
学习资料 – 第七章 Flink状态管理与容错 枫叶云笔记 (fynote.com)
分布式系统中常用这么几种语义(semantics)来描述系统在经历了故障恢复后,内部各个组件之间状态的一致性。严格程度从高到低为:exactly once(准确一次)、at least once(至少一次)、at most once(最多一次)。
下面以一个例子分别解释以上三种一致性语义的界定。
数据源S发送给算子A数据1,2,3,4,5…,由A进行累加,也就是sum。A中的状态就是累加的和,S的状态就是当前已发送的流(因为A的当前结果和S之前发送的所有数据都有关)。一开始,S发出了1,2,3。A的状态依次更新为1,3,6。当S发出4的时候,A出现了故障。现在S和A的状态分别是S:1,2,3,4,A:6。
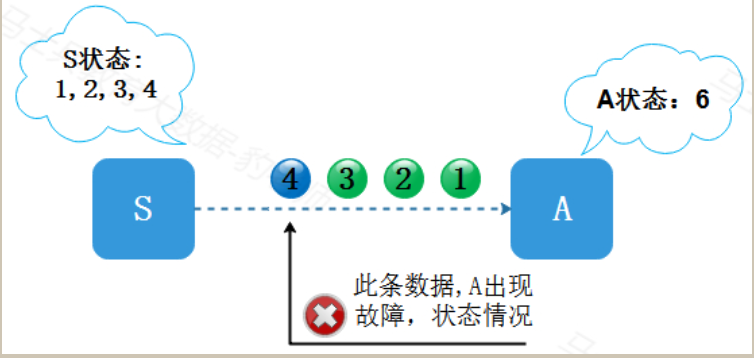
at most once (最多消费一次)
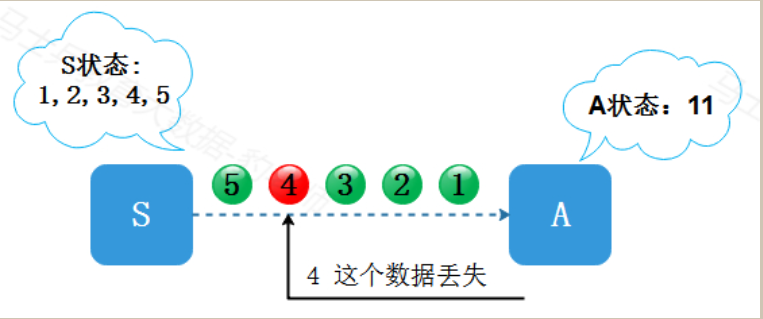
S不知道A发生了故障,随后系统从故障中恢复,A收到了S发送的下一条数据“5”,数据“4”实际上被丢失了。这时S的发送历史是1,2,3,4,5,A的状态是11。而“1,2,3,4,5”所对应的累加和应该是15,所以S和A就出现了状态不一致,S认为A的状态包含了“4”,而A实际上没有。这样就导致“4”这条数据永久丢失,这种程序从故障恢复的语义就是at most once 语义。
exactly once (精准消费一次)
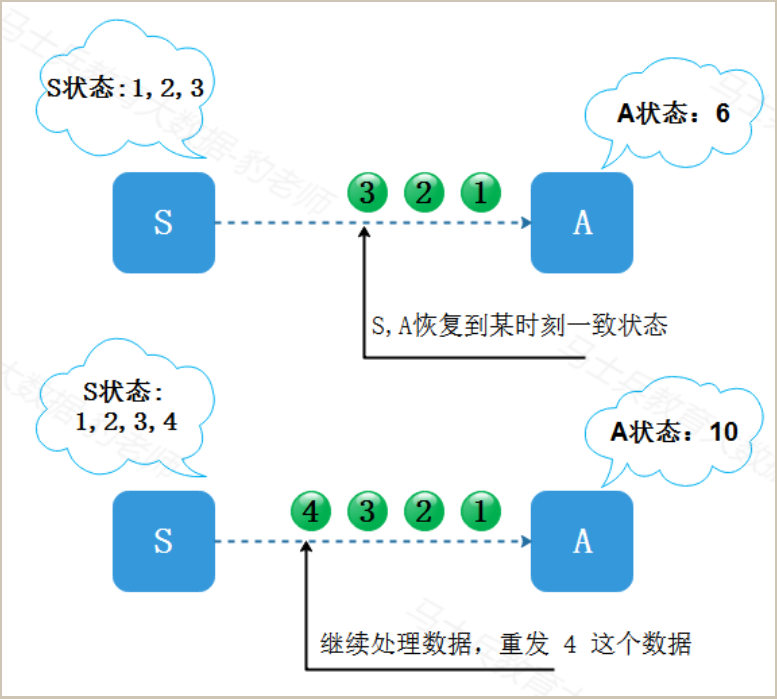
回到状态S:1,2,3,4,A:6的时间点,假设这时S知道A有故障,并且A没有处理“4”,系统从故障中恢复之后,S和A都退回到上一个一致的状态,然后重新开始运算。比如上一个一致的状态是:S:1,2,3, A:6,那么S回退之后会重发“4”。如果A成功处理“4”,现在的状态就变成:S:1,2,3,4, A:10。S和A的状态就是一致的。如果上一个一致的状态是:S:1,2, A:3,那么S回退之后会从“3”开始重发。这种程序从故障恢复的语义就是exactly once 语义。
以上这个过程我们假定的是A没有处理“4”这条数据,那么还有可能是A已经处理了“4”,然后A在通知S“4已处理”之前挂了,这时S不知道A已经处理了“4”,所以为了确保一致性,在恢复程序时,S必须假设A没有处理”4″,因此S和A仍然要一起退回上一个一致的状态,并且从一致的状态重新开始运算。比如说:S:1,2,3, A:6。S重发“4”并且被A处理之后,虽然A实际上处理了“4”两次,但A第一次处理“4”之后的状态在故障之后弃用了。所以在A当前的状态中,“4”只被处理了一次,这也是exactly once处理语义。
