
学习资料 – 第九章 Flink Table API与SQL (二) 枫叶云笔记 (fynote.com)
Flink SQL 是 Apache Flink 中强大且灵活的查询方式,Flink SQL 支持标准的 ANSI SQL 语法,基于 Apache Calcite 解析 SQL,保留识别符大小写,相较于 Flink Table API,SQL编程更为简单且支持多样化的查询操作。
Flink SQL 支持数据定义语言(DDL)、数据操作语言(DML)和查询语言,涵盖了 SELECT、CREATE、DROP、ALTER、ANALYZE、INSERT、UPDATE、DELETE 等操作。同时,Flink SQL 支持多种数据类型,包括复合类型,如 POJOs、元组、Rows以及 Scala case 类型,这些复合类型的字段可以通过SQL内置函数来访问,支持任意层次的嵌套。
Apache Calcite 是一个开源的、高度可定制的 SQL 解析器和查询优化框架。它能够将输入的 SQL 查询语句解析成一个语法树,然后进行语义分析和查询优化,最终生成执行计划。
窗口与聚合
Apache Flink 1.13版本以后提供了以下几种窗口表值函数(TVF)来定义窗口:
1.滚动窗口(Tumbling Windows)
2.滑动窗口(Hop Windows)
3.累积窗口(Cumulate Windows)目前在Flink SQL中还不支持Session会话窗口,未来版本会支持。
滚动窗口(Tumbling Windows)
在Flink SQL中Tumbling Window 滚动窗口与Table API或者DataStream API中的滚动窗口一样,滚动窗口需要指定固定长度并且不会重叠。
Flink SQL中通过TUMBLE表值函数来设置滚动窗口,如下:
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])TUMBLE参数解释如下:
data:指定Table 表。
timecol:指定表中的时间列,必须是TIMESTAMP或者TIMESTAMP_LTZ类型。
size:指定窗口长度,即多久生成一个窗口。
offset:可选参数,指定窗口偏移量。TUMBLE表值函数会根据时间属性字段分配滚动窗口。在流处理模式下,时间属性字段必须是事件时间或处理时间属性。在批处理模式下,窗口表函数的时间属性字段必须是TIMESTAMP或TIMESTAMP_LTZ类型的属性。
TUMBLE的返回值包括原始关系的所有列,以及额外的三列,分别命名为“window_start”(窗口起始时间)、“window_end”(窗口结束时间)和“window_time”(窗口时间),这里的window_time窗口时间表示该窗口中包含的事件时间最大值,该值为window_end-1ms。
原始时间属性“timecol”将在窗口表值函数之后成为常规的时间戳列。
//SQL TumblingWindow Table result = tableEnv.sqlQuery("select " + "sid,window_start,window_end,sum(duration) as sum_dur " +
"from TABLE(" +
" TUMBLE(TABLE stationlog_tbl,DESCRIPTOR(time_ltz), INTERVAL '5' SECOND)" +
") " +
"group by sid,window_start,window_end");滑动窗口(Hop Windows)
Flink SQL中的滑动窗口与Table API和DataStream API中的滑动窗口类似,可以指定参数设置窗口大小,同时还需要指定参数控制窗口多久滑动一次,滑动窗口可以有重叠。
Flink SQ中通过HOP 表值函数来设置滑动窗口
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])HOP参数解释如下:
data:指定Table 表。
