
1.Mysql 的 SQL 执行的流程

Mysql SQL 执行流程:FROM 读原表→JOIN 读从表生成虚拟表→ON 过滤条件 →添加外部行(Left/Right/Full-Join)→Where 过滤→Group by 分组虚拟表 →Having 过滤数据→Select 列表生成→Distinct 去重→Order by 排序→Limit 限制输出
2.HiveSQL 的执行流程
代码执行流程:
Mapper 端执行:
1. 首先执行 FROM,进行表的 scan 查找与加载;
2. 然后执行 Where 操作,Hive 对语句进行了优化,如果符合谓词下推,则进行谓词下推。这也是为啥这里指定分区后不会全表扫描的原因。
3. 然后执行 join 语句,按照 on 里面的 join-key 进行 shuffle 数据,注意只有使用到列才会读取 shuffle 出去,shuffle 的 key 是 join-key(支持组合键)。(注意这里先不考虑 map-join,groupby 的 map 聚合等优化操作)
Reduce 端执行:
4.如果 on 里有非等值的过滤表达式如 t1.db <> 'abc',注意不是非等值链接。 在实际join 关联前先过滤 on 里面的谓词;
5.其他然后才是 groupby,having,orderby by ,limit 等。注意实际执行计划需要看 explain,会因为不同版本和执行优化细节上有差异。 过滤条件放到 on 和 where 区别?
所有这种情况统一写成select from where 的子查询
Hive SQL 优化思路
Hive SQL 语法多种多样,但本质上可以被分成 3 种模式, 即过滤模式、 聚合模式和连接模式。
1. 过滤模式:从过滤的粒度来看,主要分为:行过滤、 数据列过滤、 文件
过滤和目录过滤 4 种方式。具体 SQL 语法上体现在 Where,having,
distinct 语句上;
2. 聚合模式:distinct 聚合,count 计数聚合,数值相关的聚合模式,行转列聚合模式。
3. Join 模式:有 shuffle 的 join 和无 shuffle 的 join。SQL 数据过滤模式优化
1.分区|目录过滤|裁剪
分区过滤|裁剪本质是为了减少数据量,避免全表扫描。
虽然分区过滤条件我们写在 where 子句里,但是特别注意分区过滤在发生在表扫描阶段即完成了(分区过滤是发生在 map 之前,这就是分区表目录结构的优势,相当于直接指定路径读取文件了),而其他 where 里的过滤条件是发生在 map 段,是通过 maptask 实现一行行过滤的
分区裁剪有时候会有失效的情况,比如使用 udf 函数对其进行处理时,可能存 在分区裁剪失效的情况,具体我们可以通过 explain 命令查看
分区数据筛选无论哪种join方式,都统一写成select from where 的子查询方式
2.表过滤:Hive 多表插入(Multiple Inserts)
当需要将一张表中经过不同筛选条件筛选出的数据插入到 多张表或者一张表中的多个分区
多插入(Multiple Inserts)将扫表次数降低到最小,降低插入总耗时。之所以说是总耗时,其实并没有降低写入的数据量或者降 低写入时间,而是降低扫表时间,将多次扫表合并为一次扫表
3.列裁剪
注意列裁剪在读取数的时候并不会直接减少 map 处理数据量
列裁剪的好处:如果是结果表降低存储,如果是中间表可以减少下游任务读取时需要的计算资源
4.谓词下推特性 (Predicate Pushdown)
hive.optimize.ppd,默认为 true,即开启谓词下推 就是在不影响结果的情况下,尽量将过滤条件提前执行
谓词下推后,过滤条件在 map 端执行,减少了 map 端的输出,降低了数据在集群上传输的量,节约了集群的资源,也提升了任务的性能
SQL 聚合模式优化
Count(1),count(*),count(cloumn)的区别?
