
import pandas as pd
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
from sklearn.metrics import classification_report
from sklearn.utils import class_weight
from sklearn.ensemble import GradientBoostingClassifier
# 数据获取
train_data = pd.read_csv(r'/root/data/titanic/hjplfl_train.csv')
test_data = pd.read_csv(r'/root/data/titanic/hjplfl_test.csv')
x_train = train_data.iloc[:,:-1]
y_train = train_data.iloc[:,-1]
x_test = test_data.iloc[:,:-1]
y_test = test_data.iloc[:,-1]
class_weight=class_weight.compute_sample_weight(class_weight='balanced',y=y_train)
# 作用:这是处理类别不平衡问题的核心技巧。
# 问题:如果标签 y_train 中某些类别的样本数远多于其他类别(例如,1000个负样本 vs 10个正样本)
# 模型会倾向于忽略小类别,导致预测结果偏向大类别。
# 解决:compute_sample_weight 函数会根据每个类别的样本数量,
# 为训练集中的每一个样本计算一个权重。样本数越少的类别,其样本的权重越高。
# 参数:
# class_weight='balanced':自动计算权重,使所有类别的总权重相等。
# y=y_train:基于训练集标签的分布来计算。
# 输出:一个一维数组,长度等于 y_train 的样本数。例如,[0.5, 1.2, 0.5, 1.2, ...]。
# 这个数组通常在调用模型的 .fit() 方法时,通过 sample_weight 参数传入。
# 模型训练
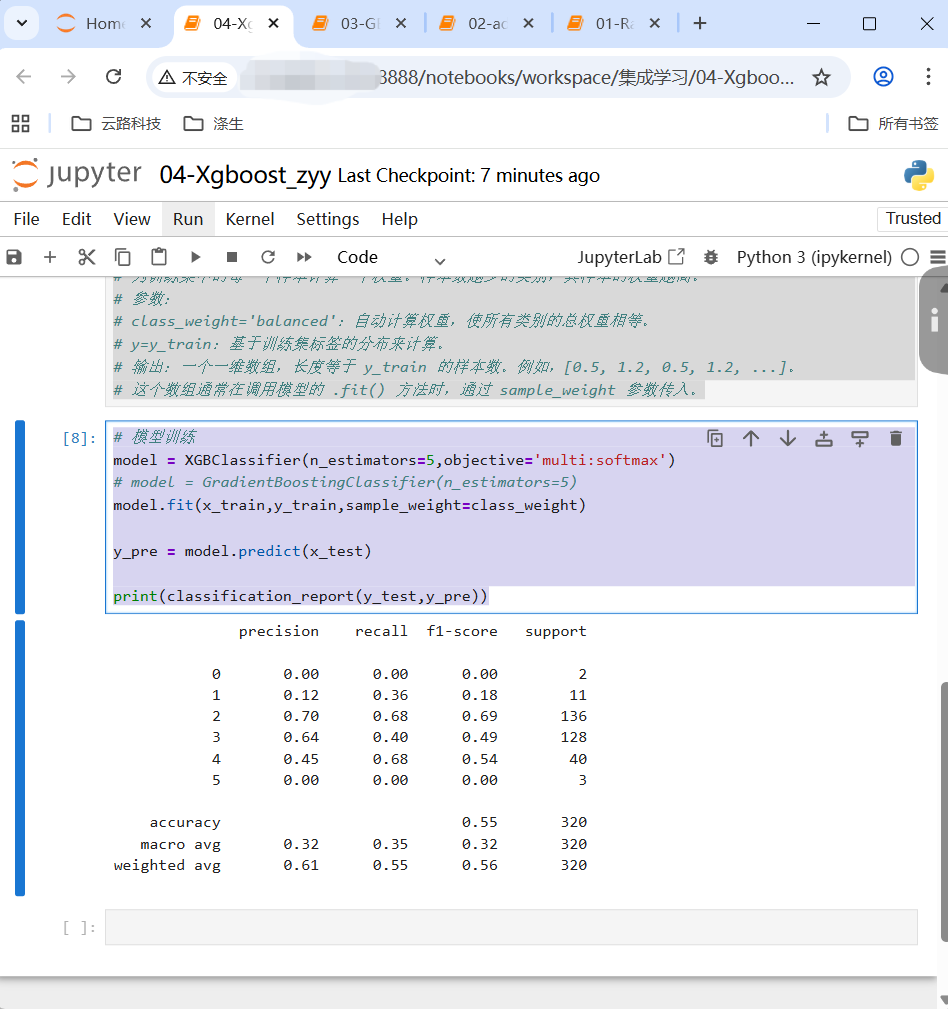
model = XGBClassifier(n_estimators=5,objective='multi:softmax')
# model = GradientBoostingClassifier(n_estimators=5)
model.fit(x_train,y_train,sample_weight=class_weight)
y_pre = model.predict(x_test)
print(classification_report(y_test,y_pre))
作者 admin
张宴银,大数据开发工程师