
spark的sortBy算子是全局有序的。
其原理为先根据rangepartitioner 分区器,先实现分区间有序,再实现分区内有序。所有分区数据整合后即为全局有序数据。sortBy底层调用的是sortByKey,会引入shuffle操作。其原理梳理为两个步骤:
(1)对RDD数据抽取样本数据,将样本数据排序,计算出下游rdd每个分区的数据范围
(2)将上游rdd数据按照大小,发送到下游rdd符合数据范围的分区中
如此就实现了分区间有序。再各个分区内部再进行排序操作,即可实现全局有序。sortByKey原理:
对key采样,判断下一个RDD的每个分区对应的key范围,按照key发往对应的分区。保证分区间有序,在分区内再按照key进行排序,key相同的按照value排序。实现全局排序spark的union算子不去重!
reduceByKey 和 groupByKey 的区别?
从 shuffle 的角度:reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey 可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能
从功能的角度:reduceByKey 其实包含分组和聚合的功能。groupByKey 只能分组,不能聚合RDD 依赖之间的 shuffle
为什么要排序(sort)
1、key 存在 combiner 操作,排序之后方便合并
2、reduce task 是按 key 去处理数据的。不排序则每个key的计算逻辑都需要全表扫描数据。排序后方便进行reduce操作
3、排序后reduce task按照key的顺序进行读取。无需其他逻辑维护哪些key完成哪些key未完成。为什么要文件合并(combine)
