
学习资料 – 第九章 Flink Table API与SQL (二) 枫叶云笔记 (fynote.com)
Apache Hive是数据仓库生态系统的核心,Flink支持与Hive集成,提供了HiveCatalog,Catalog是元数据管理中心(元数据包含数据库、表、表结构等信息)。Flink与Hive集成主要包含以下两个层面:
利用Flink来读写Hive表
Flink可以利用Hive Metastore作为持久化的Catalog目前Flink支持Hive的最低版本为2.3.0,最高版本为3.1.3,Flink想要与Hive进行集成需要在项目中引入如下依赖:
<!-- Flink Hive 集成所需依赖包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Hive 依赖包 -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
</exclusion>
</exclusions>
</dependency>导入依赖时需要注意需要将“log4j-slf4j-impl”从hive-exec中排除,否则会和项目中已有的“log4j-to-slf4j”造成冲突。
Hive Catalog
HiveCatalog可以处理两种表:Hive兼容表和通用表。
Hive兼容表是指存储层的元数据和数据都以Hive兼容的方式存储的表,通过 Flink 创建的兼容 Hive 的表可以从 Hive 端查询。
通用表是Flink特有的,当通过HiveCatalog创建通用表时,我们只是使用Hive Metastore 来持久化存储元数据,虽然这些表可以对Hive可见,但是无法在Hive中直接查询这些表,否则会导致未知错误。Flink与Hive集成时需要首先创建HiveCatalog,创建Catalog可以通过两种方式:代码或者SQL方式。
代码方式创建HiveCatalog
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive";//catalog name
String defaultDatabase = "default";//default database
String hiveConfDir = "D:\\idea_space\\MyFlinkCode\\hiveconf";//Hive配置文件目录,Flink读取Hive元数据信息需要
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tableEnv.registerCatalog("myhive", hive);
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive");SQL方式创建HiveCatalog
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//SQL 方式创建 Hive Catalog
tableEnv.executeSql("CREATE CATALOG myhive WITH (" +
" 'type'='hive'," +//指定Catalog类型为hive
" 'default-database'='default'," +//指定默认数据库
" 'hive-conf-dir'='D:\\idea_space\\MyFlinkCode\\hiveconf'" +//指定Hive配置文件目录,Flink读取Hive元数据信息需要
")");
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive");以上两种方式都可以创建HiveCatalog,都需要指定hive配置文件目录,并将Hive客户端的hive-site.xml文件放在该目录中,以便Flink可以连接到Hive。
Hive兼容表
Hive兼容表可以是Hive中预先创建出来的表,通过Flink SQL读取Hive表数据
也可以通过Flink SQL创建的Hive兼容表。
两种都可以在Flink SQL或者Hive中进行数据读写操作。
使用FlinK SQL创建Hive兼容表时,需要在Flink代码中切换到“Hive 方言 ”,所谓Hive 方言就是支持Flink SQL中使用Hive语法编写SQL语句。
Flink SQL 方言:
Flink目前支持两种SQL方言:default和hive,默认使用default,即Flink 默认方言。
如果使用Flink SQL 客户端可以通过以下方式来设置使用Hive方言:
Flink SQL> SET table.sql-dialect = hive; -- 使用 Hive 方言
[INFO] Session property has been set.
Flink SQL> SET table.sql-dialect = default; -- 使用 Flink 默认 方言
[INFO] Session property has been set.如果使用代码编程方式可以如下方式设置使用Hive方言:
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tableEnv = TableEnvironment.create(settings);
// 设置使用Hive方言
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
// 设置使用Flink默认方言
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);值得特别注意的是从Flink1.15版本开始,如果想要使用Hive方言必须在项目中导入“flink-table-planner_2.12-xxx.jar”依赖包并同时将“flink-table-planner-loader-xxx.jar”依赖注释掉,否则将抛出 ValidationException异常,如下错误:
Exception in thread "main" org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'hive' that implements 'org.apache.flink.table.planner.delegation.DialectFactory' in the classpath.导入依赖如下:
<!-- Flink Table Planner 依赖包 -->
<!-- <dependency>-->
<!-- <groupId>org.apache.flink</groupId>-->
<!-- <artifactId>flink-table-planner-loader</artifactId>-->
<!-- <version>${flink.version}</version>-->
<!-- </dependency>-->
<!-- 该依赖包替换 flink-table-planner-loader 依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
</dependency>注意:如果不使用Hive兼容表建议在项目中导入“flink-table-planner-loader-xxx.jar”依赖包,Flink1.15版本后,如果使用Hive兼容表使用“flink-table-planner_2.12-xxx.jar”替代“flink-table-planner-loader-xxx.jar”依赖包。
通用表
通用表严格来说只是使用Hive Metastore来进行Flink表元数据的持久化存储,默认通过Flink SQL创建的表在当前会话中有效,如果在其他会话中使用就需要重新创建,那么通过利用Hive Metastore进行Flink表元数据持久化存储就能解决重复创建表的问题。
虽然通用表对Hive可见,但不能通过Hive进行查询。
创建通用表后,可以通过其他Flink程序进行操作该表。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//SQL 方式创建 Hive Catalog
tableEnv.executeSql("CREATE CATALOG myhive WITH (" +
" 'type'='hive'," +//指定Catalog类型为hive
" 'default-database'='default'," +//指定默认数据库
" 'hive-conf-dir'='D:\\idea_space\\MyFlinkCode\\hiveconf'" +//指定Hive配置文件目录,Flink读取Hive元数据信息需要
")");
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive");
//读取Kafka数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table flink_kafka_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" rowtime AS TO_TIMESTAMP_LTZ(call_time, 3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")"
);
//通过SQL 查询表中数据
tableEnv.executeSql("select * from flink_kafka_tbl").print();特别需要注意:创建的通用表数据只是利用Hive存储了元数据,并非是数据,也就是说数据并不会存储在Hive中。如以上案例中,数据还是在Kafka中并非把数据存储在了Hive中。
Flink批/流写Hive
link SQL 支持批和流两种方式向Hive中写入数据,当向Hive中批写数据时,只有当写作业完成后数据才能被看见,批模式支持追加写到现有的表或者覆盖现有的表。
Flink SQL向Hive中批写数据的方式如下:
# ------ INSERT INTO 将追加到表或者分区,保证数据的完整性 ------
Flink SQL> INSERT INTO mytable SELECT 'Tom', 25;
# ------ INSERT OVERWRITE 将覆盖表或者分区中所有已经存在的数据 ------
Flink SQL> INSERT OVERWRITE mytable SELECT 'Tom', 25;Flink SQL向Hive中流式写数据时,不支持“INSERT OVERWRITE”的方式覆盖表数据。
Flink SQL支持实时写入普通Hive表或者分区Hive表,一般实时写入Hive表,建议写入分区表,这样方便后续的查询分析。
#设置Hive方言
SET table.sql-dialect=hive;
#使用Hive语法创建Hive分区表
CREATE TABLE hive_table (
user_id STRING,
order_amount DOUBLE
) PARTITIONED BY (dt STRING, hr STRING) STORED AS parquet TBLPROPERTIES (
'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00',
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='1 h',
'sink.partition-commit.watermark-time-zone'='Asia/Shanghai',