at least once(至少消费一次)
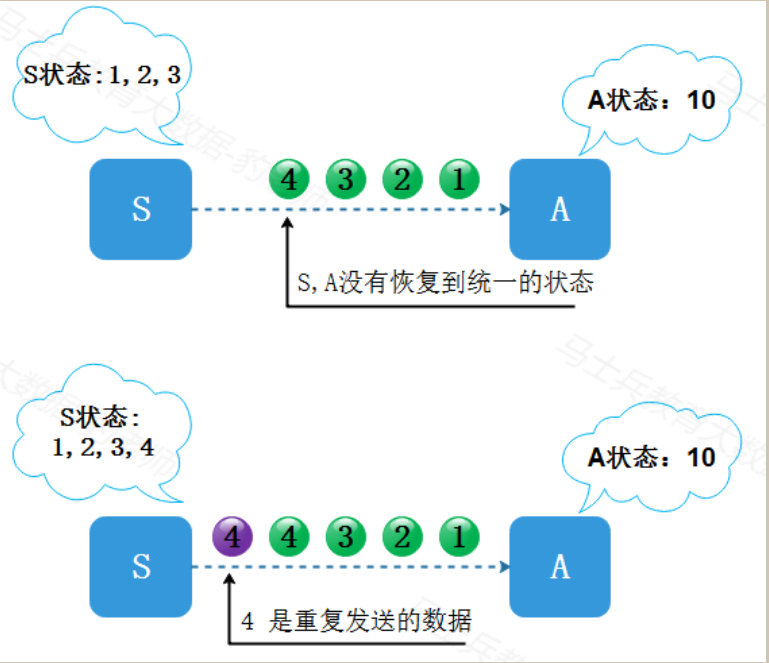
同样回到状态S:1,2,3,4,A:6的时间点,但是S和A没有一起退回上一个一致的状态,比如说在程序恢复之后,两者的状态为:S:1,2,3, A: 10。这时,S重发“4”,状态变为S:1,2,3,4 A: 14,当前状态下,“4”被处理了两次,且状态不一致。这种程序从故障恢复的语义就是at least once 语义。
通过以上的了解,我们发现exactly-once语义中无论一条数据被重复处理多少次,只要影响最后结果是一次,那么这种我们也称为是exactly-once语义保证,这个就是所谓的幂等(idempotent)操作(执行多次与执行一次的效果相同)。
Flink写出Kafka exactly once 保证
checkpoint+两阶段提交保证exactly once语义
kafka0.11版本之后支持事务,这也是Flink与kafka交互时仅一次处理的必要条件
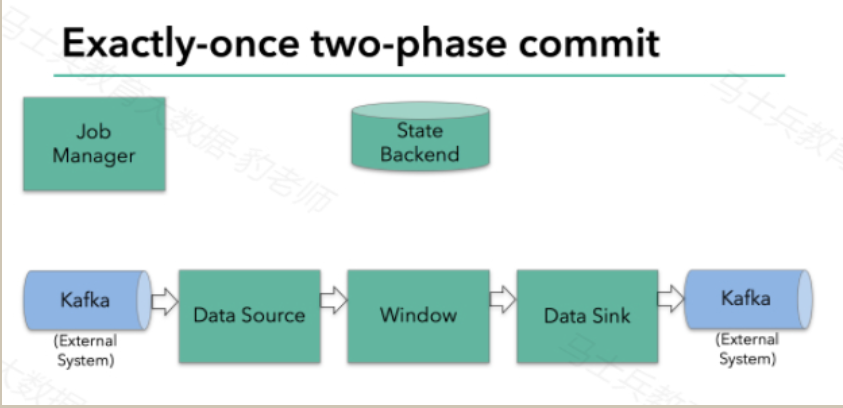
要使sink支持仅一次处理数据语义,必须以事务的方式将数据写往kafka,将两次checkpoint之间的操作当做一个事务提交,确保出现故障时操作能够被回滚。假设出现故障,在分布式多并发执行sink的应用程序中,仅仅执行单次提交或回滚事务是不够的,因为分布式中的各个sink程序都必须对这些提交或者回滚达成共识,这样才能保证两次checkpoint之间的数据得到一个一致性的结果。Flink使用两阶段提交协议(pre-commit+commit)来实现这个问题。
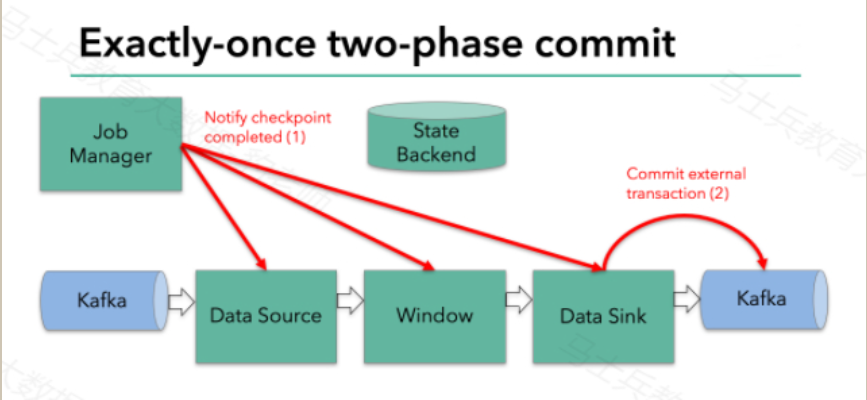
Filnk checkpointing开始时就进入到pre-commit阶段,具体来说,一旦checkpoint开始,Flink的JobManager向输入流中写入一个checkpoint barrier将流中所有消息分隔成属于本次checkpoint的消息以及属于下次checkpoint的消息,barrier也会在操作算子间流转,对于每个operator来说,该barrier会触发operator的State Backend来为当前的operator来打快照。如下图示:
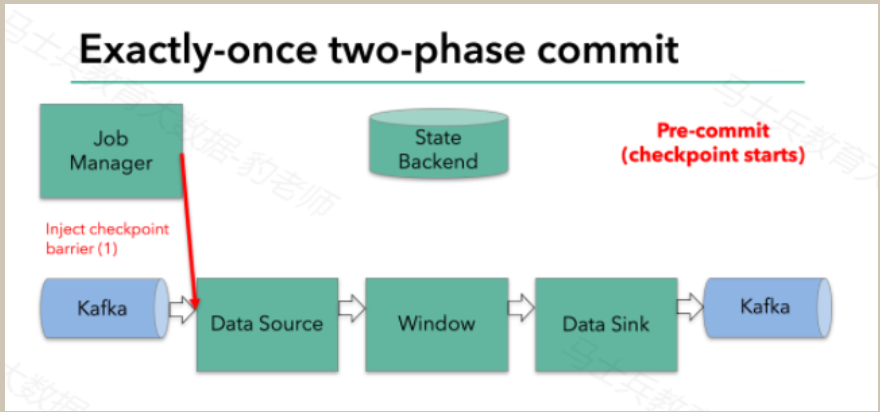
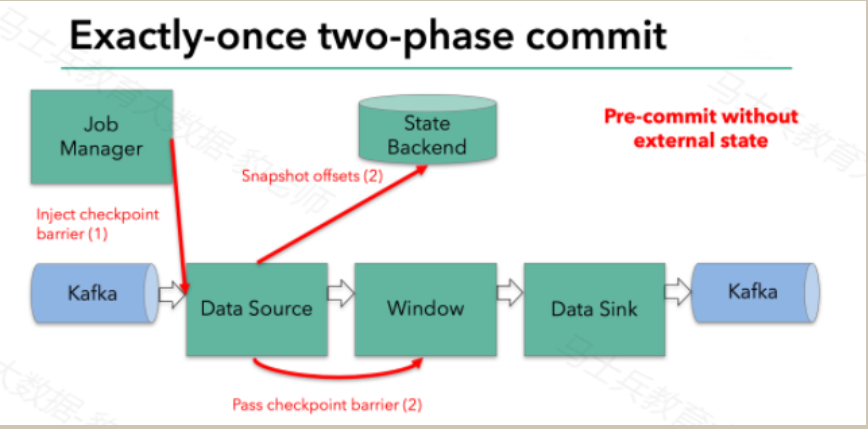
Flink DataSource中存储着Kafka消费的offset,当完成快照保存后,将chechkpoint barrier传递给下一个operator。这种方式只有在Flink内部状态的场景是可行的,内部状态指的是由Flink的State Backend管理状态,例如上面的window的状态就是内部状态管理。只有当内部状态时,pre-commit阶段无需执行额外的操作,仅仅是写入一些定义好的状态变量即可,checkpoint成功时Flink负责提交这些状态写入,否则就不写入当前状态。
但是,一旦operator操作包含外部状态,事情就不一样了。我们不能像处理内部状态一样处理外部状态,因为外部状态涉及到与外部系统的交互。这种情况下,外部系统必须要支持可以与两阶段提交协议绑定的事务才能保证仅一次处理数据。
本例中的data sink是将数据写往kafka,因为写往kafka是有外部状态的,这种情况下,pre-commit阶段下data sink 在保存状态到State Backend的同时,还必须pre-commit外部的事务。如下图:
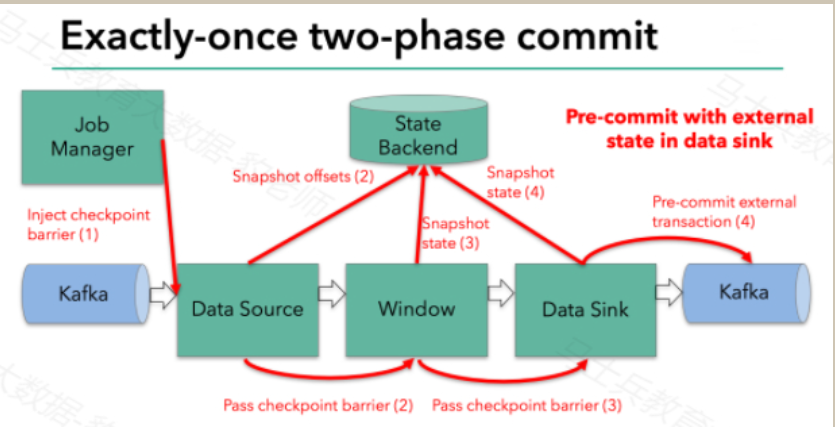
当checkpoint barrier在所有的operator都传递一遍切对应的快照都成功完成之后,pre-commit阶段才算完成。这个过程中所有创建的快照都被视为checkpoint的一部分,checkpoint中保存着整个应用的全局状态,当然也包含pre-commit阶段提交的外部状态。当程序出现崩溃时,我们可以回滚状态到最新已经完成快照的时间点。
下一步就是通知所有的operator,告诉它们checkpoint已经完成,这便是两阶段提交的第二个阶段:commit阶段。这个阶段中JobManager会为应用中的每个operator发起checkpoint已经完成的回调逻辑。本例中,DataSource和Winow操作都没有外部状态,因此在该阶段,这两个operator无需执行任何逻辑,但是Data Sink是有外部状态的,因此此时我们需要提交外部事务。如下图示:
总结:
一旦所有的operator完成各自的pre-commit,他们会发起一个commit操作。
如果一个operator的pre-commit失败,所有其他的operator 的pre-commit必须被终止,并且Flink会回滚到最近成功完成的checkpoint位置。
