
看不懂,管他的,会调包就好了!
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
- criterion
- 特征选择标准
- “gini”或者”entropy”,前者代表基尼系数,后者代表信息增益。一默认”gini”,即CART算法。
- min_samples_split
- 内部节点再划分所需最小样本数
- 这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。我之前的一个项目例子,有大概10万样本,建立决策树时,我选择了min_samples_split=10。可以作为参考。
- min_samples_leaf
- 叶子节点最少样本数
- 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。之前的10万样本项目使用min_samples_leaf的值为5,仅供参考。
- max_depth
- 决策树最大深度
- 决策树的最大深度,默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间
- random_state
- 随机数种子
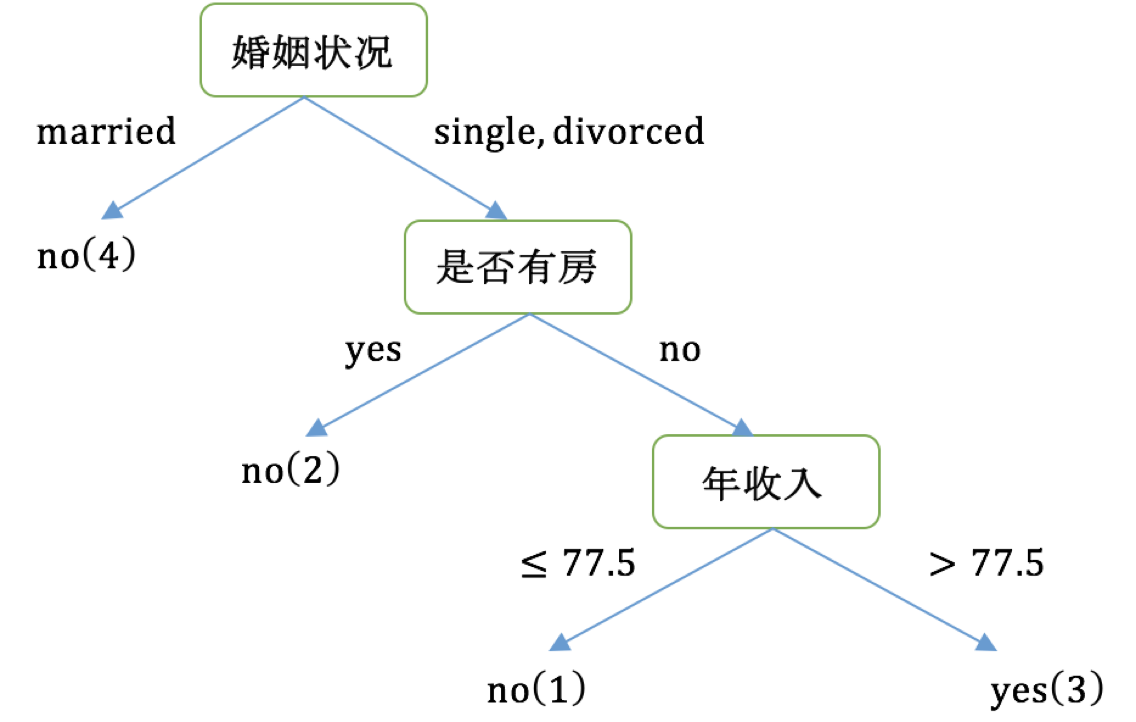
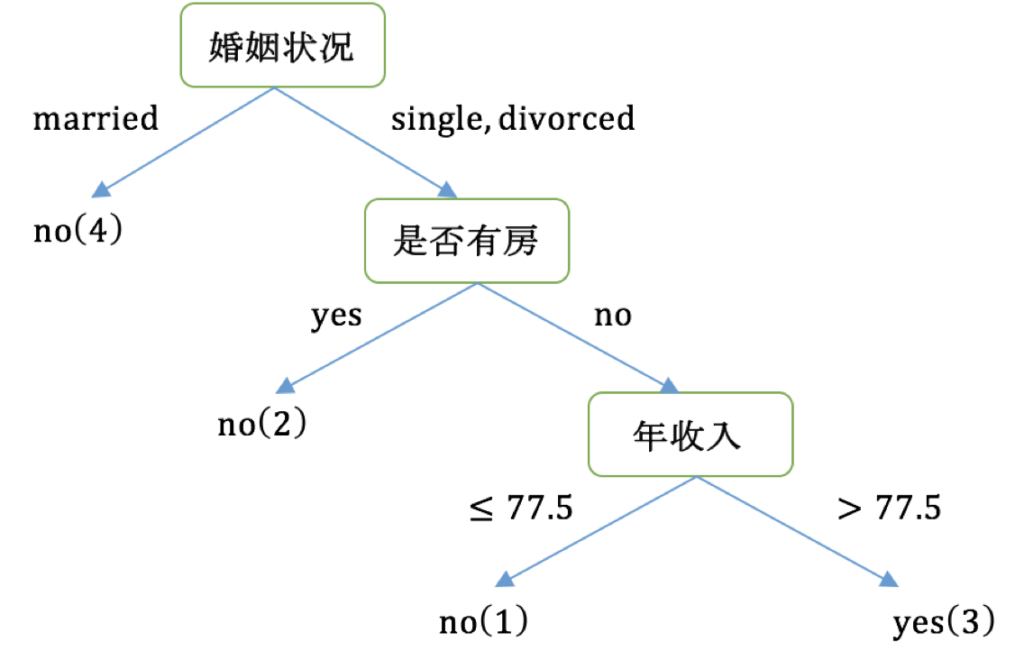
案例:泰坦尼克号乘客生存预测
泰坦尼克号沉没是历史上最臭名昭着的沉船之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在2224名乘客和机组人员中造成1502人死亡。这场耸人听闻的悲剧震惊了国际社会,并为船舶制定了更好的安全规定。 造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。尽管幸存下沉有一些运气因素,但有些人比其他人更容易生存,例如妇女,儿童和上流社会。 在这个案例中,我们要求您完成对哪些人可能存活的分析。特别是,我们要求您运用机器学习工具来预测哪些乘客幸免于悲剧。
我们提取到的数据集中的特征包括票的类别,是否存活,乘坐班次,年龄,登陆home.dest,房间,船和性别等。
数据:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt
步骤分析
- 1.获取数据
- 2.数据基本处理
- 2.1 确定特征值,目标值
- 2.2 缺失值处理
- 2.3 数据集划分
- 3.特征工程(字典特征抽取)
- 4.机器学习(决策树)
- 5.模型评估
代码实现
# 导入需要的模块
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
# 1、获取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
# 2.数据基本处理
# 2.1 确定特征值,目标值
x = titan[["pclass", "age", "sex"]]
y = titan["survived"]
# 2.2 缺失值处理
# 缺失值需要处理,将特征当中有类别的这些特征进行字典特征抽取
x['age'].fillna(x['age'].mean(), inplace=True)