timecol:指定表中的时间列,必须是TIMESTAMP或者TIMESTAMP_LTZ类型。
slide:指定窗口滑动间隔时间。
size:指定窗口长度。
offset:可选参数,指定窗口偏移量。HOP表值函数在流处理模式下,时间属性字段必须是事件时间或处理时间属性,在批处理模式下,窗口表函数的时间属性字段必须是TIMESTAMP或TIMESTAMP_LTZ类型的属性。
与TUMBLE表值函数一样,HOP的返回值包括原始关系的所有列,以及额外的三列,分别命名为“window_start”(窗口起始时间)、“window_end”(窗口结束时间)和“window_time”(窗口时间),这里的window_time窗口时间表示该窗口中包含的事件时间最大值,该值为window_end-1ms。
原始时间属性“timecol”将在窗口表值函数之后成为常规的时间戳列。
//SQL TumblingWindow
Table result = tableEnv.sqlQuery("select " +
"sid,window_start,window_end,sum(duration) as sum_dur " +
"from TABLE(" +
" HOP(TABLE stationlog_tbl,DESCRIPTOR(time_ltz), INTERVAL '5' SECOND , INTERVAL '10' SECOND)" + ") " +
"group by sid,window_start,window_end");累积窗口(Cumulate Windows)
累积窗口是Flink SQL中特有的窗口函数。
当统计周期较长时,需要在统计周期内间隔输出某指标的统计值,并且这些输出的值是逐步累积的,这种情况下滚动窗口和滑动窗口就不能满足需求,这种场景中就可以使用累积窗口来解决。
Flink SQL中通过CUMULATE 表值函数来设置累积窗口:
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)CUMULATE 参数解释如下:
data:指定Table 表。
timecol:指定表中的时间列,必须是TIMESTAMP或者TIMESTAMP_LTZ类型。
step:指定窗口累积步长,即多久输出一次累积结果。
size:指定窗口长度,即多久生成一个窗口。CUMULATE 表值函数在流处理模式下,时间属性字段必须是事件时间或处理时间属性,在批处理模式下,窗口表函数的时间属性字段必须是TIMESTAMP或TIMESTAMP_LTZ类型的属性。
与TUMBLE表值函数一样,CUMULATE 的返回值包括原始关系的所有列,以及额外的三列,分别命名为“window_start”(窗口起始时间)、“window_end”(窗口结束时间)和“window_time”(窗口时间),这里的window_time窗口时间表示该窗口中包含的事件时间最大值,该值为window_end-1ms。
原始时间属性“timecol”将在窗口表值函数之后成为常规的时间戳列。
//SQL TumblingWindow
Table result = tableEnv.sqlQuery("select " +
"sid,window_start,window_end,sum(duration) as sum_dur " +
"from TABLE(" +
" CUMULATE(TABLE stationlog_tbl,DESCRIPTOR(time_ltz), INTERVAL '5' SECOND , INTERVAL '1' DAY)" +
") " +
"group by sid,window_start,window_end");Over开窗函数
Flink SQL中开窗函数语法如下:
SELECT
agg_func(agg_col) OVER (
[PARTITION BY col1[, col2, ...]]
ORDER BY time_col
range_definition