1. count((列):如果列中有 null 值, 那么这一列不会被记入统计的行数。
另外, Hive 读取数据进行计算时, 需要将字节流转化为对象的序列化和
反序列化的操作。
2. count(*):不会出现 count( 列) 在行是 null 值的情况下, 不计入行数的问题。 另外, count( *) 在进行数据统计时不会读取表中的数据, 只会使用到 HDFS 文件中每一行的行偏移量。 该偏移量是数据写入
HDFS 文件时,HDFS 添加的。
3.count(1)和 count(*) 目前版本的hive已经无区别hive.compute.query.using.stats=false;
当设置为 true 时,Hive 将完全使用存储在 metastore 中的统计
数据来回答一些查询,如 min, max 和 count(1)。对于基本统计信息的
收集,将配置属性 hive.stats.autogather 设置为 true。要获得更高级
的统计信息收集,要运行 ANALYZE TABLE 查询。Order by 全局排序优化
order by 只能是在一个 reduce 进程中进行,所以如果对一个大数据集进行 order by,会导致一个 reduce 进程中处理的数据相当大,造成查询执行缓慢。
不要在中间的大数据集上进行排序。如果最终结果较少,可以在一个 reduce 上进行排序时,那么就在最后的结果集上进行 order by
Order by 全局排序,取 TOP N 的优化方案
如果是去排序后的前 N 条数据,可以使用 distribute by 和 sort by 在各个reduce 上进行排序后前 N 条,然后再对各个 reduce 的结果集合合并后在一个reduce 中全局排序,再取前 N 条,因为参与全局排序的 order by 的数据量最多是 reduce 个数 * N,所以执行效率很高。如果不是非要全局有序的话,局部有序的话建议使用 sortby,它会视情况 启动多个 reducer 进行排序,并且保证每个 reducer 内局部有序。为了控制 map 端数据分配到 reducer 的 key,往往还要配合 distribute by 一同使 用。如果不加 distribute by 的话,map 端数据就会随机分配到 reducer
连接模式 Join 相关优化
无 shuffle 的 join

1. Map-join 优化
mapjoin 对于 full join 不生效,其次对于需要保留小表全量的情况下不生效(smalltable left join bigtable ,这个时候不生效)
2.Bucket-MapJoin 与 SMB-Map-join
1.Shuffle 和分桶的算法比较:
Shuffle 过程算法:按照 key 的 hash 值除以 reduceTask 个数进行取余
(reduce_id = key.hashcode % reduce.num)
Hive 分桶算法:按照分桶字段(列)的 hash 值除以分桶的个数进行取余
(bucket_id = column.hashcode % bucket.num) 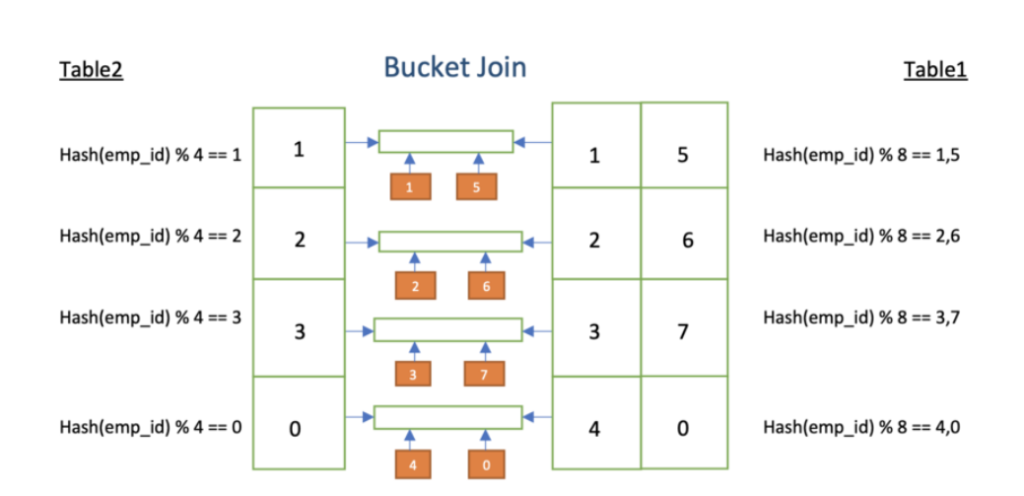
1.set hive.enfore.bucketing =true;
默认值为 false, 强制数据在插入表的时候分桶。 在 Hive 2.0 版本以后强制设置为 true, 并且删掉了 false 配置, 不允许用户进行更改, 因为如果创建的表是分桶并且该配置项为 false 的状态, Hive 可能会将数据插入到错误的桶中, 这可能导致 SM Join 获取到错误的结果。类似于分区中的hive.exec.dynamic.partition = true 属性。 通过设置此属性,我们将在将数据加载到 hive 表时启用动态分桶。
