Flink上下游算子并行度不一致时,barrier上下游传递时涉及到barrier广播和barrier对齐机制。
当上游数据向下游多个并行度中发送barrier时,需要对barrier进行广播,保证下游各个并行度barrier一致;当上游多个并行度向下游少量并行度传递barrier时,需要对brrier进行对齐,对齐是指下游每个并行度都要等到相同的barrier到达时才能进行 snapshot 快照状态的保存。
barrier对齐机制的示意图:
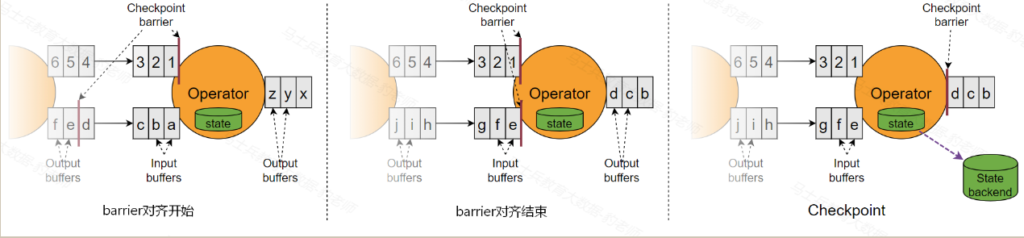
在barrier对齐机制中,下游barrier先到达分区会等待barrier未到达的分区以达到barrier对齐目的,这个对齐过程中就会涉及barrier先到达分区中数据的缓存,如果多个并行度中处理数据的速度不一致会导致下游任务堆积大量缓存数据,可能会造成Flink内存和磁盘负载压力,同时也使Flink 整体Checkpoint的时间延后变长,此外,在Flink中当数据流处理不过来时还会有反压机制(反压机制是指控制数据源的产生速度,避免数据积压),反压机制会限制数据流的流动,导致barrier在一些并行度中流速变慢,这样更近一步导致Checkpoint的时间延后的更长,导致恶性循环。
barrier不对齐机制的示意图:
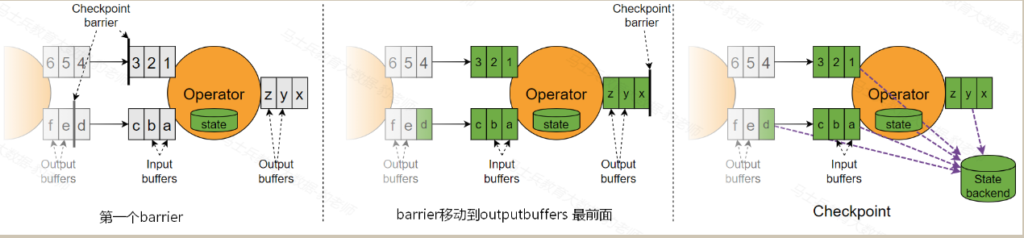
当流速快的barrier到达下游算子的input buffer后,Flink会将该barrier插入到该下游算子的output buffer的最前面,并将该barrier发送给后续的算子。同时当前算子会对自身进行checkpoint快照,包括当前的状态以及所有input buffers、output buffers以及流速慢的barrier之前的数据都会保存到状态后端中(注意:在进行checkpoint快照时,流速慢的barrier会被移除,并不会继续流动下去),这样当Flink应用程序异常中断恢复到此次checkpoint时,未计算之前的状态、barrier不对齐对应的input buffers、output buffers 数据会重新恢复到各个流中并保证数据的一致性和准确。值得注意的是barrier不对齐机制中需要向状态中保持更多的数据。
barrier对齐机制 与 barrier不对齐机制 的优缺点分析:
barrier对齐机制
优点:状态后端需要保存的数据少。
缺点:缓存堆积数据、Flink内存和磁盘负载有压力、checkpoint时间延长。barrier不对齐机制
优点:多并行度中只要有一个并行度中barrier到达,就会触发checkpoint,加快checkpoint进行,不容易出现数据反压问题。
缺点:状态后端保存数据多,状态恢复时比较慢。在Flink中对于简单数据处理作业建议使用轻量级的barrier对齐机制,对于一些计算复杂导致任务出现数据高反压、checkpoint超时难以完成的的作业场景建议使用barrier不对齐机制,这样可以加快checkpoint进行、有效缓解数据高反压带来的一系列连锁问题。
精准一次 和 至少一次消费
Flink程序故障重启后从checkpoint进行恢复时支持exactly once 和 at least once 两种语义。
exactly once 语义下
支持barrier 对齐机制
支持barrier 不对齐机制at least once 语义下
底层实现自动选择的就是checkpoint barrier不对齐机制at least once语义下的barrier不对齐机制与exactly once 语义下barrier不对齐机制触发checkpoint时机不同。
checkpoint barrier 不对齐机制触发实际对比
exactly once
根据流速快的barrier进行触发at least once