), ...
FROM ...以上语句中的解释如下:
1.agg_fun:指定聚合函数,例如SUM、AVG、MAX、MIN、COUNT等。
2.PARTITION BY:可选项,用于将结果集划分成不同的分组,类似group by。在Flink流式处理中,如果不指定partition by 而设置Over开窗函数,则Flink所有数据分到一个分组中,并由一个并行度处理。
3.ORDER BY:按照给定的排序列对分组的数据进行排序,排序列可以基于事件也可以基于数量,但如果是Flink流处理,只支持按照时间属性的升序排列。
4.range_definition:用于定义窗口聚合的行范围,该范围通过BETWEEN语句定义窗口上下限:BETWEEN <下界> AND <上界>,边界的行也包含在聚合中,Flink仅支持CURRENT ROW 作为窗口上边界。可以通过RANGE Intervals和Rows Intervals来定义窗口聚合范围。#基于RANGE Intervals定义Over窗口聚合范围
RANGE BETWEEN INTERVAL '30' MINUTE PRECEDING AND CURRENT ROW
#基于Rows Intervals定义Over窗口聚合范围
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
示例代码如下:SELECT order_id, order_time, amount,
SUM(amount) OVER w AS sum_amount,
AVG(amount) OVER w AS avg_amount
FROM Orders
WINDOW w AS (
PARTITION BY product
ORDER BY order_time
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW)Joins
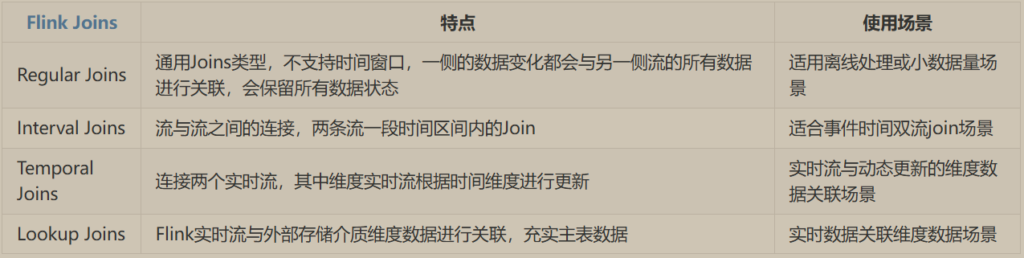
常规Join(Regular Joins)
间隔Join(Interval Joins)
时态Join(Temporal Joins)
维度Join(Lookup Join)常规Join(Regular Joins)
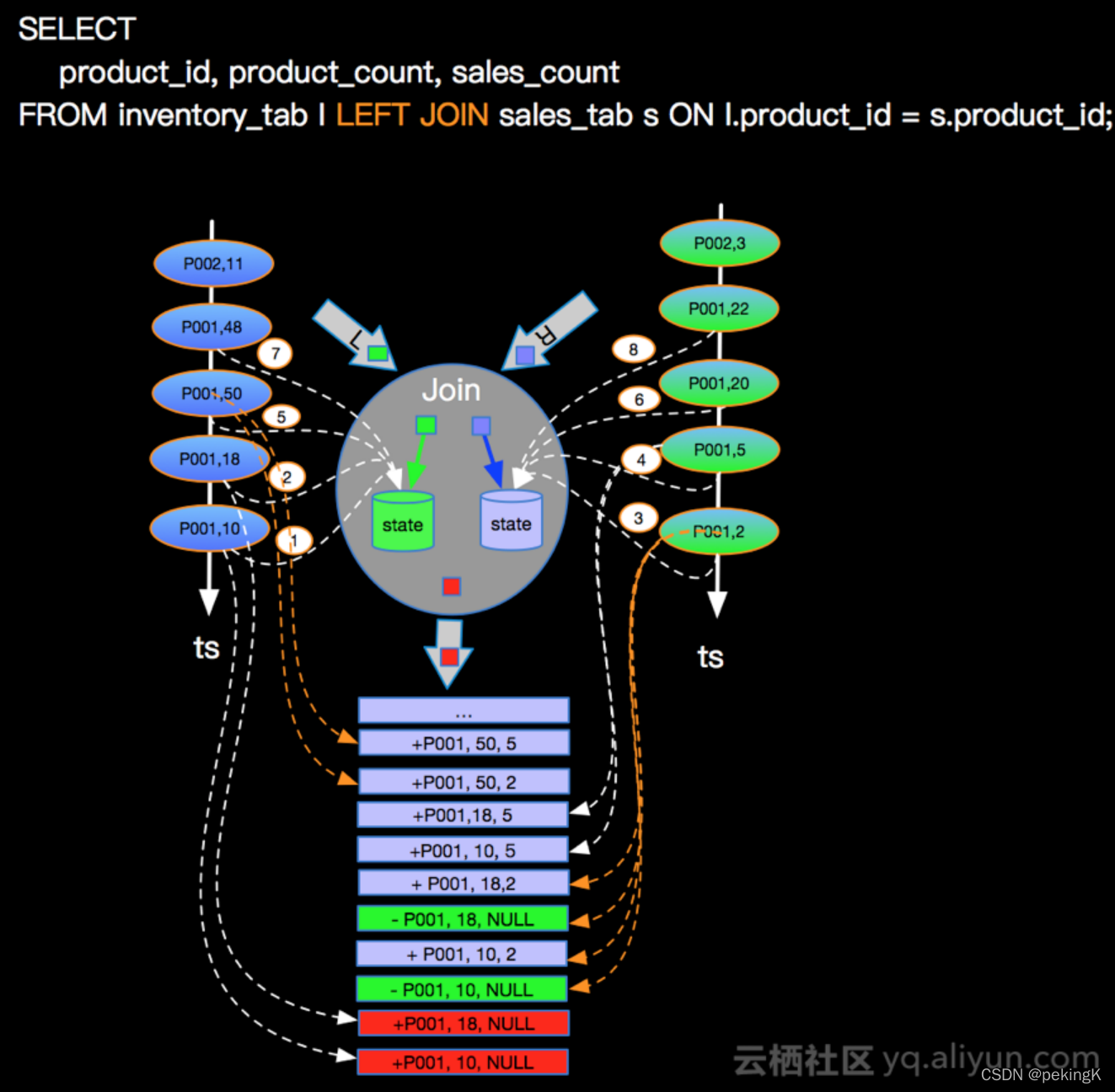
常规Join是最通用的连接类型,包括INNTER JOIN、LEFT JOIN、RIGHT JOIN、FULL OUTER JOIN。
Flink 两表关联通过ON指定关联条件,目前只支持等值连接,两流中的数据都会被保存到状态中,只要关联条件匹配,任意流中INSERT和UPDATE操作都会导致结果输出。
在Flink SQL中使用Join时,最好设置状态的存活时间,避免状态的无限增长。
#INNTER JOIN
SELECT *
FROM Orders
INNER JOIN Product
ON Orders.product_id = Product.id
#LEFT JOIN
SELECT *
FROM Orders
LEFT JOIN Product
ON Orders.product_id = Product.id
#RIGHT JOIN
SELECT *
FROM Orders
RIGHT JOIN Product
ON Orders.product_id = Product.id
#FULL OUTER JOIN
SELECT *
FROM Orders
FULL OUTER JOIN Product
ON Orders.product_id = Product.id间隔Join(Interval Joins)
Flink SQL中的Interval Join与 Table API中Interval Join一样,可以在指定时间区间内关联两个流数据,Interval Join基于时间区间进行关联,使用时至少需要一个等值join关联条件和一个限制两个流关联时间范围的条件,限制时间范围的条件可以基于两流ProcessTime/EventTime来定义。