# 2.3 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 3.特征工程(字典特征抽取)
# 特征中出现类别符号,需要进行one-hot编码处理(DictVectorizer)
# x.to_dict(orient="records") 需要将数组特征转换成字典数据
# 对于x转换成字典数据x.to_dict(orient="records")
# [{"pclass": "1st", "age": 29.00, "sex": "female"}, {}]
transfer = DictVectorizer(sparse=False)
x_train = transfer.fit_transform(x_train.to_dict(orient="records"))
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))
# 4.决策树模型训练和模型评估
# 决策树API当中,如果没有指定max_depth那么会根据信息熵的条件直到最终结束。这里我们可以指定树
# 的深度来进行限制树的大小
# 4.机器学习(决策树)
estimator = DecisionTreeClassifier(criterion="entropy", max_depth=5)
estimator.fit(x_train, y_train)
# 5.模型评估
estimator.score(x_test, y_test)
estimator.predict(x_test)
决策树可视化
4.1 保存树的结构到dot文件
- sklearn.tree.export_graphviz() 该函数能够导出DOT格式
- tree.export_graphviz(estimator,out_file=’tree.dot’,feature_names=[‘’,’’])
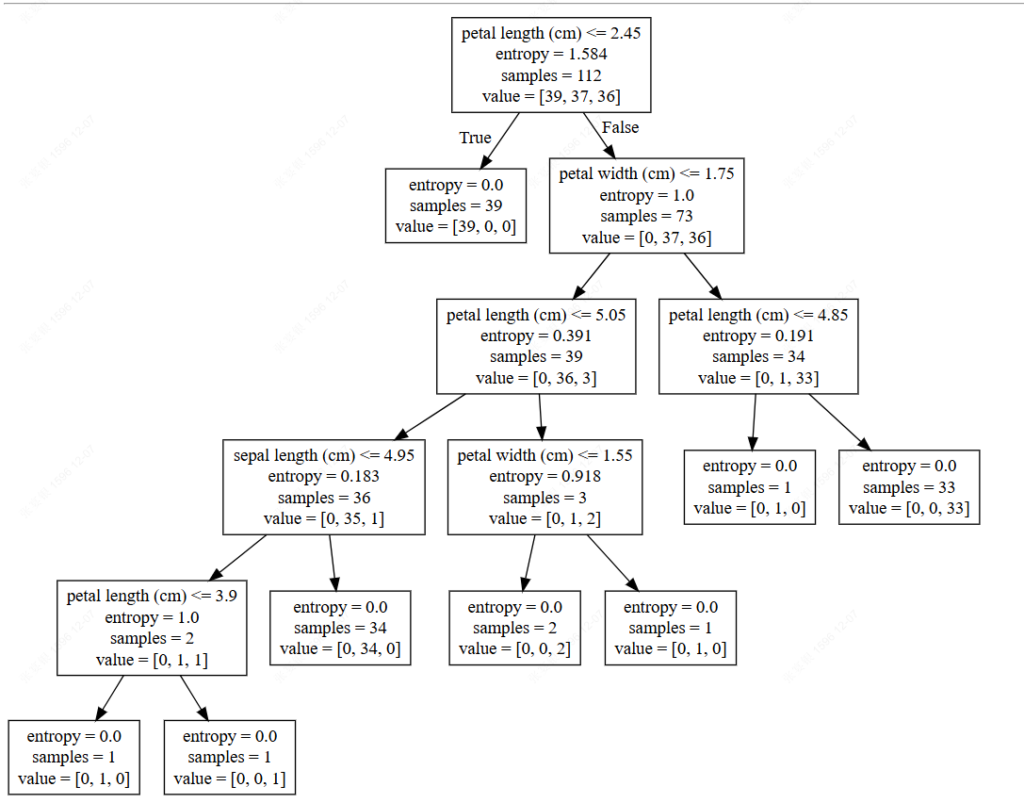
export_graphviz(estimator, out_file="./data/tree.dot", feature_names=['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])dot文件当中的内容如下
digraph Tree {
node [shape=box] ;
0 [label="petal length (cm) <= 2.45\nentropy = 1.584\nsamples = 112\nvalue = [39, 37, 36]"] ;
1 [label="entropy = 0.0\nsamples = 39\nvalue = [39, 0, 0]"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="petal width (cm) <= 1.75\nentropy = 1.0\nsamples = 73\nvalue = [0, 37, 36]"] ;
