
学习资料 – 第六章 Flink编程模型与API 枫叶云笔记 (fynote.com)
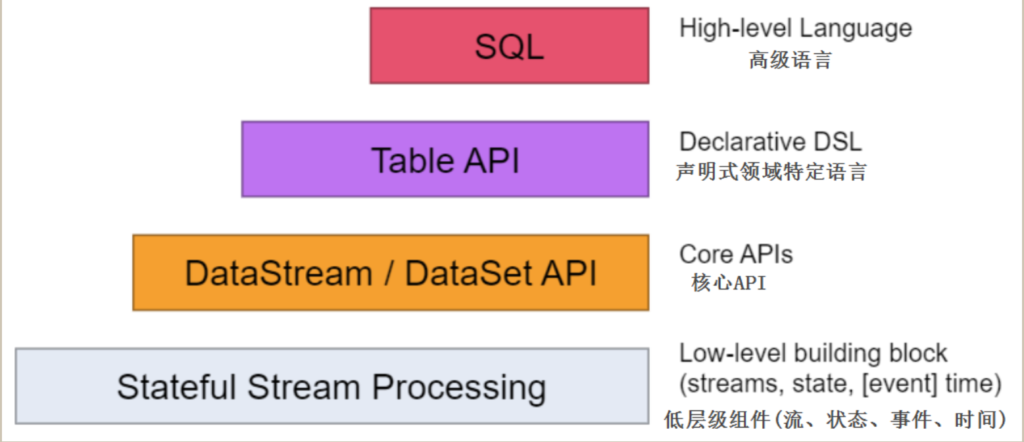
越上层的API,其描述性和可阅读性越强,越下层API,其灵活度高、表达力越强,多数时候上层API能做到的事情,下层API也能做到,反过来未必,不过这些API的底层模型是一致的,可以混合使用
官方建议使用Table API 或者SQL 来处理批数据,也可以使用带有Batch执行模式的DataStream API来处理批数据(DataSet和DataStream API做到了合并)
Flink编程模型
DataStream的编程模型包括以下几个部分:Environment、DataSource、Transformation、DataSink、触发执行。

Environment是编写Flink程序的基础,不同层级API编程中创建的Environment环境不同
Dataset 编程中需要创建ExecutionEnvironment
DataStream编程中需要创建StreamExecutionEnvironment
Table和SQL API中需要创建TableExecutionEnvironment使用不同语言编程导入的包也不同,在获取到对应的Environment后我们还可以进行外参数的配置,例如:并行度、容错机制设置等。
DataSource部分主要定义了数据接入功能,主要是将外部数据接入到Flink系统中并转换成DataStream对象供后续的转换使用
Transformation部分有各种各样的算子操作可以对DataStream流进行转换操作,最终将转换结果数据通过DataSink写出到外部存储介质中,例如:文件、数据库、Kafka消息系统等。
在DataStream编程中编写完成DataSink代码后并不意味着程序结束,由于Flink是基于事件驱动处理的,有一条数据时就会进行处理,所以最后一定要使用Environment.execute()来触发程序执行。
Flink数据类型
为了能够在分布式计算过程中对数据的类型进行管理和判断,Flink中定义了TypeInformation来对数据类型进行描述
通过TypeInfomation能够在数据处理之前将数据类型推断出来,而不是真正在触发计算后才识别出,这样可以有效避免用户在编写Flink应用的过程出现数据类型问题
常用的TypeInformation有BasicTypeInfo、TupleTypeInfo、CaseClassTypeInfo、PojoTypeInfo类等,针对这些常用TypeInfomation介绍如下:
1.Flink通过实现BasicTypeInfo数据类型,能够支持任意Java原生基本(或装箱)类型和String类型,例如:Integer,String,Double等,除了BasicTypeInfo外,类似的还有BasicArrayTypeInfo,支持Java中数组和集合类型;
2.通过定义TupleTypeInfo来支持Tuple类型的数据;
3.通过CaseClassTypeInfo支持Scala Case Class ;
4.PojoTypeInfo可以识别任意的POJOs类,包括Java和Scala类,POJOs可以完成复杂数据架构的定义,但是在Flink中使用POJOs数据类型需要满足以下要求:
4.1POJOs类必须是Public修饰且独立定义,不能是内部类;
4.2POJOs 类中必须含有默认空构造器;
4.3POJOs类中所有的Fields必须是Public或者具有Public修饰的getter和Setter方法;Flink序列化机制
在两个进程进行远程通信时,它们需要将各种类型的数据以二进制序列的形式在网络上传输,数据发送方需要将对象转换为字节序列,进行序列化,而接收方则将字节序列恢复为各种对象,进行反序列化Flink提供了多种序列化器,包括Kryo、Avro和Java序列化器等,大多数情况下,用户不用担心flink的序列化框架,Flink会通过TypeInfomation在数据处理之前推断数据类型,进而使用对应的序列化器
对于Kryo仍然无法处理的类型,可以采取以下两种解决方案:
1) 强制使用Avro替代Kryo序列化
//设置flink序列化方式为avro
env.getConfig().enableForceAvro();2) 自定义注册Kryo序列化
//注册kryo 自定义序列化器
env.getConfig().registerTypeWithKryoSerializer(Class<?> type, Class<? extends Serializer> serializerClass)