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_time指定两流关联时间范围的有效设置如下:
ltime = rtime
ltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTE
ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND时态Join(Temporal Joins)
Flink SQL中也支持使用时态表,通过时态表可以追踪表中的数据变化、访问数据历史版本数据。时态表不能单独使用,只能与其他表进行Join关联时使用。
与Flink Table中使用时态表一样,在SQL编程中创建时态表需要使用主键约束和事件时间,只要定义一张表时包含事件时间和主键约束,那么这张表就是时态表。
-- 定义一张时态表
CREATE TABLE product_changelog (
product_id STRING,
product_name STRING,
product_price DECIMAL(10, 4),
update_time TIMESTAMP(3),
PRIMARY KEY(product_id) NOT ENFORCED, -- (1) 定义主键约束
WATERMARK FOR update_time AS update_time -- (2) 通过 watermark 定义事件时间
) WITH (
'connector' = 'kafka',
'topic' = 'products',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'debezium-json'
);在SQL编程中创建时态表有以下注意点:
1.创建时态表函数时需要指定时间属性和主键。时间属性格式必须为TIMESTAMP/TIMESTAMP_LTZ,指定主键主要是保证该时态表中数据能按照主键进行更新或删除。
2.时态表中必须为CDC(Change Data Capture,数据变更捕获)数据,即数据是有增删改查的UNBOUND实时流,不能是BOUND有边界的流。
3.在读取Kafka中数据时如果设置主键定义时态表,“format”不能是单独的“json”格式,这里指定为“debezium-json”格式,这种格式支持Flink SQL 从Kafka中读取数据时读取 INSERT / UPDATE / DELETE 消息,以支持Kafka Connector表的主键。1. Event Time Temporal Join
基于事件时间构建的时态表与其他表进行Join关联时,支持LEFT JOIN和INNER JOIN,时态表必须作为Join关联的右表放在右侧,使用示例如下:
SELECT [column_list]
FROM table1 [AS <alias1>]
[LEFT] JOIN table2 FOR SYSTEM_TIME AS OF table1.rowtime [AS <alias2>]
ON table1.column-name1 = table2.column-name1Flink SQL中通过“FOR SYSTEM_TIME AS OF…”语法来指定左表的事件时间列,以便在时态表中查询该时间对应的版本数据。
基于EventTime的时态表中会存储上一个watermark到当前时刻的所有版本数据,watermark之前的数据不会存储。
基于Event Time 的时态表查询除了以上这种SQL Join关联方式外,还可以通过定义时态表函数来查询时态表中的数据,目前时态表函数仅支持通过Table API方式定义,不支持SQL DDL方式定义。
#currency_rates为创建的时态表,定义时态表函数
TemporalTableFunction rates = tEnv
.from("currency_rates")