一旦pre-commit完成,必须要确保commit也要成功,内部的operator和外部的系统都要对此进行保证。假设commit失败【网络故障原因】,Flink程序就会崩溃,然后根据用户重启策略执行重启逻辑,重启之后会再次commit。Flink任务重启与恢复策略
当Flink程序运行失败时,Flink会自动处理任务的重启和恢复,以使任务能够重新回到正常状态。重启策略(Restart Strategies)和故障恢复策略(Failover Strategies)在这个过程中起着关键作用,重启策略决定何时以及是否重新启动失败或受影响的task任务,而故障恢复策略则决定哪些task任务应该被重新启动,以便整个Flink程序能够恢复正常运行状态。
重启策略(Restart Strategies)
默认情况下,Flink使用配置文件”flink-conf.yaml”来设置重启策略,在该文件中,可以通过配置”restart-strategy.type”来选择所需的重启策略。
如果Flink没有启用检查点(checkpoint),默认的重启策略是”no restart”,这意味着任务在失败后不会被重新启动。如果Flink启用了检查点并且没有配置特定的重启策略,那么默认的重启策略是”fixed-delay”策略,即固定延迟启动,重试次数为Integer.MAX_VALUE。
重启策略“restart-strategy.type”参数可以配置以下可用的重启策略:
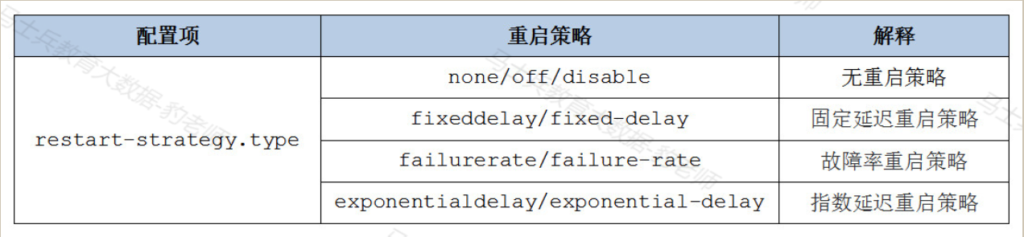
无重启策略
Flink 任务失败,不尝试重新启动,如果Flink没有开启checkpoint,默认就是这种重启策略。可以在Flink集群flink-conf.yaml配置文件配置该重启策略:
restart-strategy.type: none也可以在编写Flink代码时配置:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());固定延迟重启策略(fixed delay)
固定延迟重启策略尝试给定次数来重启Flink作业,如果超过最大尝试次数,则Flink作业最终失败,在两次连续的重启尝试之间可以配置等待的间隔时间。如果Flink开启了checkpoint并没有特别指定重启策略,那么默认就是使用“fixed delay”这种重启策略。
可以在Flink集群flink-conf.yaml配置文件中配置该重启策略:
restart-strategy.type: fixed-delay
#重启次数,默认1次
restart-strategy.fixed-delay.attempts: 3
#重启等待间隔,默认1s
restart-strategy.fixed-delay.delay: 10 s也可以在编写Flink代码时配置:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(10, TimeUnit.SECONDS) // delay
));故障率重启策略(failure rate)
故障率重启策略当Flink作业失败后重新启动Flink作业,但当超过故障率(每个测量故障次数时间间隔的失败次数)时,作业最终会失败。在两次连续的重启尝试之间可以配置等待的间隔时间。
可以在Flink集群flink-conf.yaml配置文件中配置该重启策略:
restart-strategy.type: failure-rate
#在测量故障率的时间间隔内,Flink作业允许失败最大次数,默认1
restart-strategy.failure-rate.max-failures-per-interval: 3
#测量故障率的时间间隔,默认1min,可以设置1 min/20 s格式
restart-strategy.failure-rate.failure-rate-interval: 5 min
#任务重试的时间间隔,默认1s,可以设置1 min /20 s格式
restart-strategy.failure-rate.delay: 10 s也可以在编写Flink代码时配置:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // max failures per interval
Time.of(5, TimeUnit.MINUTES), //time interval for measuring failure rate
Time.of(10, TimeUnit.SECONDS) // delay
));指数延迟重启策略(exponential delay)
指数延迟重启策略尝试无限次重启Flink作业,不断增加延迟时间直至最大延迟时间。在两次连续的重启尝试之间,重启策略会呈指数增长,直到达到最大延迟时间并将延迟时间保持在最大值。当作业正确执行时,指数延迟时间值在一段时间阈值后重置,该时间阈值是可配置的。
可以在Flink集群flink-conf.yaml配置文件中配置该重启策略:
restart-strategy.type: exponential-delay
#初始延迟,默认1s,可以设置1 min/20 s格式
restart-strategy.exponential-delay.initial-backoff: 10 s
#最大延迟,默认5分钟,可以设置1 min/20 s格式
restart-strategy.exponential-delay.max-backoff: 2 min
#每次失败后,延迟时间乘以此值作为新的延迟时间,直到达到最大延迟,默认值2.0
restart-strategy.exponential-delay.backoff-multiplier: 2.0
#作业运行多长时间后,延迟时间恢复为初始延迟,默认之为1小时
restart-strategy.exponential-delay.reset-backoff-threshold: 10 min
#随机偏移值,在延迟基础上随机加上或者减去该值乘以延迟值,防止多个job同时重启,默认值为0.1
restart-strategy.exponential-delay.jitter-factor: 0.1也可以在编写Flink代码时配置:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.exponentialDelayRestart(
Time.milliseconds(1), // inital backoff
Time.milliseconds(1000), // max backoff
1.1, // backoff multiplier
Time.milliseconds(2000), // threshold duration to reset delay to its initial value
0.1 // jitter factor
));注意:以上各种重启策略代码中设置可以覆盖集群flink-conf.yaml文件配置。
故障恢复(Failover Strategies)
Flink支持不同的故障恢复策略,这些策略可以通过flink-conf.yaml文件中参数jobmanager.execution.failover-strategy进行配置。

在“全部重启”故障恢复策略中,Task发生故障时,会重启Flink作业中所有的Task,“局部重启”故障恢复策略中,会将任务分组为不相交的区域,当检测到Task故障时,该策略计算出必须重新启动的最小区域集合从故障中恢复,与“全部重启”策略相比,这种策略重新启动的任务数量较少。