2.hive.enforce.sorting=true;
默认值为 false, 强制数据在插入表的时候排序,在 Hive 2.0 版本以后强制为 true, 并且删掉了false 配置, 不允许用户进行更改。 因为如果创建的表是排序的并且该配置项为 false 的状态, Hive 可能会以错误的顺序插入到表中, 这可能导致 SM Join 获取到错误的结果
3.hive.optimize.bucketingsorting=true;
默认值为 true, 表示是否优化分桶或者排序。 如果在hive.enforce.sorting 或者hive.enforce.bucketing 为 true 的状态, 不需要创建 Reduce 的任务去强制分桶或者排序
-----------------------------------分割线---------------------
4.hive.enforce.bucketmapjoin=true;
默认值为 false。 如果连接的两个表是桶表,分桶的键一样,分桶的个数是倍数关系, 开启该配置会强制将两个表由普通的 MapJoin 转化为桶 Bucket MapJoin
---------------------------------分割线 SMB-JOIN--------------
5. hive.optimize.bucketmapjoin.sortedmerge=true;
默认值为 false。 如果启用该配置, 在做 MapJoin 的两个表是桶表且排序的, 将会启用 sorted merge 连接以提高连接的性能。
Set hive.input.format=
org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true; Bucket-MapJoin实际上是不生效的,hive源码中并没有bucketmapjoinoperator
SMB-MapJoin 总结:
1. SMB-Mapjoin 只有 map,没有 reduce,map 个数等于最大分桶数,map 结束直接数写入 hive 表
2. SMB-Mapjoin 的启动不受 mapjoin 的大小表限制,适合大表 join 大表,前提需要提前设计好生成好对应的桶排序表
3. SMB-Mapjoin 弊端也很明显,比如换个表,换个 joinkey 则无法生效;但是也有好处:比如对于固定的大表 join 大表一般可以提高 join 效率。同时绝对要比非分桶表具有更快的抽样效率;但是是否比非分桶表一定节省时间,不一定;
4. SMB-Mapjoin 的使用条件:
1. 分桶表,其次是分桶排序表(需要用户保障)
2. 两个 join 的表 Join columns = Bucket columns = sort columns
3. 使用时需要开启相关的参数
5. SMB-MapJoin 建议使用场景:大表与大表 join 时,如果 key 分布均匀,单纯因为数据量过大,导致任务失败或运行时间过长,可以考虑将大表分桶,来优化任务
6. 直接使用 SMB-MapJoin,不要使用 Bucked Mapjoin 3.Skewed-Mapjoin(倾斜键 map 连接)
当 Join 操作中某个表中的一些 Key 数量远远大于其他(包含空值 null 值),则处理该 Key 的 Reduce 将成为任务单瓶颈,这个时候我们可以通过开启 Skewjoin 来实现在 map 端对倾斜健进行聚合
1. hive.optimize.skewjoin=false (默认)
--表示是否优化有倾斜键的表连接如果为 true, Hive 将为连接中的表的倾斜键创建单独的计划。简单来说该参数通过在 Hive 对物理执行计划优化时 ,添加一个 Map Join 用于处理 Skew Key .