#指定“update_time”为时间属性,“currency”为主键
.createTemporalTableFunction("update_time", "currency");
#创建和注册时态表函数,这样可以在SQL中使用rates函数
tEnv.createTemporarySystemFunction("rates", rates);
#SQL方式从时态表中查询数据
SELECT
rate,amount,...
FROM
orders,
LATERAL TABLE (rates(order_time))
WHERE rates.currency = orders.currency2. Processing Time Temporal Join
基于Processing Time的时态表中就不存在数据版本的概念,这种时态表中存储的数据只有对应主键的最新版本,其他表在与基于Processing Time的时态表进行关联时,不支持SQL “FOR SYSTEM_TIME AS OF…”语法关联方式,只支持使用时态表函数从时态表中查询数据,通过“LATERAL TABLE”进行关联,时态表函数也是作为右表放在关联的右侧,永远返回对应主键的最新值,使用方式同Event Time Temporal Join 中时态表函数使用方式。
//SQL 方式实现 Temporal Join
Table result = tableEnv.sqlQuery("" +
"select " +
" left_product_id,left_visit_time,right_product_name,right_price " +
"from visit_tbl v,LATERAL TABLE (temporalTableFunction(left_time_ltz)) " +
"WHERE left_product_id = right_product_id" );维度Join(Lookup Join)
Lookup Join 通常用于从外部系统查询维度数据丰富Flink主表,使用Lookup Join时要求左表(主表)必须有ProcessingTime时间列,维度表通过connector连接器获取,作为右表放在右侧。
在查询方式上 Lookup Join 与查询Temporal Join用法一样,通过“FOR SYSTEM_TIME AS OF …”语法来完成,并指定左右表关联的条件列。Lookup维度表Temporal时态表相比,Lookup维表中没有时间列,而Temporal 时态表中有时间列。
所以Lookup Join在一定程度上也可以看成是基于ProcessingTime 的Temporal Join。
-- 创建Lookup 维度表
CREATE TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
'table-name' = 'customers'
);
-- 从维表中查询数据
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;SQL Joins对比
Window Join
Flink SQL中支持窗口连接(Window Join),允许在两个时间窗口进行Join连接。
Window Join要求Join on条件中必须要有左右窗口的开始时间和结束时间相等条件。与SQL中普通Join不同,窗口连接不产生中间结果,而只在窗口的末尾产生最终结果,且Flink自动清理不再需要的窗口状态。
Flink SQL中Window Join支持INNER/LEFT/RIGHT/FULL OUTER/ANTI/SEMI JOIN,这些Window Join 在使用时都会通过窗口表值函数(TVF)来设置窗口,左右两表设置的窗口类型目前必须一致,Flink未来版本有可能支持左右表设置不同窗口类型。这里把INNER/LEFT/RIGHT/FULL OUTER统称为COMMON Join。
通用Join(COMMON Join)
SELECT ...