根据流速慢的barrier进行触发在at least once 语义中默认使用的就是barrier不对齐机制,这种语义下不会阻塞数据加大checkpoint的处理时间,但会造成数据重复消费问题。
Checkpoint状态恢复
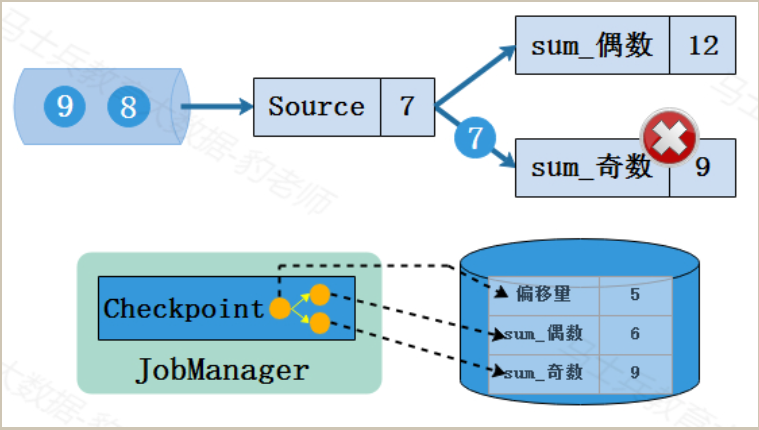
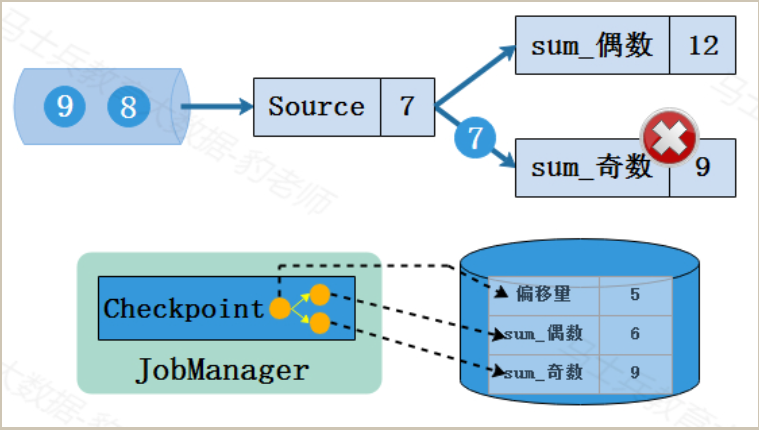
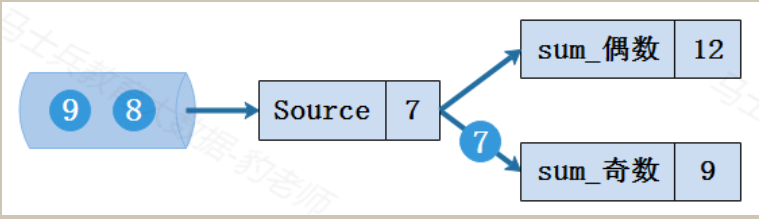
正常处理数据流的Flink程序遇到故障失败,此时保存在checkpoint检查点中状态如下图所示,从最后保存的Checkpoint状态来看,数据处理偏移量为5,偶数和为6(2+4),奇数和为9(1+3+5),虽然Flink程序遇到故障时Source读取到的偏移量为7并向下游传递了数字7,由于后续操作并没有累加数字7,所以该偏移量并没有保存到状态中。
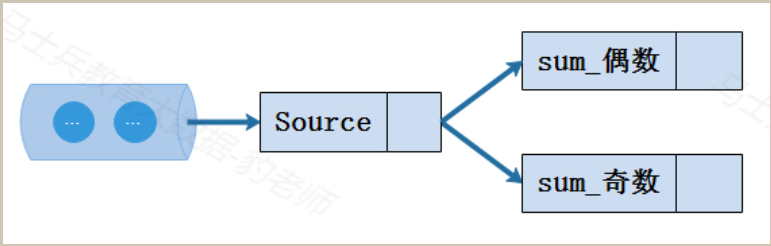
下面对Flink程序重启从checkpoint中恢复状态的过程进行描述。首先Flink重启后所有状态都为空,如下图所示:
程序重启后,从checkpoint检查点进行状态恢复。Flink程序会从最后一次保存完整的checkpoint检查点进行恢复,填充到对应的Flink状态中。如下图所示,该程序从状态中恢复数据并从偏移量为5的位置继续读取数据,如下:
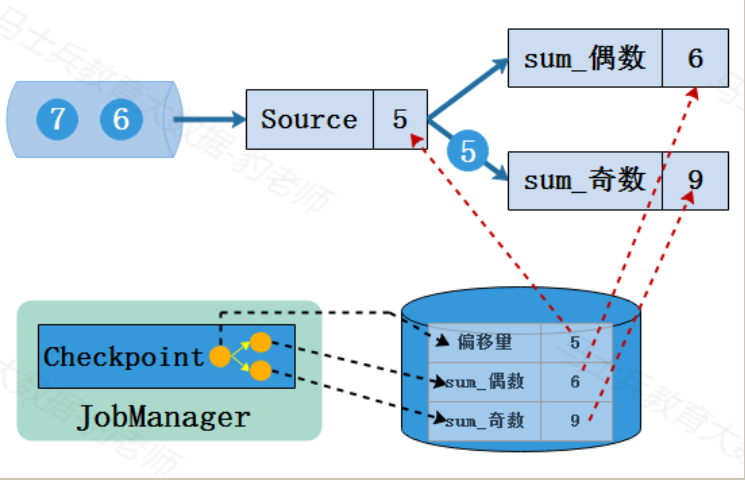
经过以上步骤就完成了Flink从故障恢复状态的过程,后续会继续按照读取的偏移量进行数据的处理,并继续周期性进行checkpoint检查点对状态进行保存,如下:
经过以上步骤可以看到,Flink故障重启后可以从checkpoint中进行状态恢复实现容错,无缝达到Flink故障之前处理情况,整个过程既没有丢掉数据,也没有重复处理数据,保证了最终结果的一致性。
Checkpoint参数及设置
默认情况下,Flink中没有开启Checkpoint检查点,用户需要通过在Flink程序中调用如下方法开启Checkpoint检查点。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//开启Checkpoint检查点,每1秒钟做一次Checkpoint
env.enableCheckpointing(1000);
checkpoint存储(checkpoint storage)
可以设置Checkpoint检查点快照(SnapShot)存储的位置
可以选择JobManagerCheckpointStorage或者FileSystemCheckpointStorage,两者分别代表JobManager堆内存和文件系统。
默认情况下,snapshot 存储在JobManager的堆内存中,建议改为持久化文件系统。Flink设置Checkpoint storage检查点存储位置代码如下:
//设置checkpoint storage存储为JobManagerStorage,默认堆内存存储状态大小为5M
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage(5*1024*1024));
//设置checkpoint storage存储为hdfs路径
env.getCheckpointConfig().setCheckpointStorage("hdfs://mycluster/flink/checkpoints");
对于JobManagerCheckpointStorage来说,默认每个单独的状态大小限制为5M ,可以手动指定该值,如果Flink是本地开发调试或者Flink状态非常少的场景可以使用JobManagerCheckpointStorage,实际生产中推荐使用FileSystemCheckpointStorage。checkpoint模式设置(checkpoint mode)
//设置检查点模式为exactly-once