0 -> 2 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
3 [label="petal length (cm) <= 5.05\nentropy = 0.391\nsamples = 39\nvalue = [0, 36, 3]"] ;
2 -> 3 ;
4 [label="sepal length (cm) <= 4.95\nentropy = 0.183\nsamples = 36\nvalue = [0, 35, 1]"] ;
3 -> 4 ;
5 [label="petal length (cm) <= 3.9\nentropy = 1.0\nsamples = 2\nvalue = [0, 1, 1]"] ;
4 -> 5 ;
6 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1, 0]"] ;
5 -> 6 ;
7 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 0, 1]"] ;
5 -> 7 ;
8 [label="entropy = 0.0\nsamples = 34\nvalue = [0, 34, 0]"] ;
4 -> 8 ;
9 [label="petal width (cm) <= 1.55\nentropy = 0.918\nsamples = 3\nvalue = [0, 1, 2]"] ;
3 -> 9 ;
10 [label="entropy = 0.0\nsamples = 2\nvalue = [0, 0, 2]"] ;
9 -> 10 ;
11 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1, 0]"] ;
9 -> 11 ;
12 [label="petal length (cm) <= 4.85\nentropy = 0.191\nsamples = 34\nvalue = [0, 1, 33]"] ;
2 -> 12 ;
13 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1, 0]"] ;
12 -> 13 ;
14 [label="entropy = 0.0\nsamples = 33\nvalue = [0, 0, 33]"] ;
12 -> 14 ;
}那么这个结构不能看清结构,所以可以在一个网站上显示
网站显示结构
决策树总结
- 优点:
- 简单的理解和解释,树木可视化。
- 缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,容易发生过拟合。
- 改进:
- 减枝cart算法
- 随机森林(集成学习的一种)
注:企业重要决策,由于决策树很好的分析能力,在决策过程应用较多, 可以选择特征
回归决策树
前面已经讲到,关于数据类型,我们主要可以把其分为两类,连续型数据和离散型数据。在面对不同数据时,决策树也可以分为两大类型:
- 分类决策树和回归决策树。
- 前者主要用于处理离散型数据,后者主要用于处理连续型数据。
不管是回归决策树还是分类决策树,都会存在两个核心问题:
- 如何选择划分点?