FROM L [LEFT|RIGHT|FULL OUTER] JOIN R -- L 和R 是左右窗口
ON L.window_start = R.window_start AND L.window_end = R.window_end AND ...//SQL 方式实现 Window Full Outer Join
TableResult result = tableEnv.executeSql("" +
"SELECT " +
" L.id," +
" L.name," +
" L.age," +
" R.score," +
" COALESCE(L.window_start,R.window_start) as window_start ," +
" COALESCE(L.window_end,R.window_end) as window_end " +
"FROM (" +
" SELECT * FROM TABLE(TUMBLE(TABLE left_tbl,DESCRIPTOR(rowtime), INTERVAL '5' SECOND))" +
") AS L " +
"FULL OUTER JOIN (" +
" SELECT * FROM TABLE(TUMBLE(TABLE right_tbl,DESCRIPTOR(rowtime), INTERVAL '5' SECOND))" +
") AS R " +
"ON L.id = R.id AND L.window_start = R.window_start AND L.window_end = R.window_end");半连接(SEMI Join)
半连接(SEMI JOIN) 这种连接操作用于从一个表中选择那些在另一个表中存在的数据行,可以通过“where … in”或者“where exists”语句实现半连接查询
#where...in语句半连接
SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE L.num IN (
SELECT num FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R
WHERE L.window_start = R.window_start AND L.window_end = R.window_end
);
#where exists 语句半连接
SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE EXISTS (
SELECT * FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R
WHERE L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end
);反连接(ANTI Join)
反连接(ANTI JOIN) 与半连接(SEMI JOIN)类似,半连接可以从一个表中选择那些在另一个表中存在的数据行,而反连接可以从一个表中选择那些不存在另一个表中的数据行。
反连接使用方式有“where…not in …”和“where not exists…”两种方式。
#where...not in 语句反连接
SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE L.num NOT IN (
SELECT num FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R WHERE L.window_start = R.window_start AND L.window_end = R.window_end
);
#where not exists ... 语句反连接
SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE NOT EXISTS (
SELECT * FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R WHERE L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end
);Top-N
TOP-N查询是指按照表中某列排序获取前N个最大或者最小值,在Flink SQL中可以通过Over开窗函数实现针对批或流的TOP-N数据获取。
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER (
[PARTITION BY col1[, col2...]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]
) AS rownum
FROM table_name
)
WHERE rownum <= N [AND conditions]目前在Flink SQL中仅支持ROW_NUMBER() 函数,不支持RANK() OVER和DENSE_RANK()函数。
Window Top-N
Flink SQL中针对每个窗口内的数据也可以获取TOP-N数据,这就是Window TOP-N查询,实现Window TOP-N查询也是通过Over开窗函数,其语法如下:
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER (
[PARTITION BY window_start,window_end,[,col_key1...]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]
) AS rownum
FROM table_name -- 该表是通过窗口表值函数TVF定义的窗口表
)
WHERE rownum <= N [AND conditions]SQL客户端
Flink SQL客户端提供了三种可视化结果模式:表格模式(Table Mode)、变更日志模式(Changelog Mode)、Tableau模式(Tableau Mode)。
表格模式(Table Mode)
表格模式会将结果用规则的分页表格可视化展示出来,进入Flink SQL客户端默认使用的就是这种模式,执行如下命令启用:
SET 'sql-client.execution.result-mode' = 'table';变更日志模式(Changelog Mode)
变更日志模式不会实体化和可视化结果,而是由插入(+)和撤销(-)组成持续查询产生的结果流,执行如下命令启用:
SET 'sql-client.execution.result-mode' = 'changelog';Tableau模式(Tableau Mode)
Tableau模式更接近传统的数据库,会将执行的结果以制表的形式直接展示在屏幕上,使用这种模式进行流式查询时,如果流是有限的数据集,那么Flink处理完所有数据之后会自动停止作业,同时屏幕上的打印结果也会相应停止;如果是无界流可以通过ctrl+c来终止屏幕上的输出。执行如下命令启动:
SET 'sql-client.execution.result-mode' = 'tableau';#设置表格模式并执行sql
Flink SQL> SET 'sql-client.execution.result-mode' = 'table';
Flink SQL> SELECT name, COUNT(*) AS cnt FROM (VALUES ('zs'), ('ls'), ('ww'), ('zs')) AS NameTable(name) GROUP BY name;
name cnt
——————————————————————————————
ls 1
ww 1
zs 2
#设置变更日志模式并执行sql
Flink SQL> SET 'sql-client.execution.result-mode' = 'changelog';
Flink SQL> SELECT name, COUNT(*) AS cnt FROM (VALUES ('zs'), ('ls'), ('ww'), ('zs')) AS NameTable(name) GROUP BY name;
op name cnt
———————————————
+I zs 1
+I ls 1
+I ww 1
-U zs 1
+U zs 2
#设置Tableau模式并执行sql
Flink SQL> SET 'sql-client.execution.result-mode' = 'tableau';
Flink SQL> SELECT name, COUNT(*) AS cnt FROM (VALUES ('zs'), ('ls'), ('ww'), ('zs')) AS NameTable(name) GROUP BY name;
+----+-----+----+
| op |name |cnt |
+----+-----+----+
| +I | zs | 1 |
| +I | ls | 1 |
| +I | ww | 1 |
| -U | zs | 1 |
| +U | zs | 2 |
+----+-----+----+Table Connector
Filesystem Connector
Filesystem Connector用于连接外部文件系统进行读取和写出操作。使用之前需要在项目中导入如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>Filesystem Connector使用方式如下:
CREATE TABLE MyUserTable (
column_name1 INT,
column_name2 STRING,
...
part_name1 INT,
part_name2 STRING
) PARTITIONED BY (part_name1, part_name2) WITH (
'connector' = 'filesystem', -- 必须项:指定connector
'path' = 'file:///path/to/whatever', -- 必须项:指定路径
'format' = '...', -- 必须项:执行文件格式
...
)Kafka Connector
Kafka Connector支持从Kafka topic中实时消费和写入数据。使用之前需要在项目中导入如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>Kafka Connector使用通用方式如下:
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)scan.startup.mode
该参数决定了Kafka consumer启动模式,可以配置如下几种方式:
1.group-offsets:默认值,从 Zookeeper/Kafka 中某个指定的消费组已提交的偏移量开始。
2.earliest-offset:从可能的最早偏移量开始。
3.latest-offset:从最末尾偏移量开始。
4.timestamp:从用户为每个 partition 指定的时间戳开始。
5.specific-offsets:从用户为每个 partition 指定的偏移量开始。sink.semantic
指定写出语义,需要设置checkpoint来保存状态,默认情况下该值为at-least-once语义。
Upsert Kafka Connector
Kafka Connector 作为Kafka Source时仅支持Append 方式追加写入数据,对于变更日志流不支持写入,这时就可以使用Upsert Kafka Connector解决这一问题。
Upsert kafka Connector支持以upsert的方式从Kafka topic中读取数据或者写出数据到Kafka topic。
使用UpsertKafka Connector需要在项目中导入如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>定义UpsertKafka Connector时需要指定一个Primay Key主键,该主键用来判断KafkaTopic中是否存在相同主键key数据,从而决定以INSERT/UPDATE/DELETE三种模式中的哪种模式读取或者写出数据,UpsertKafka Connector使用方式如下:
CREATE TABLE pageviews_per_region (
user_region STRING,
pv BIGINT,
uv BIGINT,