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//设置检查点模式为at-least-once
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);checkpoint超时时间(checkpoint timeout)
超时时间指定了每次Checkpoint执行过程中的上限时间范围,一旦Checkpoint执行时间超过该阈值,Flink将会中断Checkpoint过程,并按照超时处理。该指标可以通过setCheckpointTimeout方法设定,默认为10分钟。
//设置Checkpoint 超时时间
env.getCheckpointConfig().setCheckpointTimeout(10*60*1000);checkpoint之间最小时间间隔(min pause between checkpoints)
该参数主要目的是设定两个Checkpoint之间的最小时间间隔,防止Flink应用密集地触发Checkpoint操作,占用了大量计算资源而影响到整个应用的性能,默认值为0,表示一个checkpoint执行后,立即执行后续的checkpoint。当指定了该参数大于0时,Flink最大并行执行checkpoint 的数量为1。
//设置 checkpoint 最小间隔时间为500ms,默认值为0
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);最大并行执行checkpoint数量(max concurrent checkpoints)
通过setMaxConcurrentCheckpoints()方法设定能够最大同时执行的 Checkpoint数量。在默认情况下只有一个检查点可以运行,根据用户指定的数量可以同时触发多个Checkpoint,进而提升Checkpoint整体的效率。
//设置checkpoint最大并行度
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);可容忍checkpoint失败次数(total checkpoint failure number)
checkpoint在执行过程中如果出现失败设置可以容忍的检查的失败数,超过这个数量则系统自动关闭和停止任务,没有默认值。
//设置可容忍checkpoint失败次数,没有默认值值,设置为0,表示不容忍任何checkpoint失败
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(0);checkpoint清理策略(retained checkpoints)
当开启了checkpoint外部持久化存储时,可以通过如下两种方式决定在取消Flink作业时是否清空外部存储系统中的状态数据,如果不设置改参数,Flink取消任务时默认不清空checkpoint状态数据。
/**
* 设置checkpoint的清理策略,当作业取消时,checkpoint数据的保留策略,默认值为RETAIN_ON_CANCELLATION
* RETAIN_ON_CANCELLATION:当作业取消时,保留checkpoint数据
* DELETE_ON_CANCELLATION:当作业取消时,删除checkpoint数据
*/
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION);不对齐检查点(enable unaligned checkpoints)
可以启动Flink检查点不对齐机制从而加快checkpoint,这个设置要求checkpoint mode必须为exactly-once并且并发checkpoint的数量为1。
//设置 checkpoint barrier 不对齐机制,设置此值时,checkpointmode必须为EXACTLY_ONCE且MaxConcurrentCheckpoints为1