'sink.partition-commit.policy.kind'='metastore,success-file'
);
#设置Flink default方言
SET table.sql-dialect=default;
#创建读取Kafka 实时表
CREATE TABLE kafka_table (
user_id STRING,
order_amount DOUBLE,
log_ts TIMESTAMP(3),
-- 在 TIMESTAMP 列声明 watermark。
WATERMARK FOR log_ts AS log_ts - INTERVAL '5' SECOND
) WITH (...);
#读取Kafka数据实时写入到Hive分区表中
INSERT INTO TABLE hive_table
SELECT user_id, order_amount,
DATE_FORMAT(log_ts, 'yyyy-MM-dd'),
DATE_FORMAT(log_ts, 'HH') FROM kafka_table;
#批次查询Hive分区表中数据
SELECT * FROM hive_table WHERE dt='2020-05-20' and hr='12';创建Hive分区表的一些参数解释:
partition.time-extractor.timestamp-pattern
分区时间戳的抽取格式,默认为“yyyy-MM-dd HH:mm:ss”。配置该值就是指定如何从时间戳中获取分区时间字段,需要用hive表中相应的分区字段做占位符替换。举例:如果需要从时间戳中抽取多个分区字段,比如 'year'、'month'、'day' 和 'hour' ,可以配置成: '$year-$month-$day $hour:00:00';如果从时间戳中提取两个分区字段 'dt' 和 'hour' ,可以配置成:'$dt $hour:00:00'。sink.partition-commit.trigger
触发分区提交的时间特征,可配置成“process-time”(默认)和“partition-time”。FlinkSQL将实时写入到Hive表中,只有分区提交了(包括元数据提交、数据提交)我们才能正确的从Hive中查询出数据。该参数就是设置是基于“process-time”(处理时间)还是基于”partition-time”(事件时间)触发分区提交。如果设置为“process-time”,表示当系统时间达到分区创建时间+“sink.partition-commit.delay”指定的延时时间后,就立即触发分区提交(sink.partition-commit.delay参数解释参考下文),这种情况下当数据有延迟时很容易造成数据混乱,所以建议将其配置为“partition-time”,即按照分区内数据对应的事件时间决定触发分区提交。sink.partition-commit.delay
触发分区提交的延迟。例如:当触发分区的时间特征设置为“partition-time”时,watermark大于分区创建时间+该延迟时间时,分区才会真正的触发提交。强烈建议设置该值与分区粒度相同,如:Hive表分区按照1小时分区,该参数可以设置为“1 h”即可。假设触发分区提交的时间特征设置为“partition-time”,每小时设置一个分区,如果不设置触发分区提交的延迟,那么每到1个小时点上,该分区一创建即会提交,例如:1970-01-01 08:00:00 时刻一到,8点分区就会触发提交,当1970-01-01 09:00:00时刻一到,9点的分区就会触发提交,这样会将8点到9点之间的数据划分到9点分区内,不符合我们的习惯,所以可以设置“sink.partition-commit.delay”来延迟触发分区提交,如果每小时设置一个分区,该延时值可以设置为1小时,当1970-01-01 08:00:00 时刻一到,不会立刻触发分区提交,而是延时1小时,当1970-01-01 09:00:00时刻一到才会提交8点分区,这样可以将8点到9点的数据划分到8点分区中,这就是为什么建议将该值设置为分区粒度一样的原因。sink.partition-commit.watermark-time-zone
如果事件时间是基于TIMESTAMP_LTZ列进行设置,必须将改参数设置为本地时区,否则分区提交可能会在几小时后提交。sink.partition-commit.policy.kind
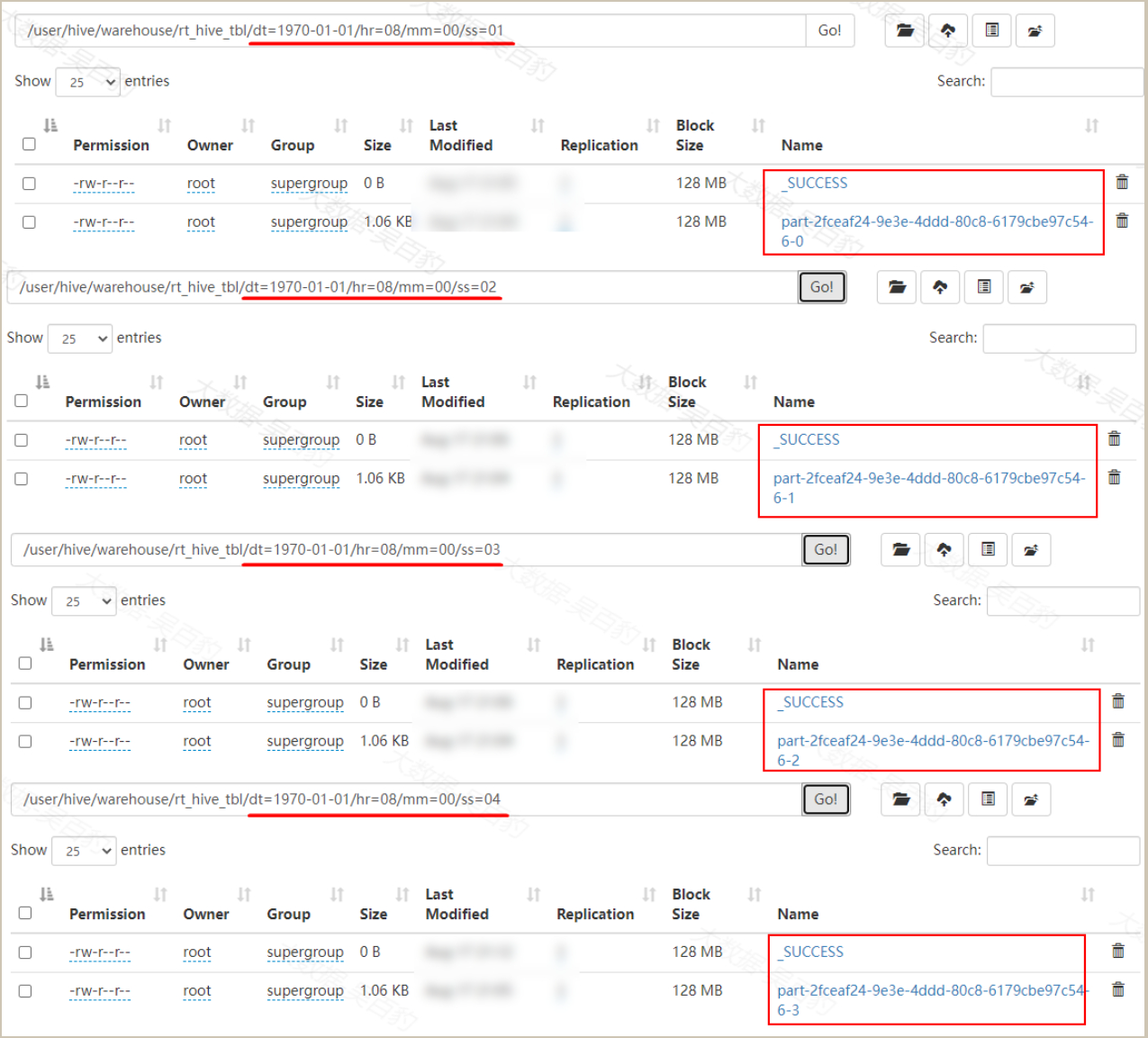
分区提交的策略,即分区何时可以被下游读取。可以设置为“metastore”、“success-file”值。“metastore”表示向Hive Metastore中添加了分区元数据后,该分区就可以被下游读取;“success-file”表示在分区目录中有了“_SUCCESS”标记文件后,该分区就可以被下游读取。
也可以将该值设置为“metastore,success-file”,通知满足两个条件后,该分区才可被下游读取。通过Flink SQL实时向Hive中写入数据,实际上底层就是向HDFS中写入文件,在编写Flink代码时需要设置checkpoint机制,否则文件不能正常生成。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//设置checkpoint
tableEnv.getConfig().getConfiguration().setLong("execution.checkpointing.interval", 5000L);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//SQL 方式创建 Hive Catalog
