概率复习
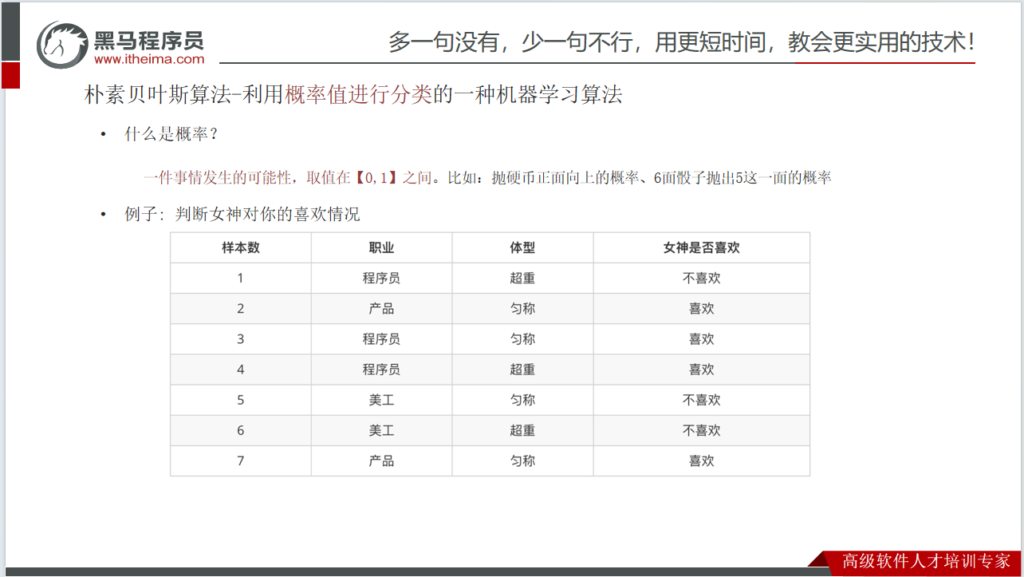


朴素贝叶斯公式

拉普拉斯平滑系数

朴素贝叶斯API及代码案例

朴素贝叶斯代码案例 – 商品评论情感分析


import pandas as pd
import numpy as np
import jieba
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
# 读取数据
data = pd.read_csv('/root/data/titanic/sjpj.csv',encoding='gbk')
print(data)
data['labels']=np.where(data['评价']=='好评',1,0)
print(data)
y = data['labels']
stop_words=[]
with open('/root/data/titanic/stopwords.txt',encoding='utf-8') as file:
lines=file.readlines()
# line.strip():对每一行字符串调用strip()方法
# 移除行首尾的空白字符(包括空格、制表符、换行符等)
stop_words=[line.strip() for line in lines]
stop_words = list(set(stop_words))
print(stop_words)
# 分词
word_list = [','.join(jieba.lcut(line)) for line in data['内容']]
# jieba.lcut(line):对每一行文本调用jieba分词库的lcut()函数进行分词
# lcut()返回一个分词后的列表,例如:['今天', '天气', '很好']、
# ','.join(...):将分词后的列表用逗号连接成一个字符串
# 例如:['今天', '天气', '很好'] → '今天,天气,很好'
print(word_list)
# 词频统计
transform = CountVectorizer(stop_words=stop_words)
x = transform.fit_transform(word_list)
names = transform.get_feature_names_out()
x = x.toarray()
print(x)
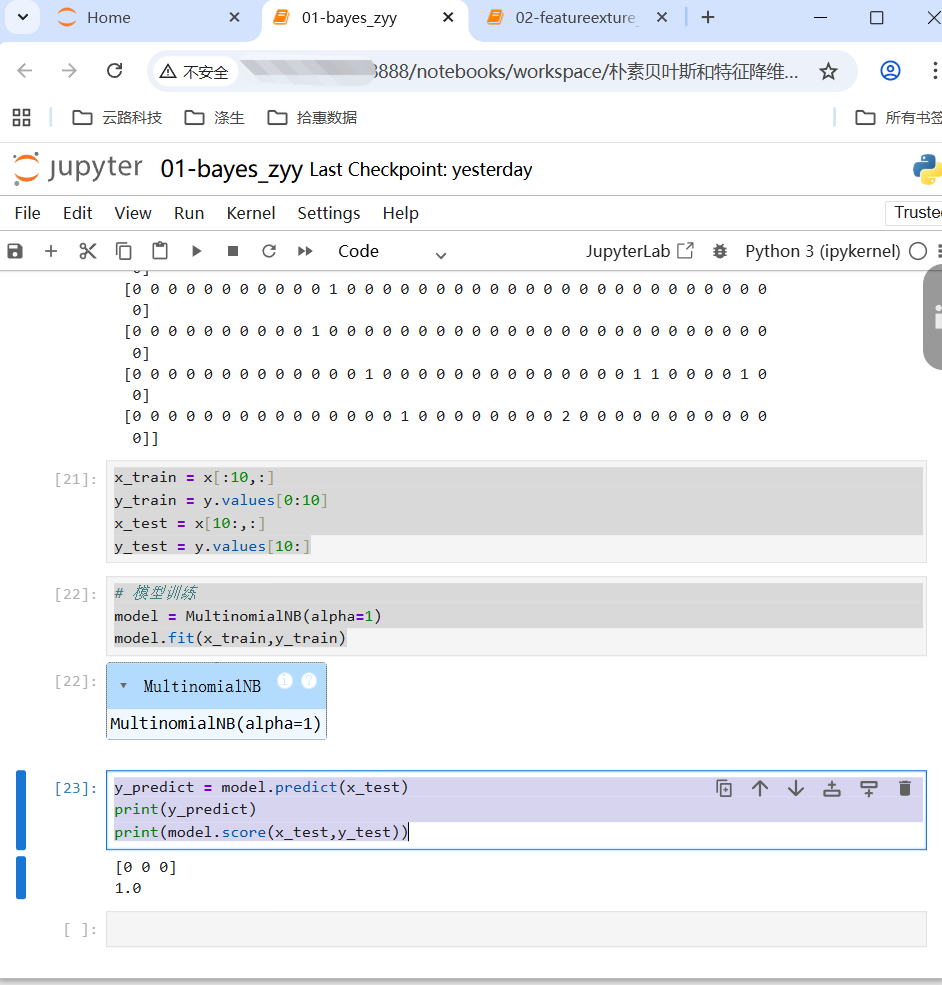
x_train = x[:10,:]
y_train = y.values[0:10]
x_test = x[10:,:]
y_test = y.values[10:]
# 模型训练
model = MultinomialNB(alpha=1)
model.fit(x_train,y_train)
y_predict = model.predict(x_test)
print(y_predict)
print(model.score(x_test,y_test))