1:过多的小文件会消耗集群资源
2:小文件过多,需要的maptask数就越多。给定固定core资源,需要跑多批task,影响程序运行效率
3:单个文件有序,不代表全局有序,小文件合并起来才能全局有序。海量数据的全局有序原理:
spark程序输出的文件数,取决于spark程序的最后一个stage的分区数。每个分区落盘为一个文件。
全局有序是通过分区间有序 + 分区内有序 实现。
即输出文件间的数据范围区间有序,每个输出文件内部数据有序。spark程序每个stage的并行度如何确定?
在Spark 中 我们知道会将一个任务划分为多个stage ,划分stage的依据就是是否为宽依赖(存在shuffle),每个stage 的并行度取决于一个stage 最后一个算子,因为一个任务的调用是从最后一个算子向前执行的.所以一个任务的task 数主要看一个stage最后的一个rdd的分区数。
spark运行时的reduce端分区数如何确定?
关于shuffle reduce的数量:
根据一些算子的定义是可以自己传入一个分区器分区器中定义了相关分区数的操作默认都是HashPartitoner 并且数量默认是:spark.default.parallelism (默认200)所以默认情况下这个参数会决定reduce端任务的并行度,这里如果没有配置这个参数的话则会以map端的partitions数一致
判断逻辑顺序如下:
1:算子手动传参指定reduce分区数
2:默认最大值200
3:与map端的分区数一致HashShuffleManager(未经优化)
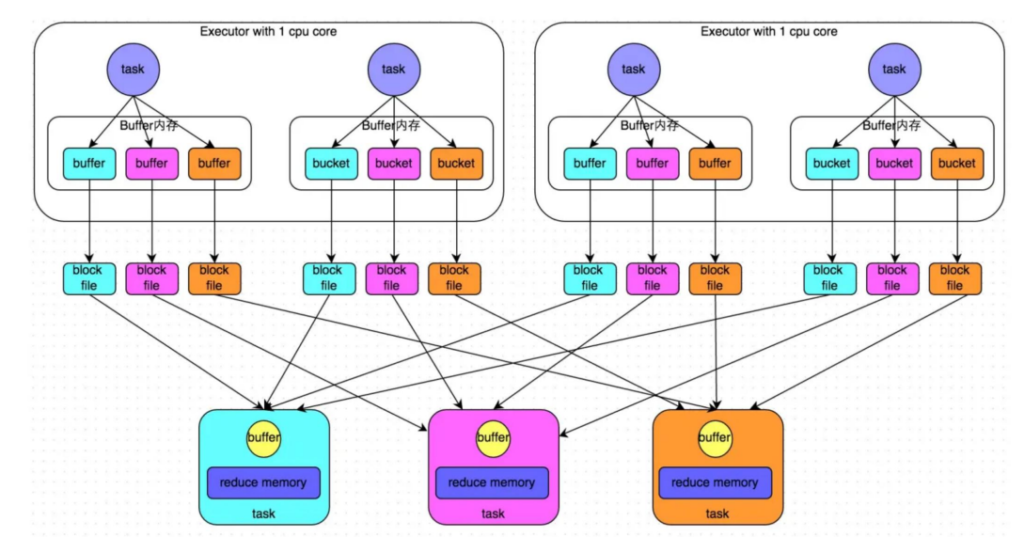