tableEnv.executeSql("CREATE CATALOG myhive WITH (" +
" 'type'='hive'," +//指定Catalog类型为hive
" 'default-database'='default'," +//指定默认数据库
" 'hive-conf-dir'='D:\\idea_space\\MyFlinkCode\\hiveconf'" +//指定Hive配置文件目录,Flink读取Hive元数据信息需要
")");
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive");
//设置Hive方言
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
//创建Hive分区表
tableEnv.executeSql("" +
"create table rt_hive_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint" +
") partitioned by (dt string,hr string,mm string,ss string) " +
"stored as parquet tblproperties (" +
" 'partition.time-extractor.timestamp-pattern'='$dt $hr:$mm:$ss'," +
" 'sink.partition-commit.trigger'='partition-time'," +
" 'sink.partition-commit.delay'='1 s'," +
" 'sink.partition-commit.watermark-time-zone'='Asia/Shanghai'," +
" 'sink.partition-commit.policy.kind'='metastore,success-file'" +
")"
);
//设置 Flink Default方言
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
//读取Kafka数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table rt_kafka_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" rowtime AS TO_TIMESTAMP_LTZ(call_time, 3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")"
);
//将 Kafka 数据写入 Hive 分区表
tableEnv.executeSql("" +
"insert into rt_hive_tbl " +
"select sid,call_out,call_in,call_type,call_time,duration," +
" DATE_FORMAT(rowtime, 'yyyy-MM-dd') dt," +
" DATE_FORMAT(rowtime, 'HH') hr, " +
" DATE_FORMAT(rowtime, 'mm') mm, " +
" DATE_FORMAT(rowtime, 'ss') ss " +
"from rt_kafka_tbl"
);
随着Flink SQL实时向Hive分区表中写入数据,小文件也会越来越多,Flink也支持自动对小文件进行合并以减少小文件带来的影响。实时场景下,我们可以设置如下参数来让Flink自动进行小文件合并:
auto-compaction:默认值为false。在流式Sink中是否开启自动合并功能。数据首先会被写入临时文件,当checkpoint完成后,该检查点产生的临时文件会被合并,这些临时文件在合并前不可见。
compaction.file-size:指定合并目标文件大小,默认值为实际情况下的滚动文件大小。Flink批/流读Hive
FlinkSQL支持以批和流两种模式从Hive中读取数据。
批读时Flink会基于查询表的状态进行查询,默认情况下Flink将以批模式读取数据。
流读时Flink会实时监控表,并在表中新数据可用时进行增量获取,流读支持读取Hive普通表和分区表,对于普通表Flink将会监控文件夹中新文件的生成进行增量读取,对于分区表Flink会监控新分区数据生成并增量获取新分区数据。
FlinkSQL实时读取Hive表数据可以通过SQL提示( SQL Hints)来完成,形式如下:
SELECT *
FROM hive_table
/*+ OPTIONS(
'streaming-source.enable'='true',
'streaming-source.monitor-interval' = '2 second',
'streaming-source.consume-start-offset'='2020-05-20'
) */;以上OPTIONS中的参数解释如下:
streaming-source.enable
是否启动流读,默认false。
streaming-source.monitor-interval
连续监控分区/文件的时间间隔,默认情况流式读取Hive时间间隔为1分钟。
streaming-source.consume-start-offset
流式读取Hive起始消费的时间戳,需要只当成“yyyy-MM-dd HH:mm:ss”形式。此外,实时读取Hive表要求每个文件必须原子性写入目标目录,如果是分区表,每个分区的元数据也应被原子性添加到Hive Metastore中,这样才能被Flink SQL 实时读取。
目前流式读取Hive表不支持Flink DDL的watermark语法,这些表不能被用于窗口操作。