env.getCheckpointConfig().enableUnalignedCheckpoints();task完成后进行checkpoint(checkpoint after finish task )
当Flink读取有界数据时,一旦任务完成后就不再做checkpoint,这有可能会导致最后一部分输出数据没有保存到checkpoint状态中。从Flink1.14版本后,Flink支持在部分任务结束后创建checkpoint,确保在作业结束后完整保存所有状态数据,从1.15版本起,该属性默认启用。
//开启Flink任务完成后进行checkpoint检查点,默认值为true
Configuration config = new Configuration();
config.set(ExecutionCheckpointingOptions.ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH, true);
env.configure(config);状态后端(StateBackend)
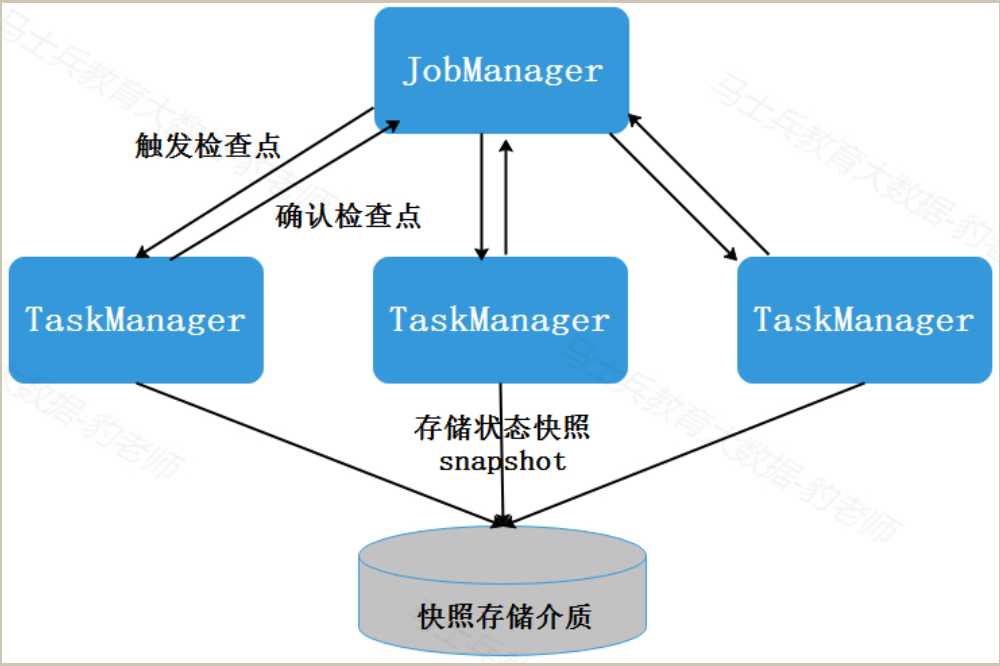
当Flink程序进行checkpoint检查点保存时,检查点的保存需要JobManager和TaskManager以及外部存储系统的协调。首先,JobManager会向所有的TaskManager发送触发检查点的命令,接收到命令的TaskManager会对当前任务的所有状态进行快照保存,并将其持久化到远程的存储介质中,完成保存后,TaskManager会向JobManager返回确认信息。整个过程是分布式的,只有当JobManager收到所有TaskManager的确认信息后,才会确认当前检查点成功保存。
checkpoint 检查点整个流程如下:
状态后端分类
HashMapStateBackend
HashMapStateBackend将状态数据以HashMap数据结构进行存储,默认将状态存储在JobManager内存中。通过用户指定checkpint持久化目录也可以将状态数据存储在外部持久化系统中。这种状态后端每次进行checkpoint检查点时都是全量方式进行,适用于较小的状态数据集,并且对于低延迟和高吞吐量的应用程序非常有效。
EmbeddedRocksDBStateBackend
EmbeddedRocksDBStateBackend 是 Flink 的一种基于 RocksDB 的状态后端。RocksDB 是一个高性能、持久化的键值存储引擎,它将状态数据存储在本地磁盘上,默认在TaskManager本地数据目录中。与 HashMapStateBackend 状态存储数据结构不同,EmbeddedRocksDBStateBackend 数据以序列化的字节数组形式存储,读写操作需要序列化与发序列化,状态访问性能可能差一些,但RockDBStateBackend是目前唯一支持增量检查点的状态后端,可以保存非常大的状态,生产环境中建议使用这种方式存储状态。针对以上两类状态后端,Flink提供了3中不同StateBackend状态后端实现
基于内存的MemoryStateBackend
//设置状态后端为HashMapStateBackend,状态数据存储在JobManager内存中
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());
基于文件系统的FsStateBackend
FsStateBackend更适合任务状态非常大的情况,例如应用中含有时间范围非常长的窗口计算,或Key/value State状态数据量非常大的场景。
//设置状态后端为HashMapStateBackend,状态数据存储在本地文件系统中
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage("file:///checkpoint-dir");