相比 MapReduce,排序不见了,文件合并不见了。
上游 task 写文件的时候只是将数据按分区追加到文件中,并没有像 MapReduce 那样先内存溢写成文件,然后再文件与文件之间进行合并,虽然节省了排序、合并的开销。
会产生大量的中间磁盘文件,进而由大量的磁盘 IO 操作影响了性能HashShuffleManager(优化后)
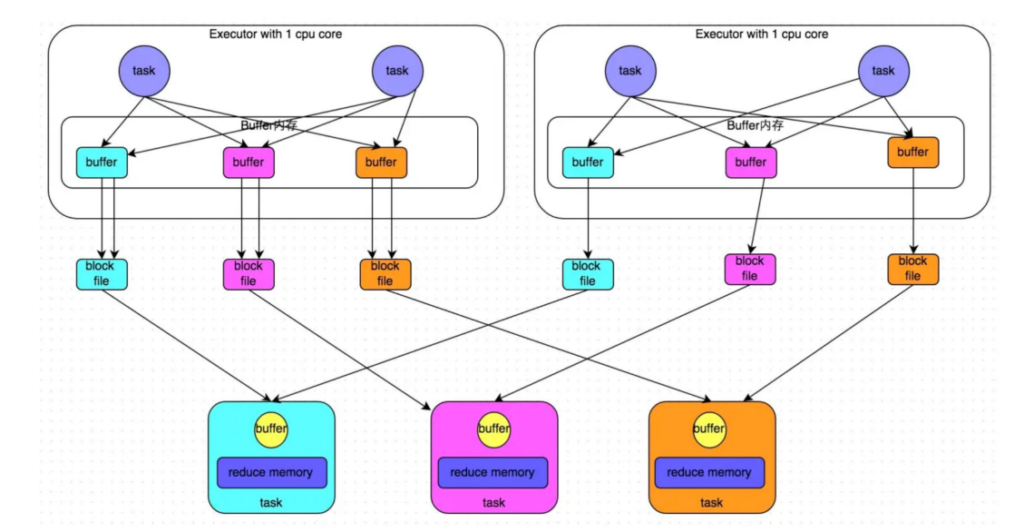
在一个 Executor 中的所有的 task 是可以共用一个 buffer 内存。
允许不同的task复用同一批磁盘文件,一定程度上进行聚合。但依旧不做排序操作。
此时的文件个数是 CPU core的数量 × 下一个 stage 的 task 数量。
适用于不需要排序的 shuffleSortShuffleManager
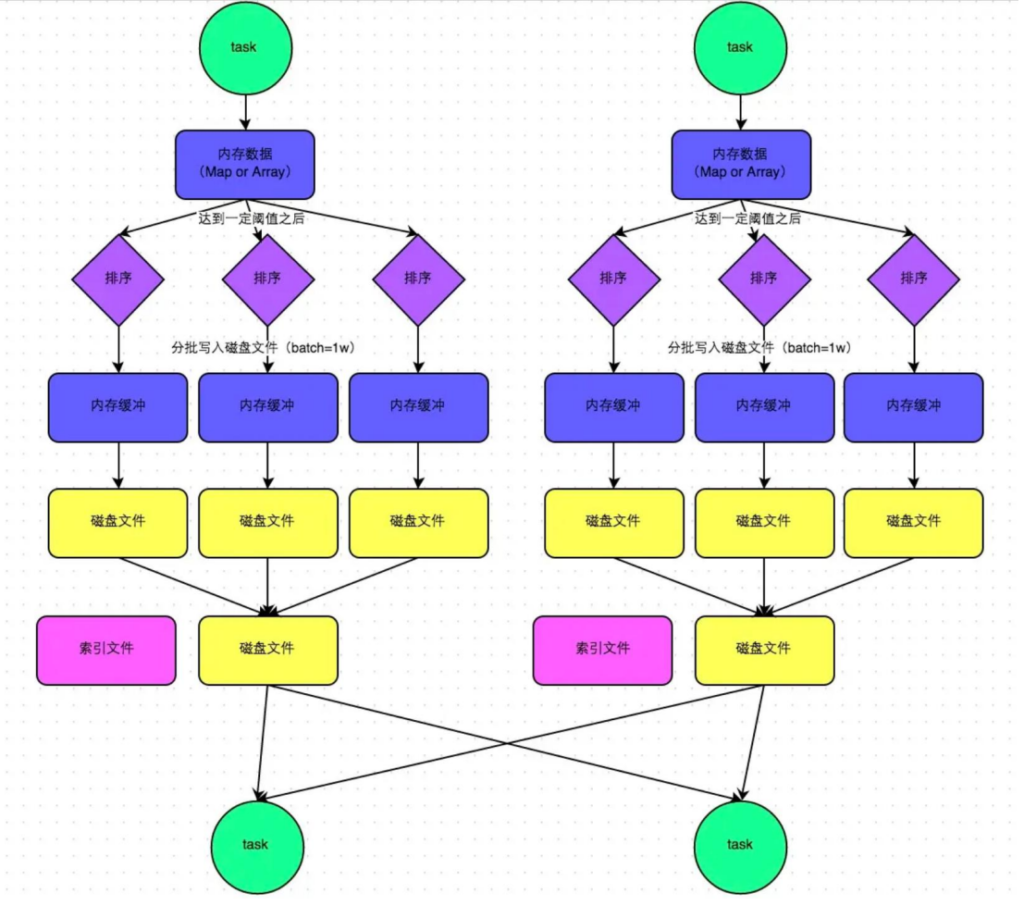
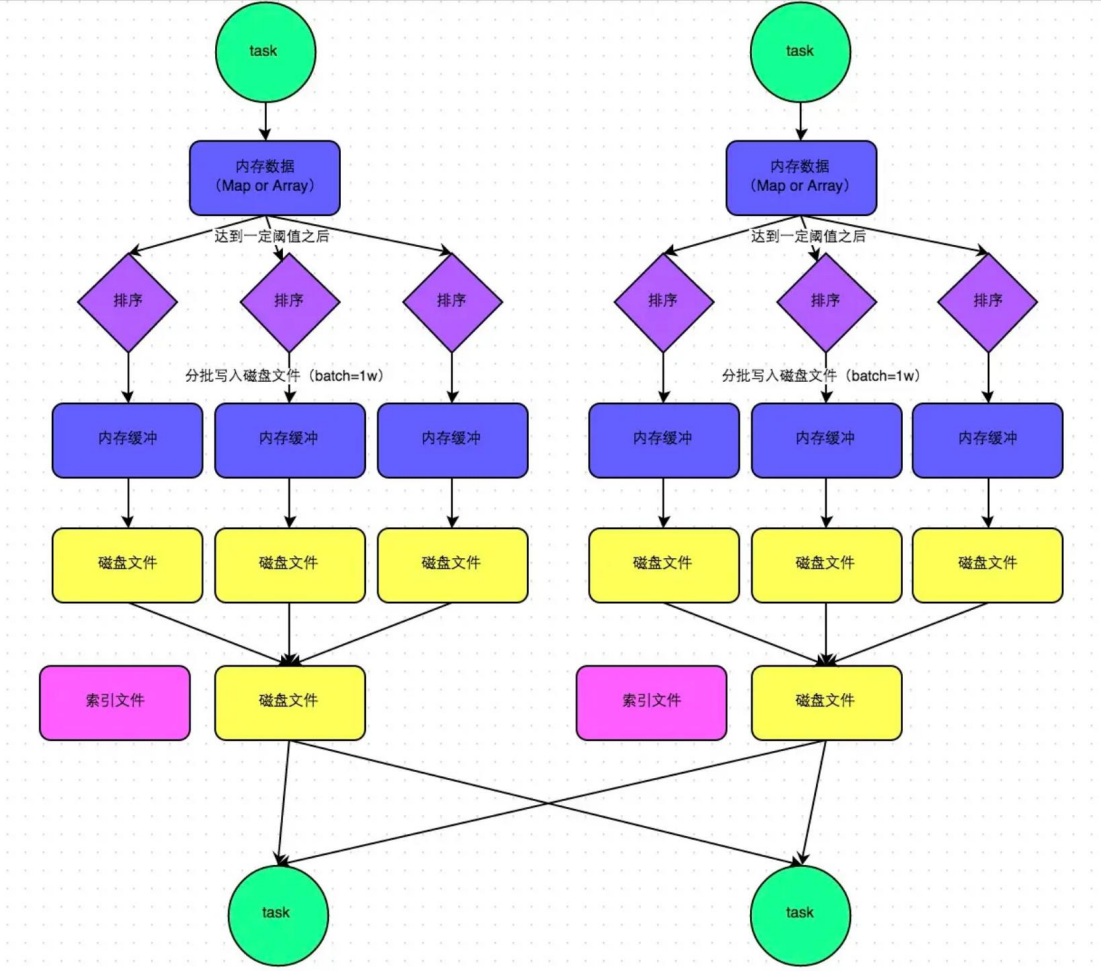
这种机制和 MapReduce 差不多,在该模式下,数据会先写入一个内存数据结构中。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
在溢写到磁盘文件之前,会先根据 key 对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。默认的 batch 数量是 10000 条,也就是说,排序好的数据,会以每批1 万条数据的形式分批写入磁盘文件。
一个 task 将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是 merge 过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。