PRIMARY KEY (user_region) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'pageviews_per_region',
'properties.bootstrap.servers' = '...',
'key.format' = 'avro',
'value.format' = 'avro'
);JDBC Connector
JDBC Connector 允许使用JDBC驱动向任意类型的关系型数据库读取或者写入数据,例如:MySQL、Oracle、PostgreSQL、Derby、SQL Server。JDBC Connector可以作为Source或者Sink读写关系型数据库。使用JDBC Connector时,需要在项目中导入如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>${flink-connector-jdbc.version}</version>
</dependency>根据读取或者写出的关系型数据库不同还需要在项目中导入对应的数据库驱动依赖,这里以MySQL驱动为例,导入依赖如下:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>使用JDBC Connector的形式及使用方式如下:
-- 在 Flink SQL 中注册一张 MySQL 表 'users'
CREATE TABLE MyUserTable (
id BIGINT,
name STRING,
age INT,
status BOOLEAN,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mydatabase',
'table-name' = 'users'
);
-- 从另一张表 "T" 将数据写入到 JDBC 表中
INSERT INTO MyUserTableSELECT id, name, age, status FROM T;
-- 查看 JDBC 表中的数据
SELECT id, name, age, status FROM MyUserTable;
-- JDBC 表在时态表关联中作为维表
SELECT * FROM myTopic
LEFT JOIN MyUserTable FOR SYSTEM_TIME AS OF myTopic.proctime
ON myTopic.key = MyUserTable.id;HBase Connector
HBase Connector支持Flink向HBase读取或者写出数据。在Flink中使用HBase Connnector时需要导入对应依赖,目前Flink官方只针对HBase1.4.x和2.2.x版本提供了Connector支持,可以根据自己使用HBase版本导入对应依赖。
HBase 1.4.x对应的HBase Connector依赖包:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-1.4</artifactId>
<version>${flink.version}</version>
</dependency>HBase 2.2.x对应的HBase Connector依赖包:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-2.2</artifactId>
<version>${flink.version}</version>
</dependency>与JDBC Connector的使用方式类似,HBase Connector当作为Source时只能以有界流方式读取HBase数据,作为Sink时可以支持批量或者实时Append/upsert方式写出数据到Hbase中。使用HBase Connector的形式如下:
-- 在 Flink SQL 中注册 HBase 表 "mytable"
CREATE TABLE hTable (
rowkey INT,
family1 ROW<q1 INT>,
family2 ROW<q2 STRING, q3 BIGINT>,
family3 ROW<q4 DOUBLE, q5 BOOLEAN,q6 STRING>,
PRIMARY KEY (rowkey) NOT ENFORCED
) WITH (
'connector' = 'hbase-1.4',
'table-name' = 'mytable',
'zookeeper.quorum' = 'localhost:2181'
);
-- 用 ROW(...) 构造函数构造列簇,并往 HBase 表写数据。
-- 假设 "T" 的表结构是 [rowkey, f1q1, f2q2, f2q3, f3q4, f3q5, f3q6]
INSERT INTO hTable
SELECT rowkey, ROW(f1q1), ROW(f2q2, f2q3), ROW(f3q4, f3q5, f3q6) FROM T;
-- 从 HBase 表扫描数据
SELECT rowkey, family1.q1, family3.q4, family3.q6 FROM hTable;
-- temporal join HBase 表,将 HBase 表作为维表
SELECT * FROM myTopic
LEFT JOIN hTable FOR SYSTEM_TIME AS OF myTopic.proctime
ON myTopic.key = hTable.rowkey;在Flink SQL中通过DDL定义HBase Connector时需要指定主键key,主键只能基于HBase的rowkey字段定义,如上所示“rowkey INT”就是HBase中的主键,但在DDL中该列名称不一定叫rowkey,如果在DDL中没有声明主键key,HBase Connector默认也是获取rowkey作为主键。
所有HBase表的列族必须定义为ROW类型,字段名必须和HBase表中列族名称一样,ROW中嵌套的字段名对应列族中的列,在定义HBase Connector时,我们不需要将HBase表中所有列族及列都在Flink SQL中声明出来,只需要把用到的列族及列声明出来即可。除了Row类型的列,DDL中其他的字段将被识别为HBase的rowkey,一张表中只能定义一个rowkey。此外,HBase Connector也可以作为时态表与其他表进行关联。