基于RockDB作为存储介质的RocksDBStateBackend
RocksDBStateBackend采用增量方式进行状态数据的Snapshot,与FsStateBackend相比,虽说都是将状态存储在磁盘中,RocksDBStateBackend在性能上要比FsStateBackend高一些,和MemoryStateBackend相比性能就会较弱一些。RocksDB克服了State受内存限制的缺点,同时又能够将状态增量持久化到远端文件系统中,推荐在生产中使用。
//设置状态后端为RocksDBStateBackend,状态数据存储在本地文件系统中
env.setStateBackend(new EmbeddedRocksDBStateBackend());
env.getCheckpointConfig().setCheckpointStorage("file:///checkpoint-dir");
状态后端全局配置以上两类状态后端的三种实现方式除了可以在代码中进行配置外,还可以在Flink集群JobManager FLINK_HOME/conf/flink-conf.yaml配置文件中配置,从而做到状态后端全局配置。配置分别如下:
MemoryStateBackend
state.backend: hashmap
state.checkpoint-storage: jobmanagerFsStateBackend
state.backend: hashmap
state.checkpoints.dir: file:///checkpoint-dir/
state.checkpoint-storage: filesystem
RocksDBStateBackend
state.backend: rocksdb
state.checkpoints.dir: file:///checkpoint-dir/
state.checkpoint-storage: filesystem
保存点(savepoint)
savepoints 是检查点的一种特殊实现,底层实现其实也是使用checkpoints的机制。savepoints是用户以手工命令的方式触发checkpoint,并将结果持久化到指定的存储路径中,其主要目的是帮助用户在升级和维护集群过程中保存系统中的状态数据,避免因为停机运维或者升级应用等正常终止应用的操作而导致系统无法恢复到原有的计算状态的情况,从而无法实现从端到端的 exactly-once语义保证。savepoint配置
可以在flink-conf.yaml中配置savepoint存储的位置,设置后,如果要创建指定Job的savepoint,可以不用在手动执行命令时指定savepoint的位置。
state.savepoints.dir: hdfs://mycluster/savepoints触发savepoint
执行如下命令执行savepoint 操作,将当前Flink程序的状态保存到对应路径中。
[root@node5 bin]# ./flink savepoint d2d863913b663ad70f60ee50d05aaa32 -yid application_1687674094408_0001Checkpoint & Savepoint区别
Checkpoint和Savepoint是Apache Flink中用于状态管理和故障恢复的两个概念。
Checkpoint是周期性自动创建的,用于将应用程序的状态信息保存到持久化存储中。它记录了输入数据、中间计算结果和应用程序配置等状态,以便在故障发生时能够从最近的Checkpoint恢复应用程序的状态。
Savepoint是由用户手动触发的操作,用于显式地保存应用程序的状态。用户可以在任意时间点创建Savepoint,并将应用程序的状态保存到持久化存储中。Savepoint可以用于应用程序升级、在不同环境中迁移应用程序的状态。