此外,由于一个task 就只对应一个磁盘文件,也就意味着该 task 为下游 stage 的 task 准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个 task 的数据(排好序的数据)在文件中的 start offset 与 end offset。
SortShuffleManager 由于有一个磁盘文件 merge 的过程,因此大大减少了文件数量,由于每个 task 最终只有一个磁盘文件,所以文件个数等于上游 shuffle write 个数。SortShuffle 优化之 bypass 运行机制
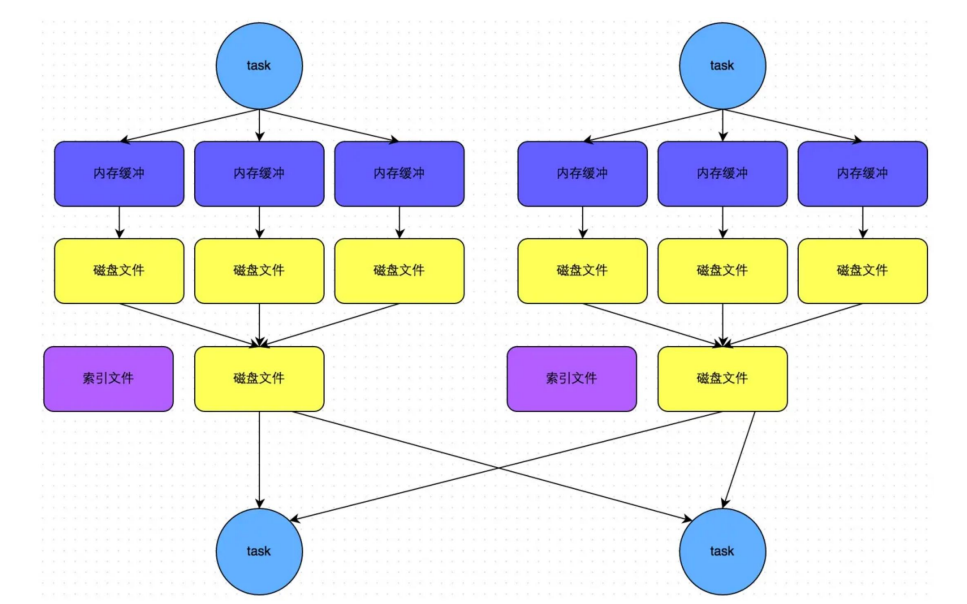
相比于sortshufflemanager 少了排序。
bypass 机制的目的是尽量减少不必要的数据重排和磁盘 IO 操作,该机制的最大好处在于,shuffle write 过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
适用于非集合类算子
因为聚合类的 shuffle 算子通常需要按照 key 进行排序和分区,以确保相同 key 的数据能够被正确聚合在一起。
如 groupByKey 这类虽然是 ByKey,但是没有聚合操作,所以可以通过设置
spark.shuffle.sort.bypassMergeThreshold 从而跳过排序操作为 什 么 Spark 放 弃 了 HashShuffle , 选 择 了 Sorted-Based Shuffle?