2. hive.skewjoin.key =100000(默认值)。
-- 如果在进行表连接时, 相同键的行数多于该配置所指定的值, 则认为该键是倾斜连接键。简单说就是 Hive 的 reuce 任务会在处理 join key 的时候判断其数量是否大于该阈值,如果是将作为一个 Skew Join 处理
3.hive.skewjoin.mapjoin.map.tasks=10000( 默认值)
倾斜连接键在做 MapJoin 的 Map 任务个数。 需要与
hive.skewjoin.mapjoin.min.split 一起使用。
4.hive.skewjoin.mapjoin.min.split=33554432(默认即 32MB)。
指定每个 split 块最小值, 该值用于控制倾斜连接的 Map 任务个数。
5. hive.optimize.skewjoin.compiletime=false ( 默认值)
表示是否为连接中的表的倾斜键创建单独的计划 Skewed-Mapjoin 使用优化使用场景很有限,只有 INNER JOIN 的数据倾斜才可以实现优化
其次可以创建倾斜表,加速查询效率,但是这种方式弊端明显,就是提前设置了倾斜字段,一旦倾斜字段变动需要修改代码,其次有时候有些倾斜 无法提前预知
特别注意 Skewjoin 有个巨坑就是这个参数和 parallel 并行同时开启时会出现丢数据的问题
有 shuffle 的 join 优化
1.inner/left/right/join 的倾斜优化
通用场景的数据倾斜本质就是 shuffle 到某些个 reudce 的数据量过大,本质 优化手段就是减少往某些个 reduce 上 shuffle 的数据量。换个角度看数据倾斜本 质就是 key 分布不均匀。
数据倾斜解决思路很简单,如果 inner join 可以考虑用 skewjoin 优化,但是更多时候还是使用 commonjoin 的优化;
数据倾斜基本就两种情况
一是因为空值, null 值,特定脏数据等。这时候比如需要打散 key 值,这类处理成随机数即可。
二是热点值问题(一般处理死路热点值和非热点值分开处理)数据倾斜有时候很难的一点就是定位数据倾斜,尤其代码很长,多个 job 时需要定位具体倾斜的位置,倾斜的 key
1.1.null 值空值,或者说有规律的脏数据
加盐打散
On coalesce(t1.id, rand()*10000)=t2.id 1.2.大热点 key 值
拆分表,将大的热点值拆分成一张临时表,这里难就难在需要对数据很熟悉, 如何拆分热点值表;
--改造前
select A.id from A join B on A.id = B.id
--改造后
select A.id from A join B on A.id = B.id where A.id <> 1
union all
select A.id from A join B on A.id = B.id where A.id = 1 and B.id = 1;2.left-semi-join 的优化
LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在 ON 子句中设 置过滤条件,在 WHERE 子句、SELECT 子句或其他地方都不行。其次 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,而 join 则会一直 遍历。这就导致右表有重复值得情况下 left semi join 只产生一条,join 会产生 多条
left-semi-join有风险,应该全都改成in/exists语法
3.full -join 的优化
Full join 本质一句话查询两个表中所有满足条件的所有数据,使用唯一建议就使用子查询,不要再在 on 和 where 里进行过滤条件,很容易出问题;
4.cross -join 的优化
Hive 设定为严格模式(hive.mapred.mode=strict)时,不允许在 HQL 语 句中出现笛卡尔积
因为找不到 Join key,Hive 只能使用 1 个 reducer 来完成笛卡尔积。
4.1.小表对大表的笛卡尔乘积
笛卡尔乘积首先慎用,如果不可避免。
最有效的两种方式其一就是将小表膨胀 数倍,将大表拆分成小表膨胀的个数去关联注意单纯的 map-join 解决不了笛卡尔乘积的性能;
从表的数仓属性看,数仓里表的 join,一般就是维度表 join 事实表(大 VS 大),事实表 join 事实表(大 VS 大),其他维度表之间的关联;
HiveSQL 优化汇总
很长一段 hivesql 出现数据倾斜,如何排查哪段代码?
1.看任务执行慢在哪个 stage, 一般 Hive 默认的 jobname 名称会带上 stage 阶段
2. 确定了执行阶段,查看任务执行计划,再通过表的别名,关键字等判断出在 哪个阶段产生了数据倾斜
3.数据倾斜一般只有 join,groupby,count(distinct),找这些关键字
4.探查表数据,关键列名等;