- 如何决定叶节点的输出值?
一个回归树对应着输入空间(即特征空间)的一个划分以及在划分单元上的输出值。分类树中,我们采用信息论中的方法,通过计算选择最佳划分点。
而在回归树中,采用的是启发式的方法。假如我们有n个特征,每个特征有si(i∈(1,n))si(i∈(1,n))个取值,那我们遍历所有特征,尝试该特征所有取值,对空间进行划分,直到取到特征 j 的取值 s,使得损失函数最小,这样就得到了一个划分点
算法描述
- 输入:训练数据集D:
- 输出:回归树f(x).
- 在训练数据集所在的输入空间中,递归的将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树:
- (1)选择最优切分特征j与切分点s,求解遍历特征j,对固定的切分特征j扫描切分点s,选择使得上式达到最小值的对(j,s).
- (2)用选定的对(j,s)划分区域并决定相应的输出值:
- (3)继续对两个子区域调用步骤(1)和(2),直至满足停止条件。
- (4)将输入空间划分为M个区域R1,R2,…,RM, 生成决策树
实例计算过程
(1)选择最优的切分特征j与最优切分点s:
- 确定第一个问题:选择最优切分特征:
- 在本数据集中,只有一个特征,因此最优切分特征自然是x。
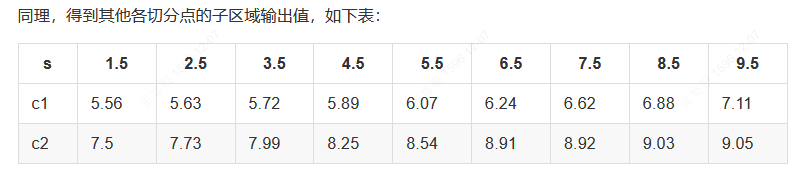
- 确定第二个问题:我们考虑9个切分点 [1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5,9.5][1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5,9.5] 。
- 损失函数定义为平方损失函数Loss(y,f(x))=(f(x)−y)2,将上述9个切分点依此代入下面的公式,其中 cm=avg(yi∣xi∈Rm)
a、计算子区域输出值:
例如,取 s=1.5。此时R1=1,R2=2,3,4,5,6,7,8,9,10,这两个区域的输出值分别为:
- c1=5.56
- c2=(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)/9=7.50。
回归决策树算法总结
- 输入:训练数据集D:
- 输出:回归树f(x).
- 流程:在训练数据集所在的输入空间中,递归的将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树:
- (1)选择最优切分特征jj与切分点ss,求解
 遍历特征j,对固定的切分特征j扫描切分点s,选择使得上式达到最小值的对(j,s).
遍历特征j,对固定的切分特征j扫描切分点s,选择使得上式达到最小值的对(j,s). - (2)用选定的对(j,s)划分区域并决定相应的输出值:

- (3)继续对两个子区域调用步骤(1)和(2),直至满足停止条件。
- (4)将输入空间划分为M个区域R1,R2,…,RM, 生成决策树:

- (1)选择最优切分特征jj与切分点ss,求解