原因是 Spark 最根本最迫切要解决的是在 shuffle 过程中产生大量小文件的问题,spark shuffle 优于 MapReduce shuffle 的原因:
1、减少了磁盘 io
2、可选的 shuffle 和排序MapReduce的shuffle操作
maptask机制
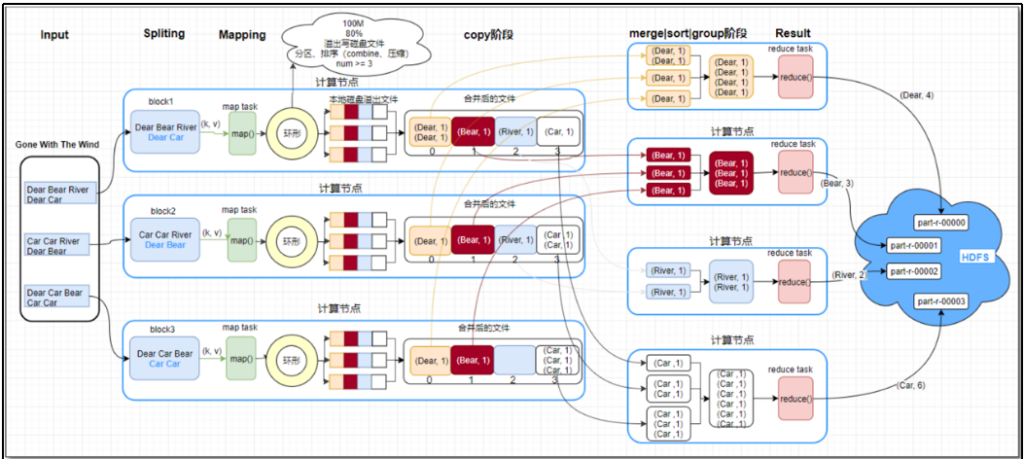
整体流程:
Read阶段—> Map阶段—> Collect阶段—> spill阶段—-> Combine阶段
1)Read阶段
MR程序提交到yarn集群运行,yarn会生成一个MrAppMaster(一个进程),用来控制maptask和reducetask的启动。因为分片信息已经提交到hdfs集群,那MrAppMaster就会去获取分片信息,计算出Maptask数量。MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
根据输入确定maptask数,maptask将inputsplit数据解析成key/value
2)Map阶段
该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
3)collect阶段
会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。环形缓冲区的默认大小是100M。
4)spill阶段
在环形缓冲区内对数据做排序。超出环形缓冲区占用80%时,溢写磁盘。写入磁盘时可以指定是否压缩及压压缩格式。如果指定了预聚合,在写入前进行合并操作。
溢写到磁盘后除了生成数据文件外,还会生成一个index索引文件。
环形缓冲区内的排序操作:
采用快速排序算法
先按照分区编号Partition进行排序,然后按照key进行排序。
5)combin阶段
当所有数据处理完后,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index。
合并时以分区为单位进行合并,并进行排序操作。合并后该大文件有序。mapreduce Shuffle工作机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle
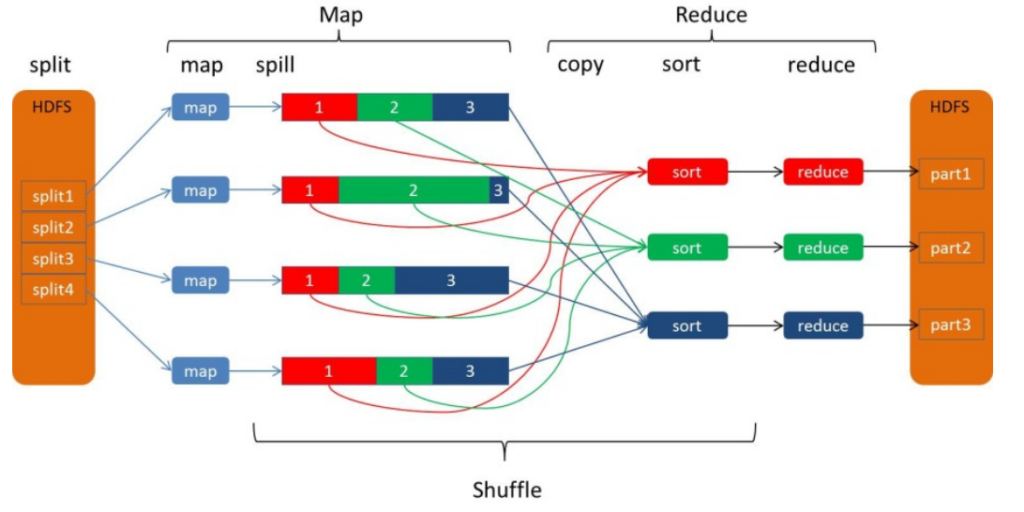
reduce拉取map端spill -> merge 后的磁盘文件作为reduce端的输入。
mergesort阶段: 一边copy一边sort。从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、排序等过程。最后一次合并的结果作为reduce的输入而不是写入到磁盘中。reduce个数的指定
